Gemini 3.5 Flash视觉能力超越Pro版,速度快6倍
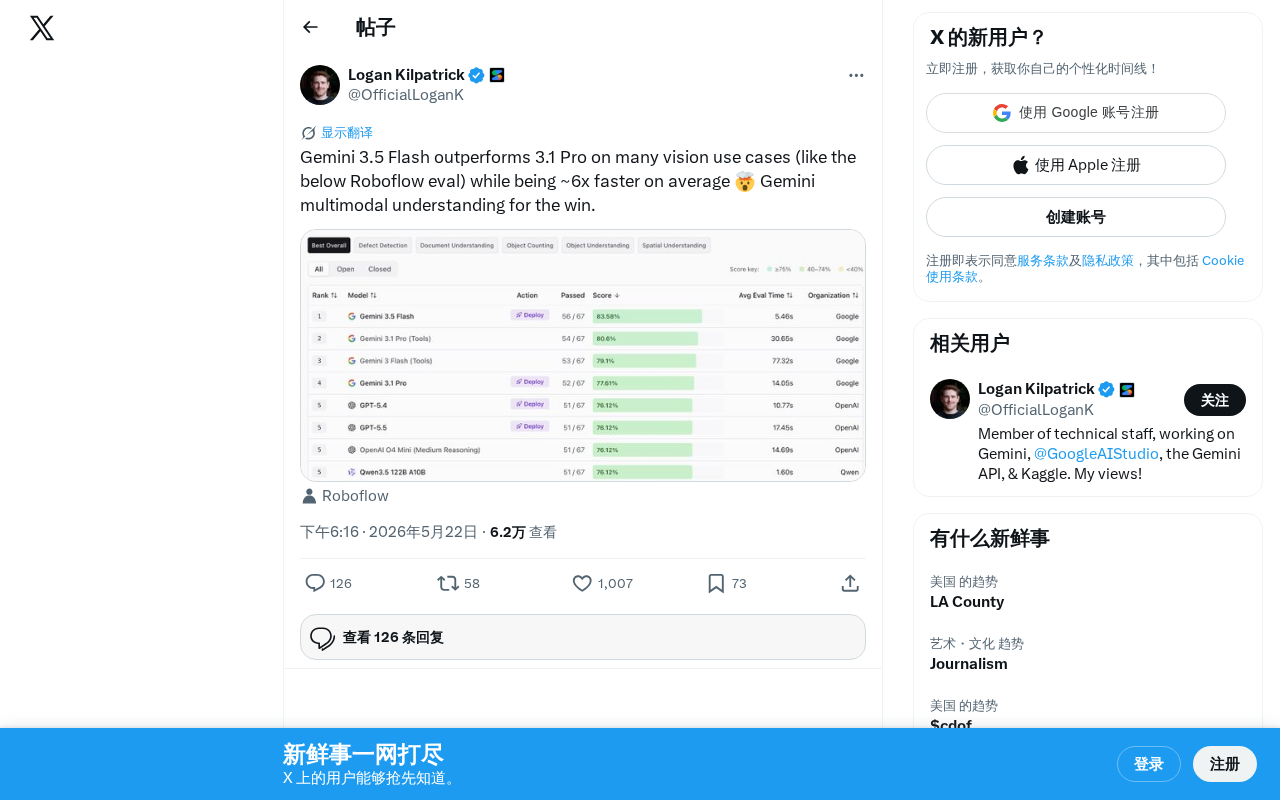
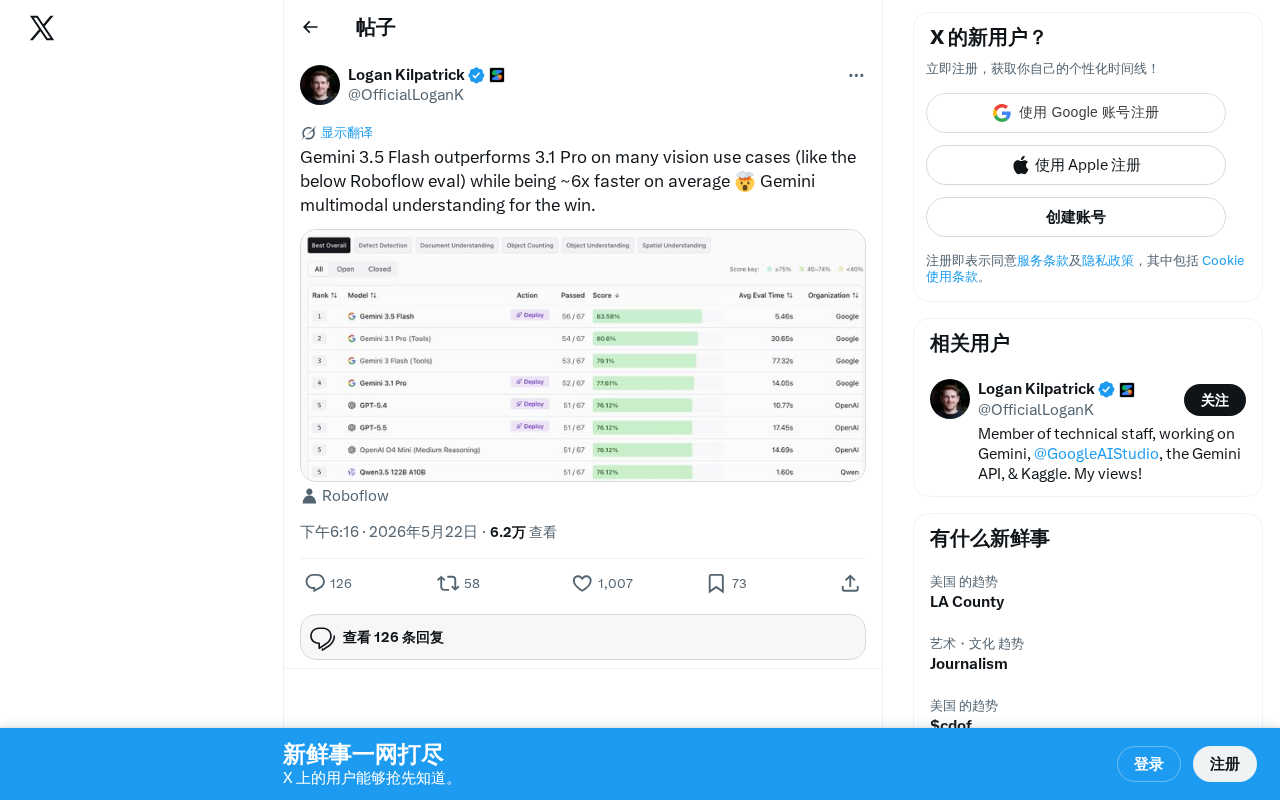
Gemini 3.5 Flash在视觉任务中超越上代旗舰Pro模型,速度快6倍
Google最新发布的Gemini 3.5 Flash轻量级模型在Roboflow视觉评测中超越了上一代旗舰模型Gemini 3.1 Pro,同时推理速度快约6倍,打破了"模型越大性能越强"的传统认知,实现了性能与速度的罕见双赢,为开发者提供了高性能低成本的视觉AI解决方案。
核心发现:Flash模型逆袭Pro
Google最新发布的Gemini 3.5 Flash在多项视觉理解任务中表现出色,根据Roboflow的评测数据,它在许多视觉用例上的表现竟然超越了上一代旗舰模型Gemini 3.1 Pro,同时平均推理速度快了约6倍。
这一结果令业界感到惊讶——通常来说,Flash(轻量级)模型在性能上会逊色于Pro(旗舰级)模型,但Gemini 3.5 Flash打破了这一惯例。要理解这一逆袭的意义,需要了解Google的Gemini模型家族采用分层命名策略:Ultra为最高性能版本,Pro为旗舰级平衡版本,Flash为轻量高速版本,Nano为端侧部署版本。这一分层逻辑类似于芯片行业的产品线划分,每一层级在参数规模、计算需求和推理延迟上都有显著差异。Flash模型通常通过知识蒸馏(Knowledge Distillation)从更大的教师模型中学习,以更少的参数实现接近大模型的能力,其设计目标是满足对延迟敏感、需要大规模并发调用的生产环境需求。因此,Flash超越Pro的结果格外引人注目。
多模态视觉理解的重大突破
视觉能力的跨代提升
Gemini 3.5 Flash在视觉任务上的表现尤为亮眼。Roboflow作为计算机视觉领域的知名平台,其评测具有较高的参考价值。Roboflow服务超过50万开发者,提供从数据标注、模型训练到部署的全流程工具链,其评测通常覆盖目标检测(Object Detection)、图像分类(Image Classification)、光学字符识别(OCR)、视觉问答(VQA)等多个维度,使用真实世界数据集而非合成基准,因此评测结果对实际应用场景具有较强的指导意义。
评测结果表明,3.5 Flash不仅在速度上有显著优势,在视觉理解的准确性上也实现了质的飞跃。这意味着Google在模型架构优化和训练策略上取得了重要进展,能够在更小的模型规模中压缩出更强的视觉理解能力。具体而言,这背后可能涉及多项关键技术突破:混合专家架构(Mixture of Experts, MoE)允许模型在推理时仅激活部分参数,大幅降低计算成本;改进的视觉编码器(如更高效的Vision Transformer变体)能够以更少的token表示图像信息;训练数据的质量提升和课程学习(Curriculum Learning)策略也能显著提高模型的数据效率。此外,Google在TPU硬件与软件协同优化方面的深厚积累,使得模型在推理阶段能够充分利用硬件并行性。
速度与性能的双赢
传统观念中,AI模型的性能与推理速度往往是此消彼长的关系——更大的模型意味着更强的能力但也意味着更慢的响应。然而Gemini 3.5 Flash实现了罕见的"双赢":
- 性能提升:在视觉理解任务上超越Gemini 3.1 Pro
- 速度优势:平均推理速度快约6倍
- 成本效益:Flash版本通常定价更低,适合大规模部署
推理速度提升6倍在工程实践中的意义远超数字本身:同等硬件资源下可服务6倍的并发请求,API调用的端到端延迟从秒级降至百毫秒级,使得实时视频分析、交互式文档处理等时延敏感场景成为可能。从成本角度看,更快的推理速度直接降低了每次API调用的GPU时间消耗,结合Flash版本本身更低的定价策略(通常为Pro版本的1/5至1/10),综合使用成本可能降低一个数量级以上。这对于需要处理海量图像的电商平台、安防系统和自动驾驶数据标注流水线尤为关键。
对行业的影响
开发者的实际应用价值
对于开发者和企业来说,这一结果意味着在构建视觉AI应用时,不再需要在性能和成本之间做艰难取舍。无论是文档理解、图像分析、视频处理还是多模态检索,Gemini 3.5 Flash都提供了一个极具性价比的选择。
多模态AI竞争格局变化
这也加剧了多模态AI领域的竞争。2024-2025年的多模态AI竞争已进入白热化阶段:OpenAI的GPT-4o实现了文本、图像、音频的原生多模态融合;Anthropic的Claude 3.5 Sonnet在文档理解和代码生成方面表现突出;Meta的Llama系列则在开源多模态领域持续发力。Google的差异化策略在于利用其搜索引擎积累的海量多模态数据优势,以及自研TPU芯片带来的训练效率优势。
Flash系列的成功表明,未来的竞争焦点正从"谁的模型最大"转向"谁能以最低成本交付最优性能",这一趋势将深刻影响AI基础设施的商业模式——云服务商需要重新思考定价策略,而应用开发者则获得了前所未有的成本灵活性。
总结
Gemini 3.5 Flash的表现证明了一个趋势:AI模型的进化不再只是简单地"越大越好",而是在效率、速度和性能之间找到更优的平衡点。这一趋势在学术界被称为"Scaling Efficiency"——即在固定计算预算下最大化模型能力,而非无限制地扩大模型规模。对于需要视觉AI能力的应用场景,Gemini 3.5 Flash无疑是当前最值得关注的选择之一。
核心要点
- Gemini 3.5 Flash在Roboflow视觉评测中超越了上一代旗舰模型Gemini 3.1 Pro
- 推理速度平均快约6倍,实现性能与速度的双赢
- Flash轻量级模型逆袭Pro旗舰模型,打破了传统的模型规模与性能正相关的认知
- 对开发者而言意味着视觉AI应用可以同时获得高性能和低成本
- 多模态理解能力的提升反映了Google在模型架构优化上的技术突破
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。