DeepSeek OCR2、Kimi K2.5、微软Maia 200同日发布
1月28日AI四大重磅:DeepSeek OCR2、Kimi K2.5、微软Maia 200芯片、阿里最强思考模型齐发
1月28日AI领域密集发布:DeepSeek OCR2用大语言模型替代CLIP作为视觉编码器,性能超越Gemini 3 Pro;Kimi K2.5推出集群代理模式,可调度100+子代理和1500个工具;微软3纳米制程Maia 200芯片开始部署,减少对英伟达依赖;阿里发布闭源旗舰Qwen3 Max Thinking。AI正从单点突破走向系统性生态构建。
1月28日,AI领域迎来多条重磅消息:DeepSeek发布视觉理解新模型OCR2,月之暗面正式推出Kimi K2.5,微软定制AI芯片Maia 200开始部署,阿里通义千问也发布了最强思考模型。本文对这些动态逐一解读。
DeepSeek OCR2:用大语言模型重构视觉编码器
DeepSeek发布了全新的OCR2模型,其最大的技术创新在于采用了一种名为Deep Encoder VR的编码器架构。与传统多模态模型普遍使用CLIP作为视觉编码器不同,OCR2大胆地用一个大语言模型(Qwen 2.5的小参数版本)替代了CLIP,赋予模型更强的视觉感知能力。
要理解这一创新的意义,需要先了解CLIP的技术背景。CLIP(Contrastive Language-Image Pre-training)是OpenAI于2021年提出的视觉-语言预训练模型,通过对比学习将图像和文本映射到同一语义空间。由于其强大的零样本迁移能力,CLIP迅速成为多模态大模型的标配视觉编码器,被LLaVA、InstructBLIP等主流模型广泛采用。然而CLIP本质上是一个判别式模型,在细粒度视觉理解(如文字识别、图表解析)上存在天花板,且其特征表示与语言模型的内部表示之间存在模态鸿沟,需要额外的投影层来弥合。DeepSeek OCR2用语言模型替代CLIP的思路,本质上是将视觉感知任务统一到语言模型的自回归框架下,消除模态鸿沟,使视觉特征天然与语言模型的表示空间对齐。

这一架构变革带来了实质性的性能提升。在OmniDocBench V1.5测试中,OCR2在使用与Gemini 3 Pro相同数量的token的情况下,取得了更高的性能表现。这意味着在保持图像压缩比和解码效率的同时,模型的理解能力得到了显著增强。
更值得关注的是,论文6.2小节中提到,Deep Encoder VR具有演变为通用多模态编码器的潜力。DeepSeek表示未来将继续探索更多模态的集成技术。由此可以推测,下一代或下下代的DeepSeek模型很可能会是一个原生多模态模型,覆盖文本、图像、音频甚至视频等多种模态。
Kimi K2.5正式发布:集群代理模式成最大亮点
月之暗面正式发布了Kimi K2.5模型。实际上,新模型早在前一晚就已悄悄推送给部分用户,1月28日正式官宣。
核心能力:百个子代理协同工作
K2.5的核心亮点是集群代理模式(Cluster Agent),该模式能够自主指挥多达100多个子代理,在1500个工具之间智能选择和调用。这种"一个主脑调度百个助手"的架构,使得Kimi在处理复杂任务时具备了前所未有的并行能力。
多代理系统(Multi-Agent System,MAS)是人工智能领域的经典研究方向,在大语言模型时代被重新激活并工程化落地。典型架构包括:主控代理(Orchestrator)负责任务分解与调度,子代理(Sub-agent)负责具体执行,各代理通过消息传递或共享内存协作。Kimi K2.5的集群代理模式将这一架构推向了新的规模——100+子代理并行运作意味着任务可以被高度并行化分解,理论上能将原本需要串行处理数小时的复杂工程任务压缩至分钟级完成。1500个工具的调用能力则覆盖了代码执行、网络搜索、文件操作、API调用等几乎所有软件工程场景。这种架构与AutoGen、CrewAI等开源多代理框架的设计理念一脉相承,但在规模和工程化程度上实现了质的飞跃。

在SWE(软件工程)测试中,K2.5达到了Gemini 3 Pro的水平,在多项基准测试和智能体评测中保持领先。
四种使用模式
目前K2.5提供四种使用模式:快速模式、思考模式、代理模式和集群代理模式。其中集群代理模式仅面向付费用户开放。Kimi网页版和APP均已正式可用,旧版K2模型也仍然保留供用户选择。
微软Maia 200定制AI芯片正式部署
微软正式推出了自研的AI加速芯片Maia 200,采用台积电3纳米制程工艺。据微软官方表示,该芯片在部分关键指标上达到了业界领先水平,并且已经开始在微软的数据中心进行部署使用。
这标志着微软在AI基础设施自主化方面迈出了重要一步。自研AI芯片的浪潮源于对英伟达GPU供应链的战略性焦虑——英伟达H100/H200系列GPU在AI训练和推理市场占据超过80%的份额,其高昂价格和供货紧张使云计算巨头承受巨大成本压力。谷歌早在2016年就推出了TPU(张量处理单元),目前已迭代至第五代;亚马逊AWS推出了Trainium和Inferentia系列;Meta开发了MTIA推理芯片。微软的Maia系列是这一趋势的延续——Maia 200采用台积电3纳米制程,代表了当前最先进的商业芯片制造工艺。自研芯片的核心优势在于:可针对自身AI工作负载(如Transformer推理的注意力计算、KV Cache管理)进行深度定制优化,同时通过垂直整合降低长期采购成本,并在地缘政治风险加剧的背景下构建供应链韧性。
阿里通义千问发布Qwen3 Max Thinking正式版
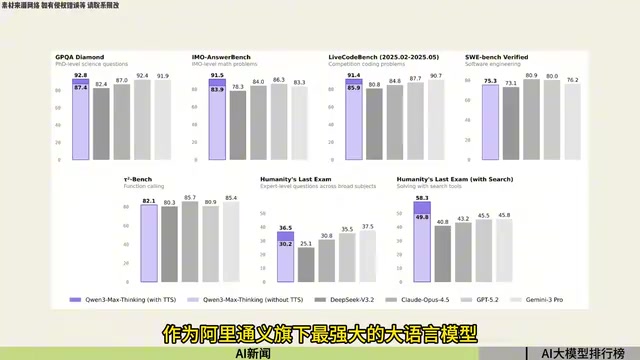
1月26日晚间,阿里通义发布了Qwen3 Max Thinking正式版模型。作为阿里通义旗下当前最强大的大语言模型,该模型在多项基准测试中取得了优秀成绩。
你可能没注意到,Qwen3 Max Thinking是一个闭源模型,目前可在千问网页端、桌面端以及QwenChat中体验使用,API也已同步开放。这与阿里此前大力推广开源模型的策略形成了精细化分层——阿里通义此前以开源策略著称,Qwen系列模型在Hugging Face上积累了大量用户和生态,开源模型承担生态建设和开发者心智占领的任务,而闭源旗舰模型则作为商业变现和技术护城河的核心资产,这与OpenAI(GPT-4闭源+开放API)的商业逻辑趋同。值得注意的是,"思考模型"(Thinking Model)特指具备显式推理链(Chain-of-Thought)能力的模型,通过在生成最终答案前进行内部"思考"步骤来提升复杂推理任务的准确率,OpenAI的o1/o3系列是这一范式的开创者。Qwen3 Max Thinking的发布表明,慢思考推理能力已成为顶级模型的标配竞争维度。
AI排行榜动态
从使用量排行来看,周一Sonnet 4.5迅速窜升至第一名,这种"周一冲顶"的规律已经持续了一段时间。在图像生成领域,Gemini占据绝对主导地位。唯一上榜的国产模型是Qwen3 VR,排名第九。AI大模型性能排行榜方面,近日暂无明显变化。
总结
本日的AI动态呈现出几个值得关注的趋势:一是视觉理解模型正在从依赖CLIP向更深度的语言模型驱动方向演进;二是智能体从单一代理向多代理集群协作的方向发展;三是科技巨头加速自研AI芯片以构建差异化竞争力。这些变化共同指向一个方向——AI正在从单点能力突破走向系统性的生态构建。
核心要点
- DeepSeek OCR2采用大语言模型替代CLIP作为视觉编码器,在OmniDocBench测试中以相同token数超越Gemini 3 Pro,并具备演变为通用多模态编码器的潜力
- Kimi K2.5正式发布,集群代理模式可调度100多个子代理和1500个工具,SWE测试达到Gemini 3 Pro水平
- 微软推出台积电3纳米制程的Maia 200自研AI芯片,已开始在数据中心部署,是云计算巨头摆脱英伟达依赖、构建供应链韧性的重要一步
- 阿里通义发布Qwen3 Max Thinking正式版闭源模型,为旗下当前最强大语言模型,标志着慢思考推理能力成为顶级模型标配
- AI行业正从单点能力突破走向多模态融合、多代理协作和自研芯片的系统性生态构建
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。