AI生成的Auth认证系统如何打磨到生产可用
AI写的代码为什么不能直接用
AI编程工具的普及让不少开发者尝到了甜头——几句提示词就能生成一套完整的注册登录系统。但现实往往没那么美好:生成的代码有报错、不符合项目规范、缺少国际化支持……这些问题不解决,AI生成的代码就只是一个"半成品"。
本文基于一位B站UP主的实战演示,记录了如何将Copilot生成的Auth认证系统从"能跑"打磨到"能用"的完整过程,重点关注代码报错修复和i18n国际化翻译件的替换。
GitHub Copilot是目前最主流的AI编程助手之一,基于大语言模型(主要使用OpenAI的Codex系列和GPT-4系列模型),通过分析当前文件内容、打开的标签页、项目结构等上下文信息来生成代码建议。它的Agent模式(Copilot Chat)允许开发者用自然语言描述需求,AI会自动读取相关文件、生成代码、甚至执行终端命令。值得注意的是,Agent模式与早期的行内代码补全(Inline Completion)有本质区别:行内补全只能基于当前光标位置的上下文预测下一段代码,而Agent模式具备"工具调用"(Tool Use)能力,可以主动搜索项目文件、读取目录结构、调用终端执行构建命令、甚至运行测试用例来验证自己生成的代码。这种从"被动补全"到"主动执行"的跃迁,使得AI能够处理跨文件的复杂任务,但也意味着它的操作范围更大,出错时的影响面也更广,开发者需要更审慎地审查其输出。但其本质仍是基于概率的文本生成,不具备真正的"理解"能力,因此对项目特定约定的遵循需要开发者通过明确指令来引导。
AI生成Auth代码的常见缺陷诊断
在上一期内容中,UP主已经让Copilot完成了注册登录功能的代码编写。Auth(Authentication & Authorization)认证系统是几乎所有Web应用的基础组件,涵盖用户注册、登录、密码重置、会话管理、Token刷新、权限控制等多个环节。一个生产级的Auth系统还需要考虑密码加密存储(如bcrypt)、防暴力破解(速率限制)、CSRF防护、XSS防护、JWT或Session的安全配置等。
从安全架构的角度看,Auth系统的防护是分层的:传输层需要HTTPS/TLS加密来防止中间人攻击;存储层要求密码经过加盐哈希(如bcrypt使用的Blowfish算法,通过可调节的cost factor控制计算复杂度,使暴力破解在算力上不可行);会话层需要合理设置Token过期时间、实现Refresh Token轮换机制(Refresh Token Rotation)以降低Token泄露的风险;应用层则需要实现RBAC(基于角色的访问控制)或ABAC(基于属性的访问控制)来管理细粒度权限。现代应用还常常集成OAuth 2.0和OpenID Connect(OIDC)协议来支持第三方登录,这些协议定义了授权码流程(Authorization Code Flow)、PKCE扩展等标准化的安全交互模式。AI生成的Auth代码往往能覆盖基本的功能流程——比如表单验证、API调用、Token存储——但在这些安全细节和项目特定的中间件集成方面容易出现疏漏,例如忘记设置HttpOnly和Secure标志的Cookie、未实现CSRF Token验证、或者在前端代码中暴露了敏感的密钥信息。
但打开项目后,问题立刻暴露出来。
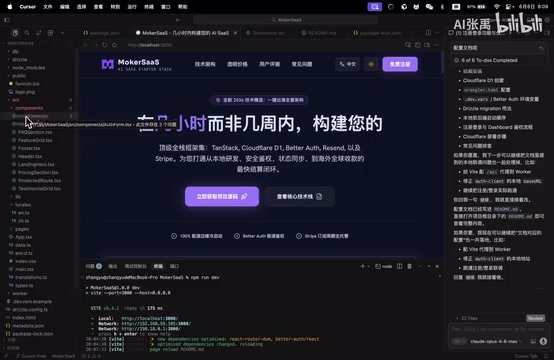
点击进入代码文件后,编辑器中存在多处报错。经过排查,核心问题集中在两个方面:
-
代码本身存在语法或逻辑错误:AI在生成较长代码段时,容易出现变量引用错误、类型不匹配等问题。这与AI的上下文窗口(Context Window)限制密切相关——上下文窗口决定了模型一次能"看到"多少信息,包括你的提示词、已有代码、项目结构等。从技术原理上说,上下文窗口的大小以Token为单位衡量(一个Token大约对应4个英文字符或1-2个中文字符)。GPT-4 Turbo的上下文窗口为128K Token,Claude 3.5为200K Token,但即使窗口足够大,模型对窗口中部信息的"注意力"也会衰减——这就是研究中发现的"Lost in the Middle"现象,即模型对上下文开头和结尾的信息处理更准确,而中间部分容易被忽略。为了缓解这一限制,Copilot等工具采用了RAG(检索增强生成)策略:不是把整个项目塞进上下文,而是根据当前任务智能检索最相关的代码片段、类型定义和配置文件,拼接成有限的上下文输入。但这种检索本身也可能遗漏关键信息,比如一个定义在项目深层目录中的工具函数或类型声明。当项目规模较大时,AI可能无法同时感知所有的架构约定、已有的工具函数和配置文件,导致生成的代码与项目现有规范不一致,甚至产生引用不存在的变量或函数的错误。
-
未使用翻译件(i18n):AI直接将中文或英文硬编码在代码中,而项目规范要求使用国际化翻译件来管理多语言文本
i18n是internationalization的缩写(因为i和n之间有18个字母),是软件工程中实现多语言支持的标准化方案。其核心思想是将用户界面中的所有可见文本从代码逻辑中分离出来,存放在独立的语言包文件(通常是JSON或YAML格式)中。代码中通过翻译函数(如t('login.title'))引用对应的键值,运行时根据用户选择的语言加载不同的语言包。这种架构使得添加新语言只需新增一个翻译文件,无需修改业务代码。常见的前端i18n库包括react-i18next、vue-i18n等。
在实际工程实践中,i18n的复杂度远不止简单的文本替换。翻译键的命名需要遵循层级化的命名规范(如module.page.component.element),以避免大型项目中的键名冲突和维护混乱。此外,不同语言的语法差异带来了额外的技术挑战:英语有单复数形式(1 item vs. 2 items),阿拉伯语有六种复数形式,中文则没有复数变化——i18n库通过ICU MessageFormat等标准来处理这些差异。除了界面文本,完整的本地化(L10n)还涉及日期格式(MM/DD/YYYY vs. YYYY-MM-DD)、货币符号、数字分隔符(1,000 vs. 1.000)、文本排版方向(LTR vs. RTL)等。在团队协作中,翻译工作通常通过Crowdin、Phrase、Lokalise等翻译管理平台进行,开发者导出翻译键,翻译人员在平台上完成翻译,再自动同步回代码仓库。
这是AI编程中非常典型的场景——AI能理解你要什么功能,但很难自动适配项目中已有的架构约定和技术规范。AI可能根本没有"看到"项目中已有的i18n配置和语言包文件,自然也就不会遵循这一约定。
用精准指令让AI自我纠错的修复过程
明确提出修改要求
发现问题后,UP主并没有手动逐行修改,而是继续借助AI的能力来完成修复。关键在于给出清晰、具体的指令:
让AI用翻译件的形式替换硬编码文本,同时检查功能是否存在报错并解决。
这条指令包含了两个明确的任务目标:一是规范化(使用i18n翻译件),二是质量保障(修复报错)。这种"一次指令解决多个问题"的方式,比逐个问题分开处理效率更高。
在AI编程协作中,提示词(Prompt)的质量直接决定输出质量。有效的编程提示词通常包含三个要素:明确的目标(做什么)、具体的约束(遵循什么规范)、以及期望的输出格式(代码结构如何组织)。例如"用翻译件替换硬编码文本"就比"优化代码"精准得多,因为它指定了具体的操作方式和目标状态。业界将这种针对AI编程工具的指令优化称为"开发者提示工程"(Developer Prompt Engineering),已成为现代开发者的核心技能之一。更进阶的做法是在项目根目录维护一个.github/copilot-instructions.md或.cursorrules文件,将团队的编码规范、技术栈约定、文件组织结构等信息持久化,让AI在每次交互时自动加载这些上下文,从而减少重复说明的成本。一些团队甚至会为不同类型的任务(如"新增页面"、"修复Bug"、"重构模块")准备标准化的提示词模板,形成团队级的AI协作规范。
AI阅读代码并执行翻译件替换
收到指令后,Copilot开始自动阅读现有代码,识别哪些地方使用了硬编码文本,然后逐一替换为翻译件的调用方式。
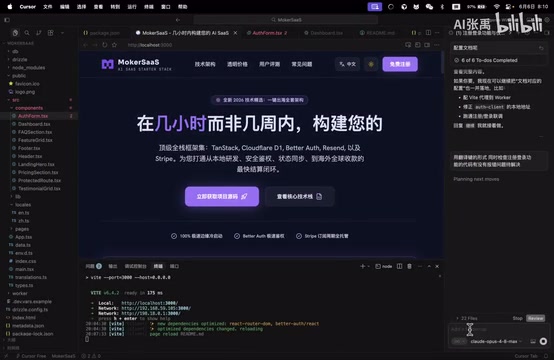
AI在这个过程中完成了以下几项工作:
- 遍历所有相关文件,找出硬编码的文本字符串
- 创建或更新翻译件文件,将中英文文本抽离到独立的语言包中(例如生成
zh-CN.json和en-US.json,包含如{"auth.login.title": "登录"}这样的键值对) - 替换代码中的引用,将直接写死的文字改为通过翻译函数调用(例如将
<h1>登录</h1>改为<h1>{t('auth.login.title')}</h1>) - 修复原有的报错,包括类型错误、引用缺失等问题
这个过程展示了AI编程工具在Agent模式下的核心能力——不仅能生成新代码,还能理解现有代码库的结构并进行批量重构。不过,需要认识到AI的这种"重构"能力与传统IDE(如VS Code、IntelliJ IDEA)内置的重构工具有本质区别。传统IDE的重构基于AST(抽象语法树)解析,能够精确地追踪变量的所有引用位置、理解作用域嵌套关系、保证重命名或提取操作的语义正确性——这是确定性的、100%准确的操作。而AI的重构本质上是基于模式匹配和概率推理:它通过"阅读"代码文本来推断哪些字符串是需要替换的UI文本、哪些是不应修改的技术标识符(如API路径、CSS类名、正则表达式等)。这种推理在大多数情况下是准确的,但在边界情况下可能出错——例如将一个恰好看起来像UI文本的配置常量也替换成了翻译函数调用,或者遗漏了动态拼接的字符串。因此,AI完成批量重构后,开发者仍需通过Git diff仔细审查每一处变更。
修复完成与功能验证
经过一轮自动化修改,AI完成了所有任务并给出了修改总结。
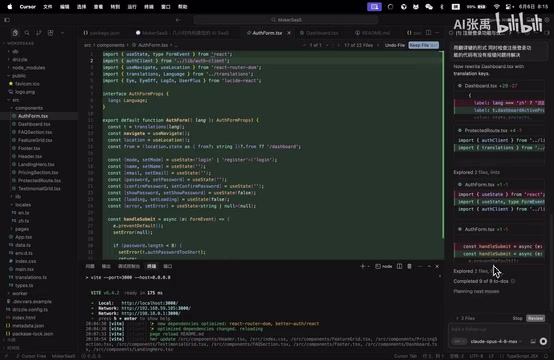
从总结中可以看到,AI不仅完成了翻译件的替换,还同步修复了之前存在的代码报错。接下来是最关键的验证环节——切换语言测试国际化是否生效。
实测结果:切换到英文界面显示正常,再切换回中文同样没有问题,翻译件工作正常,报错也全部消除。
与AI编程工具高效协作的实战经验
从这个案例中,可以提炼出几条与AI编程工具协作的实用经验:
不要盲目信任AI的首次输出。 无论是Copilot、Cursor还是其他AI编程工具,第一次生成的代码几乎必然需要调整。把AI当作一个"快速出初稿的初级开发者",而不是"一步到位的高级工程师"。根据多项行业调研,AI生成的代码在首次输出时的"直接可用率"通常在30%-60%之间,具体取决于任务复杂度和上下文信息的充分程度。
用精准的指令引导AI自我修复。 与其手动改代码,不如把问题描述清楚,让AI自己修。指令要具体——"用翻译件替换硬编码文本"比"优化一下代码"有效得多。好的指令应该包含:问题是什么、期望的解决方式是什么、需要遵循的约束条件是什么。
一次指令可以包含多个关联任务。 像本例中同时要求"替换翻译件+修复报错",AI能够理解这些任务之间的关联性,处理起来反而比分开执行更连贯。这是因为这些任务共享相同的代码上下文,AI在处理翻译件替换时自然会接触到报错的代码区域,顺手修复的成本远低于单独再跑一轮。
验证环节不可省略。 AI提示"已完成"不代表真的没问题,必须实际运行、切换场景测试,确认功能符合预期。特别是对于Auth这类涉及安全的模块,除了功能验证外,还应关注边界情况(如空密码、超长输入、并发请求等)的处理是否合理。在工程实践中,建议建立一套系统化的AI代码验证流程:首先通过ESLint/TSLint等静态分析工具检查语法和风格问题;其次让AI同步生成单元测试(或手动补充关键路径的测试用例),通过自动化测试覆盖核心逻辑;然后使用安全扫描工具(如Snyk、SonarQube、npm audit)检测已知漏洞和不安全的编码模式;最后进行人工Code Review,重点关注AI可能忽略的业务逻辑边界和安全隐患。将这套流程固化为CI/CD流水线的一部分,可以在不显著增加开发成本的前提下,大幅提升AI生成代码的可靠性。
结语:从AI生成到生产可用还差什么
AI编程工具正在快速进化,但"生成代码"和"生产可用的代码"之间仍然存在一道鸿沟。这道鸿沟需要开发者的经验和判断力来填补——知道哪里会出问题、知道项目规范是什么、知道如何给AI下达有效指令。
这道鸿沟的本质,是AI缺乏对"项目上下文"的完整理解。项目上下文不仅包括代码本身,还包括团队的编码规范、技术选型的历史原因、业务逻辑的隐含约束、以及部署环境的特殊要求。这些信息很难通过一条提示词完整传达给AI,需要开发者在多轮交互中逐步补充和校正。
拒绝半成品,不是拒绝AI,而是在AI的基础上多走一步,把代码打磨到真正可用的状态。这才是当下AI编程的正确打开方式。
核心要点
相关推荐
Python操作Excel实战:用Pandas实现数据自动筛选与分类
通过实际案例演示如何用Python Pandas库操作Excel,实现数据按年份和类型自动筛选分类,核心代码仅需6-8行,轻松处理海量数据,告别手动复制粘贴的低效操作。
AI写80%代码后开发岗位何去何从?Anthropic万字报告深度解读
Anthropic最新报告披露其代码库超80%由AI编写,工程师日均代码产出增长8倍。本文深度解读AI对软件开发、知识工作的冲击,分析品位护城河、AI泡沫阶段、循环工程等核心议题。
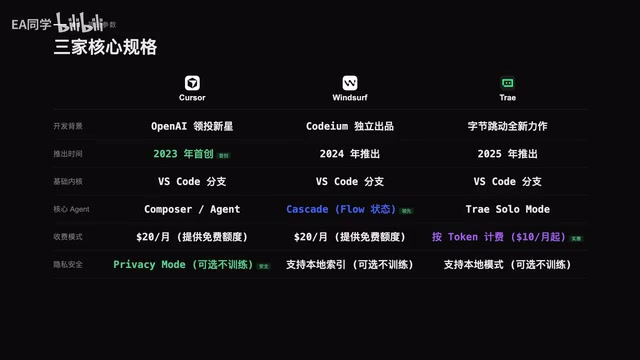
Cursor vs Windsurf vs Trae:三大AI IDE深度横评
从编程补全、Agent自主性、价格成本等五大维度全面对比Cursor、Windsurf、Trae三款主流AI IDE,附详细评分与选型建议,帮开发者找到最适合的AI编程工具。