Continual Harness:AI自动构建脚手架通关宝可梦RPG

AI自动构建优化自身工具链,无需人工干预即可通关多款宝可梦RPG
普林斯顿与谷歌DeepMind提出Continual Harness框架,让具身智能体从最基础的环境接口出发,在不重置、不依赖人工干预的情况下,自动构建和优化脚手架(系统提示词、子智能体、技能库、记忆库)。该框架驱动AI首次通关多款宝可梦RPG,效率接近人工设计的专家系统且成本降低约40%,但存在模型能力门槛,弱模型反而表现更差。
引言:当AI开始改造自己的工具链
普林斯顿大学与谷歌DeepMind联合发布了一篇重磅论文,提出了面向具身智能体的持续自我改进框架——Continual Harness。这项研究的核心成果相当亮眼:AI不再依赖人工设计的脚手架(Scaffolding),而是在游戏过程中自动构建、优化自己的工具和策略,最终成功通关多款宝可梦RPG游戏。
这不仅是游戏AI领域的突破,更是通用具身智能发展路上的重要里程碑。它回答了一个关键问题:AI能否从最基础的环境接口出发,在不重置、不依赖人工干预的情况下,持续提升自己的能力?
为什么具身智能需要Continual Harness
在代码领域,基于大模型的智能体已经有了成熟的Harness框架,比如Claude Code、Open Hands等工具,能让模型调用各类工具、保存跨交互的状态,完成复杂的编码任务。但在具身智能领域——即需要与物理或虚拟环境持续交互的场景——还没有对应的通用方案。
具身智能(Embodied Intelligence)是指AI系统不仅进行抽象推理,还需要在物理或虚拟环境中通过感知和动作持续交互来完成任务。与纯文本对话不同,具身智能体面临的核心挑战是:环境状态会因自身动作而改变,决策必须考虑时序依赖和长期后果。而脚手架(Scaffolding)在软件工程中原指临时性的辅助代码结构,在AI领域则演变为围绕大模型构建的工具层和提示层——它为模型提供结构化的输入输出接口、工具调用能力、记忆管理和任务分解机制,使模型能够处理远超单次推理能力的复杂任务。
此前的PokeAgent挑战已经证明:如果没有领域定制的脚手架,即使是前沿的多模态大模型,在宝可梦这类RPG游戏里几乎无法取得任何进展。宝可梦RPG之所以成为具身智能的理想测试平台,是因为它融合了多种认知挑战:空间导航(在复杂地图中寻路)、策略决策(属性克制的回合制战斗)、长期规划(队伍培养和资源管理)、以及自然语言理解(NPC对话和任务线索)。PokeAgent挑战揭示了一个残酷现实:即使是GPT-4V、Gemini等顶级多模态模型,在没有专门设计的辅助框架时,往往连最基本的城镇导航都无法完成,更不用说通关整个游戏。这正是Continual Harness要解决的核心痛点。

Gemini Plays Pokemon:从人工迭代到自动进化
项目演进历程
Gemini Plays Pokemon(GPP)项目最早采用人类在环(Human-in-the-loop)的方式优化Harness。Human-in-the-loop是一种人机协作范式,人类专家在AI系统运行过程中持续监控、纠正和引导模型行为。在GPP项目早期,研究人员需要反复观看AI的游戏录像,识别卡住的环节,然后手动调整脚手架设计,从最开始只有截图和按钮输入的简单接口,一步步迭代成多智能体的复杂架构。
多智能体架构是将一个复杂任务分解给多个专门化的AI角色:例如一个负责战斗决策的战斗智能体、一个负责地图导航的寻路智能体、一个负责背包管理的资源智能体。这种分工模式借鉴了软件工程中的微服务思想,每个子智能体只需处理自己擅长的子问题,降低了单个模型的认知负荷。
后期,研究团队做了一个大胆的决定:去掉所有人工编写的子智能体,只给模型提供原始工具(Primitive Tools),让它自己在游戏过程中构建子智能体和可复用脚本。
这套方案的成果令人印象深刻:
- 2025年5月:通关宝可梦蓝
- 2025年8月:通关高难度的宝可梦黄遗产版
- 2025年11月:通关宝可梦水晶
成为首个完成多款宝可梦RPG的AI系统。
自发的持续优化行为
更有意思的是,在黄和水晶的高难度阶段,模型已经开始自发地通过长上下文记忆来迭代策略——这本质上就是一种自发的持续Harness行为。论文所做的,就是把这个过程正式化并实现自动化。
Continual Harness核心架构详解
四大核心组件
Agentive Harness是大模型和环境之间的脚手架层,包含四个核心组件:
- 系统提示词(System Prompt):为模型每一步推理提供指令和策略指导
- 子智能体(Sub-agents):负责处理战斗、策略、解谜、自我反思等特定任务
- 技能库(Skills):包括推理用的启发式规则和可执行程序,如寻路器、工具包装器
- 记忆库(Memory):积累整个轨迹里的事实、策略和观测结果
关键在于,Harness还提供原始工具,让AI能直接对这四个组件做增删改操作。
三类Harness方案对比
论文对比了三类不同层次的Harness:
| 类型 | 特点 |
|---|---|
| 极简Harness | 只有环境接口和通用提示词,无子智能体、记忆和定制技能 |
| 专家Harness | 完全人工设计,内置寻路算法、属性克制表、伤害计算器等 |
| 原始Harness | 只提供原始工具,模型自行构建所需的一切 |
双循环架构设计
Continual Harness采用精巧的双循环架构:
- 内循环:普通的智能体交互步骤,模型根据观测输出动作
- 外循环:Harness优化,Refiner定期读取最近的轨迹窗口,识别失败模式(导航循环、工具调用失败、目标停滞等),然后生成对应的编辑操作
优化流程分四步,分别对应四个组件:重写系统提示词→创建/编辑/删除子智能体→将成功操作序列代码化为新技能→补充和更新记忆条目。
无需重置的核心优势
这种设计有两个关键优势:
- 优化质量随时间累积:不像基于重置的方法每次更新后都要重新积累失败信息
- 能处理后期才出现的失败模式:高难度战斗、多步骤解谜、长对话链等,是基于重置的方法根本接触不到的
现实中很多长周期任务(持续运行的编码任务、具身机器人任务、运维任务)根本无法随意重置环境,这种无需重置的方案更贴合实际应用场景。
实验结果:自动优化效率逼近人工设计
成本与效率对比
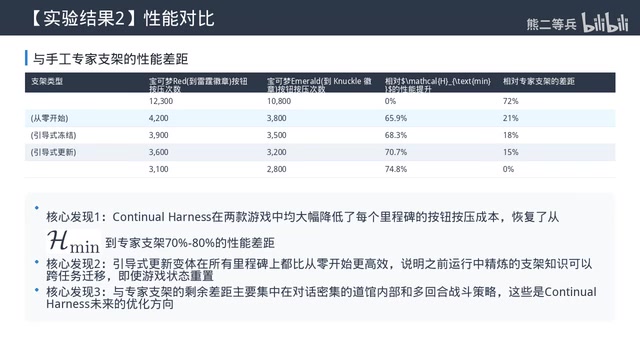
在宝可梦红和绿宝石两个游戏上的实验显示,Continual Harness相比极简Harness,每个里程碑的操作成本大幅降低,填补了极简Harness到专家Harness之间的大部分效率差距——而且它完全没有访问游戏的反编译代码或里程碑列表。
对于能力最强的Gemini 3 Pro:
- Continual Harness花费约130美元完成100%里程碑
- 极简Harness花费215美元仅完成90%
- 成本降低约40%,完成率反而更高
模型能力门槛:并非所有模型都适用
一个重要发现是:Continual Harness的生效存在明确的模型能力门槛。
- Gemini 3 Pro(强模型):收益显著且稳定
- Gemini 3 Flash(中等模型):收益方差很高,表现不稳定
- Gemini 3 Flash Lite(弱模型):所有Continual Harness变体表现反而不如极简Harness
这说明能力不够的模型会因为要处理Harness的优化任务而分散了本身的交互能力,导致整体表现下降。并非任何模型套上这个框架都能获得提升。这一发现与AI领域中广泛讨论的"工具使用能力门槛"现象一致——模型需要达到一定的基础推理能力,才能有效地利用外部工具而非被工具的复杂性所拖累。
开源模型的联合学习验证
研究人员还用Gemma 4系列模型验证了模型权重与Harness状态的联合学习效果。关键发现包括:
- 单独的监督微调和离线强化学习预热都不能让模型取得里程碑进展
- 只有进入联合学习循环后,才开始出现持续的游戏进度提升
- 不管从游戏开头还是中期检查点开始训练,提升曲线形状非常相似
这里需要理解两种训练方法的区别:监督微调(SFT)是用标注好的输入-输出对来调整模型参数,使其在特定任务上表现更好;离线强化学习(Offline RL)则不需要与环境实时交互,而是从预先收集的历史数据中学习策略。本研究的关键发现是,无论是SFT还是离线RL单独使用,都不足以让模型取得实质性进展,只有将模型权重更新与Harness状态优化结合成联合学习循环,才能产生持续的能力提升——这暗示了模型能力和工具能力之间存在深度耦合关系。
这种联合学习的思路与机器学习中的协同进化(Co-evolution)概念相呼应:就像生物进化中基因与环境相互塑造一样,模型的权重和它所使用的工具链也在相互适应。模型变强后能写出更好的工具,更好的工具又让模型能处理更复杂的任务,从而产生更高质量的训练数据,形成正反馈循环。
技能自我优化的直接证据
为确认技能优化确实是性能提升的原因,研究人员用Dijkstra算法作为寻路Oracle进行对比。Dijkstra算法是图论中经典的最短路径算法,由荷兰计算机科学家Edsger Dijkstra于1956年提出,能在加权图中找到从起点到所有其他节点的绝对最短路径。在本研究中,它被用作拥有完整游戏地图信息的理论最优基准——将AI自动生成的寻路技能与Dijkstra的最优解进行对比,可以量化地衡量AI的寻路能力距离理论最优还有多大差距。
结果显示,从零开始的版本路径成本差距从接近50%迅速降到个位数,并持续保持低水平。这意味着AI自主学会的寻路策略已经非常接近拥有完美信息的最优算法。
而冻结优化的版本路径成本差距基本保持平坦,直接证明了技能确实在持续自我优化,逐渐接近最优解。
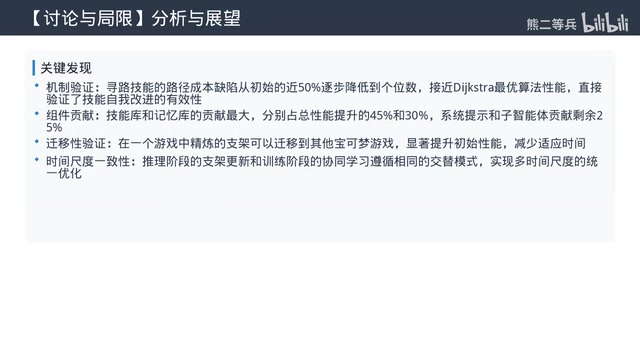
当前局限性与未来研究方向
这项工作也存在一些值得关注的局限:
- 模型能力门槛:能力不足的模型使用该框架反而表现更差,目前开源模型还无法同时胜任Refiner和Agent两个角色
- 收敛极限未知:联合学习实验只展示了训练周期内的持续提升,尚未找到收敛的极限点。两个相互依赖的优化过程(模型权重和Harness状态)是否一定会收敛到稳定状态,目前尚无严格的数学证明
- 缺少与传统方法的对比:还没有和带重置的批量训练做头对头比较
总结:通向通用具身智能的重要一步
这项研究的核心价值在于证明了:具身智能体可以从最基础的环境接口出发,自动构建和优化自己的脚手架,不需要人工介入也不需要环境重置,就能达到接近人工设计专家系统的大部分效率。
这种持续自我改进的框架,未来可以扩展到家庭服务机器人、持续运维系统、开放世界游戏AI等众多长周期具身交互场景。当AI不仅能执行任务,还能在执行过程中不断优化自己的工具和策略时,我们距离真正的通用具身智能又近了一步。
核心要点
- 普林斯顿与DeepMind提出Continual Harness框架,实现具身智能体在单局游戏内自动构建和优化脚手架,无需人工干预或环境重置
- 该框架驱动的AI系统成为首个通关多款宝可梦RPG的AI,自动生成的Harness达到人工设计专家系统的大部分效率,成本降低约40%
- 框架采用双循环设计:内循环执行智能体交互,外循环通过Refiner分析轨迹自动优化系统提示词、子智能体、技能库和记忆库四大组件
- 实验发现Continual Harness存在模型能力门槛,只有足够强的模型才能从中获益,弱模型反而因优化任务分散交互能力而表现下降
- 开源模型通过权重与Harness状态的联合学习实现持续进化,验证了模型和脚手架协同优化的可行性
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。