合成数据是解药还是毒药?AI训练数据枯竭的破局之道

互联网数据见顶,合成数据成为大模型训练新路径但面临模型崩溃风险
大模型训练依赖的互联网公开数据已接近枯竭,Scaling Law面临瓶颈。合成数据(用AI生成数据训练AI)成为应对方案,在自动驾驶、医疗等领域已有成熟实践,且具有可预测的优化规律。但研究发现合成数据的迭代反馈循环会导致模型崩溃——生成内容逐代退化、多样性丧失,即使极低比例的合成数据污染也会引发可测量的退化。
互联网数据见顶:大模型的「粮食危机」
你有没有想过,现在的大模型训练数据从哪来?简单说,就是把整个互联网上能爬到的公开文本——维基百科、书籍、新闻报道、论文、论坛帖子、代码仓库、博客评论——全部喂给模型,让它从中学习人类语言。
有人算过,GPT-4级别的模型训练数据大概在几十TB量级,这差不多是把你能想象到的所有公开文本全都吃了一遍。但问题来了:互联网不是无限的,人类历史上生产的所有文本有一个上限,而且这个上限已经不远了。
OpenAI的前首席科学家Ilya Sutskever在2024年底的NeurIPS大会上说了一句让整个行业震动的话:
我们已经达到了数据的峰值,未来不会再有更多数据。我们必须利用现有的数据,因为互联网只有一个。
这句话的潜台词是:靠多爬数据来提升模型,这条路快走到头了。
过去大模型的提升很大程度靠Scaling Law(规模法则):模型参数越大 + 训练数据越多 = 模型能力越强。这个法则在2018到2024年间几乎像铁律一样准确。
Scaling Law最早由OpenAI研究员在2020年的论文《Scaling Laws for Neural Language Models》中系统性地提出和量化。该研究发现,语言模型的性能与模型参数量、训练数据量、计算量之间存在幂律关系——三者同步增大时,模型能力以可预测的速率提升。这一发现彻底改变了AI研究的方向:与其在架构上精雕细琢,不如直接堆算力和数据。2022年DeepMind发布的Chinchilla论文进一步修正了这一法则,指出此前的大模型普遍「数据喂养不足」,最优训练应让数据量与参数量保持约20:1的比例。然而Scaling Law本质上是一条经验曲线,它描述的是「在数据充足前提下」的规律,一旦数据供给成为瓶颈,这条曲线就会提前触顶。
到2025年左右,问题开始浮现:
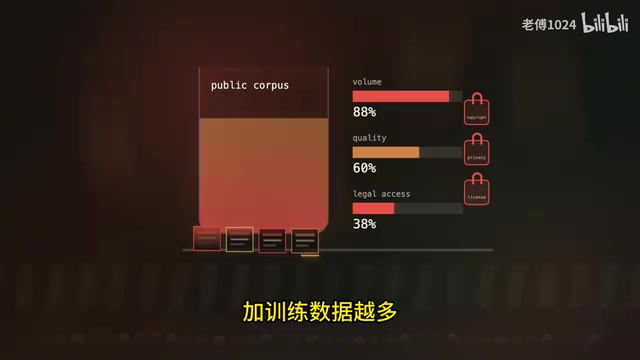
- 量不够了:Reddit帖子爬完了,GitHub公开代码仓库也爬完了,学术论文、维基百科增长速度远跟不上模型训练的胃口
- 质量参差不齐:低质量内容越来越多,高质量语料增量有限
- 合法获取越来越难:纽约时报的付费文章、医疗隐私数据,版权和隐私法规限制日益收紧
数据枯竭是三位一体的困境,而这正是合成数据登场的背景。
合成数据是什么:用AI生成的数据训练AI
合成数据的基本思路很直接:既然真实数据不够,我能不能自己造?
比如,我需要训练模型在多轮对话中更自然地回应用户追问。我可以让一个模型扮演老师,另一个模型扮演学生,让它们自己互相对话——老师先给一个场景,学生回应,老师再根据回应打分、给出改进建议。几十万轮下来,我就有了几十万条高质量的对话训练样本。
再比如,训练模型识别医疗影像中的罕见病变,但罕见病的真实影像本来就没几张,还涉及患者隐私。这时可以用生成模型合成统计上与真实分布高度相似的新影像,用来训练模型。
事实上,合成数据并非大语言模型训练的专属概念,它在多个AI子领域已有成熟实践。在自动驾驶领域,Waymo和特斯拉大量使用仿真引擎生成极端天气、罕见事故场景的合成驾驶数据,因为真实世界中这类数据极难收集且存在安全风险。在医疗AI领域,GAN(生成对抗网络)和扩散模型被用于合成医学影像,美国FDA已于2023年发布专项指南,认可合成医疗数据在特定条件下的监管有效性。这些领域的共同经验是:合成数据在「长尾场景补充」和「隐私敏感场景替代」两个维度上价值最高,而非作为主体数据源。
合成数据不是随便造一堆数字垃圾,而是尽量准确地复现真实数据的统计结构、分布比例、边界条件和长尾场景。
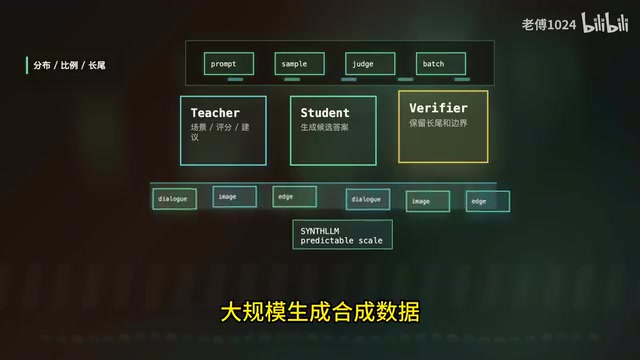
微软亚洲研究院做过一个叫SynthLM的框架,专门研究怎么用预训练语料大规模生成合成数据。他们的结论是:合成数据具有可预测性——你可以通过规模法则合理地选择模型规模和合成数据量来最大化性能提升。换句话说,合成数据不是瞎蒙着用,而是在数学上可以被建模、被预测、被优化的。
最大的坑:合成数据导致模型崩溃
但这里有一个非常大的陷阱。2024到2026年间,大量研究发现了一个让人担忧的现象——合成数据的反馈循环会导致模型崩溃。
什么叫模型崩溃?假设你有一个基础模型M0,用M0生成一批合成数据训练下一代模型M1,M1又生成合成数据训练M2,M2再生成数据训练M3……到了M3或M4这一代,你会发现模型的生成内容在退化:
- 词汇越来越单一
- 句子结构越来越趋向于几个高频模式
- 长尾内容(那些少见但重要的表达、风格、观点)消失了
- 模型开始输出统计上的「均质化」内容
像一个慢慢褪色的照片,越来越糊,越来越同质。
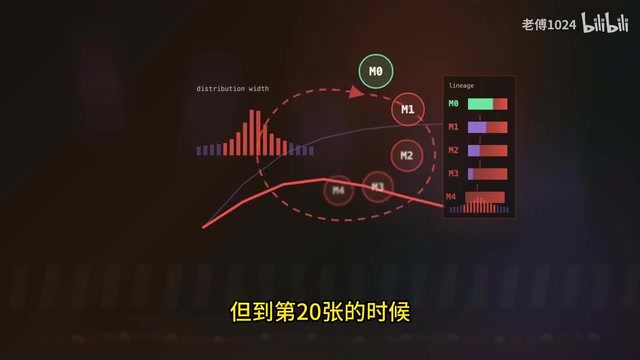
模型崩溃在信息论层面有清晰的解释。每次用模型生成合成数据,本质上是对原始数据分布做了一次「有损压缩」——模型只能学到训练数据中统计显著的模式,低频但真实存在的分布尾部会被截断。当这份被截断的分布再次成为下一代模型的训练数据时,尾部进一步收窄,形成正反馈的退化循环。从KL散度(Kullback-Leibler Divergence)的角度看,每一代合成数据与真实分布之间的散度都在单调递增,且这种误差会在迭代中累积而非平均。
有一篇发表在Nature上的里程碑式研究(Shumailov et al., 2024)证实了这一点:即使微小比例的合成数据污染(低至千分之一的训练样本),也能引发词汇、句法和语义多样性的可测量退化。也就是说,即便你99.9%的训练数据都是真实数据,只有0.1%是合成数据,在多次迭代之后
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。