AI写80%代码后开发岗位何去何从?Anthropic万字报告深度解读
Anthropic近期发布了一篇重磅长文《当AI开始构建自己》,披露了大量内部数据,揭示了AI对软件开发乃至整个知识工作领域的深刻冲击。作为全球估值最高的AI初创公司之一(估值达9000亿美元,一季度收入超过OpenAI),Anthropic的这份报告不仅是一次自我剖析,更是对整个行业的一次严肃预警。
Anthropic由前OpenAI研究副总裁Dario Amodei和Daniela Amodei兄妹于2021年创立,公司的核心理念是"AI安全优先"。其创始团队中有多位参与了GPT-2和GPT-3开发的核心研究员,他们因对OpenAI安全路线的分歧而出走。Anthropic提出了"Constitutional AI"(宪法AI)的训练方法,通过让AI根据一组预设原则进行自我批评和修正,减少对人工标注的依赖。公司获得了亚马逊、谷歌等科技巨头的巨额投资,其中亚马逊累计投资高达80亿美元。正是这样的技术底蕴和资本实力,使得这份报告的分量格外沉重。
AI已经在写绝大多数代码
报告中最令人震撼的数据是:截至2026年5月,Anthropic代码库中超过80%的合并代码由其AI产品Claude编写。而在2025年之前,这一比例还不足10%。要知道,Anthropic雇佣的都是硅谷顶级工程师,连这些人的日常工作都已被AI深度渗透。
这里需要理解"合并代码"的真正含义。在现代软件开发中,代码合并(Merge)是一个严格的流程:开发者在独立分支上编写代码,经过代码审查(Code Review)和自动化测试后,才能合并到主分支。因此,80%的合并代码由AI编写,不仅意味着AI在大量产出代码,更意味着AI写的代码质量已经达到了可以通过顶级工程师审查的标准——这才是真正令人震撼之处。
更值得关注的是效率跃升的幅度——2026年第二季度,一名典型工程师每天合并的代码量是2024年的8倍。正因如此,Anthropic已经不再以代码行数来衡量员工贡献,因为产出的暴增纯粹来自AI系统的加持,而非个人能力的提升。

这意味着一个根本性的转变:代码编写正在从人类核心技能变成AI的基础能力,工程师的价值锚点必须重新定义。
品位是最后的护城河还是下一个被攻克的堡垒
Anthropic在报告中指出,人类目前仍保有比较优势的领域是"研究品位和判断力"。借用爱迪生的名言——天才是1%的灵感加99%的汗水,而那99%的汗水正在被越来越多地自动化。
过去一年,"品位"(taste)成为AI编程和AI创业圈的高频词。在软件开发中,品位意味着需求评审、方案论证、技术选型等前期决策能力;在内容创作领域,创意能力和审美判断已经远比传统的剪辑后期技术重要。
然而,报告末尾Anthropic自己也坦承:"所谓各个领域的研究品位,可能只是又一项AI能力。"这句话值得反复品味。当下一代AI产品已经展现出超越99%人类的提问能力和审美水平时,我们曾经以为的"最后堡垒"可能比想象中更脆弱。
这也引发了一个教育层面的深层思考:如果AI的审美和创意能力持续进化,我们到底该如何培养下一代?过去的共识是"知识不重要,提问和审美才重要",但如果连这些也被AI超越,那基础知识的扎实积累反而可能重新变得关键——因为没有深厚的知识底座,一个人根本无法对好问题产生深刻洞察。
人工审查反成新瓶颈
Anthropic报告中指出了一个颇具讽刺意味的场景:当大部分人类成员完全停止写代码、转而只做审查时,如果他们审查代码的速度跟不上Claude生成代码的速度,人工审查反而会成为AI开发的新瓶颈。
有人可能会想,"审查AI的工作"会不会成为一个新的职业方向?但这条路也没那么乐观。Anthropic今年4月已经在研究"一个较弱的模型能否可靠地监督一个更强的模型"。这个问题在AI安全领域被称为"可扩展监督"(Scalable Oversight),是当前对齐研究的核心难题之一。从逻辑上讲,如果人类的能力值是5,顶级AI的能力值是500,那么在二者之间一定存在一个空间,让弱一些的AI模型发挥监督作用。
无论如何,未来能全线参与AI审查的人,一定是在相应知识领域极其丰富的少数人。这不是一个大众化的就业出口。
Claude 3.5与Mathos的实际表现
在社会科学领域,相比国内模型,Claude 3.5每千字输出能多出一两个具备深度洞察的观点,有超越基础信息整理的思辨感和智慧感(不过国产模型在文笔和文字氛围感上仍保持领先)。
在编程应用领域,Claude 3.5在架构设计、超长代码任务、复杂debug上是"断层碾压级"的存在,这是业内比较公认的评价。

一个令人震撼的案例是:猎豹CEO傅盛在模型发布当天,通过简单的自然语言需求,让AI用一晚上做出了一款完整的《红色警戒2》风格RTS游戏——包括地形渲染、战争迷雾、AI智能对手策略,甚至支持多人联机。虽然画面更像红警1,单位和地形也简化了很多,但采资源、暴兵、推基地的核心玩法完全可玩。AI甚至为了规避版权风险,对全部建筑和移动单位做了重新设计。这个案例的意义在于,RTS游戏是公认的最复杂游戏类型之一,涉及实时路径规划、资源管理系统、AI决策树、网络同步等多个高难度技术模块,过去需要专业团队数月甚至数年才能完成。
而Anthropic最强的Mathos模型至今仍未向C端开放,其真实能力仍是一个悬念。
AI泡沫到了哪个阶段
关于AI泡沫的讨论从未停止,但从多个维度来看,当前远未到泡沫后期。
模型能力仍在快速增长。 多位顶级工程师在播客中表达的主流观点是:大模型缩放定律(Scaling Law)按保守估计还能强势维持一年以上。Scaling Law最早由OpenAI在2020年的论文中系统阐述,其核心发现是:大语言模型的性能与模型参数量、训练数据量、计算量之间存在幂律关系——只要持续增加这三个要素中的任何一个,模型能力就会可预测地提升。近年来,研究者还发现了"推理时缩放"(Inference-time Scaling),即在模型推理阶段投入更多计算资源(如让模型"思考更久"),也能显著提升输出质量,这就是OpenAI o1系列和Claude思考模式背后的核心思路。从预训练堆算力到推理阶段的突破,S增长曲线还没有到平台期。
财务数据远比互联网泡沫健康。 Anthropic去年底年化经常性收入(ARR)才90亿美元,今年5月已达470亿美元。ARR是SaaS和订阅制企业最核心的财务指标,这种在约5个月内实现超过400%的增长,在企业软件历史上几乎前所未有——作为对比,Salesforce达到类似收入规模用了近20年。美国五大云厂商虽在加码AI算力资本开支,但整体负债比例仅40%,远低于2000年互联网泡沫时124%的水平。2000年互联网泡沫是科技史上最著名的投机狂潮之一,当时大量互联网公司在没有盈利甚至没有收入的情况下获得天价估值,纳斯达克指数从峰值暴跌78%。AI主线标的前瞻市盈率24倍,也远低于当年互联网泡沫高点的54倍。当下美国市值前10的公司全部超过1万亿美金,已无一家传统公司,且盈利能力都非常强。

渗透率仍处于初期。 Anthropic目前的主要客户仅覆盖三大类:硅谷互联网企业、美国头部金融公司、生物制药公司,向千行百业的渗透才刚刚开始。全球广义办公室白领有13亿人,付费使用Office套件的企业账号就有4.5亿,但多数行业尚未将AI嵌入工作流。这意味着AI的商业化天花板远未触及,当前的收入增长更多来自早期采用者,而非市场饱和后的存量竞争。
循环工程:从逐轮指挥到自主闭环
硅谷近期热议的一个新概念是"Loop Engineering"(循环工程)。这个概念类似于卡牌游戏中的"循环构筑"——前期你需要精确计算、手动打牌,但当循环体系搭建完成后,系统就能自主闭环运转。
未来AI领域理想的Loop是:不再需要手动写提示词,不再是你说一句AI回一句,也不再需要每完成一个阶段就人工检查一次。人类追求的终极目标是设计一套自主闭环运转的系统,然后让AI自己循环着开发自己。
Anthropic的预测是:只要给予充足的算力,最终会出现一个能够完全自主设计和开发自己下一代的AI系统——这就是所谓的**"递归自我改进"**(Recursive Self-Improvement)。这一概念最早由数学家I.J. Good在1965年提出的"智能爆炸"假说中描述:如果一个AI系统足够智能,能够理解并改进自身的设计,那么改进后的版本将更擅长进一步改进自己,形成正反馈循环。这一过程可能导致能力的指数级增长,远超人类的理解和控制能力。这也是为什么Anthropic等公司将AI安全研究视为核心使命——一旦递归自我改进启动,人类可能只有极短的窗口期来确保系统的行为与人类价值观对齐。而它到来的速度,可能远超大多数机构的预期和准备。
如果模型再以当前速度进化一年半,AI即便不是"神",也将是"半神"级别的存在。而以这个速率增长三到五年,AGI的到来或许并非天方夜谭。
写在最后
这篇Anthropic的万字长文,与其说是技术报告,不如说是一封写给全行业的预警信。当AI开始构建自己,当80%的代码由机器编写,当"品位"可能也只是AI的又一项能力时,我们需要重新审视的不仅是职业规划,还有教育理念、商业模式,乃至对人类价值的根本认知。
唯一确定的是:这场变革的速度,大概率会超出我们的准备。
相关推荐

DeepSeek组建Harness团队:AI编程竞争进入下半场
DeepSeek正式组建Harness专项团队,对标Claude Code打造国产自研Code Harness。深度解析四层闭环架构、三大核心底牌及40倍成本优势,揭示AI竞争从模型内卷转向工程落地的行业拐点。
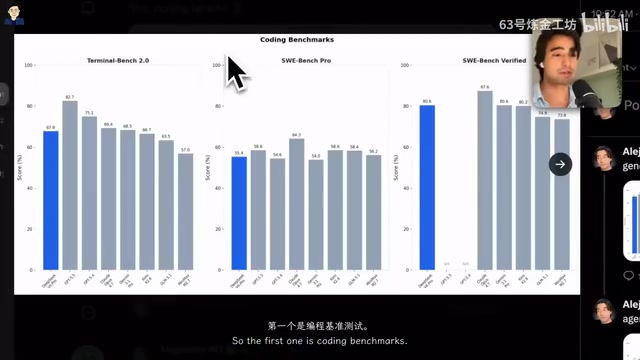
DeepSeek V4 Pro深度评测:性能媲美GPT-5.5,成本仅1/12
全面评测DeepSeek V4 Pro在编程、推理、Agent能力等基准测试中的表现,对比GPT 5.5和Claude Opus定价优势,并通过Pi Agent实战演示其编码能力。开源模型性价比之王。
Vibe Coding实战:用AI工作流从零搭建出海项目
分享一套经过半年验证的AI开发工作流,涵盖Claude Code计划模式、文档管理、版本控制、Cloudflare部署等实战环节,帮助非程序员用管人的方式管理AI,高效完成技术出海项目开发。