AI训练的三个阶段:预训练、后训练与对齐详解
AI训练分预训练、后训练、对齐三阶段,理解这些能解释AI为何会"瞎编"。
文章通过"培养新员工"的类比,解释了AI训练的三个阶段:预训练让AI学会语言统计规律,后训练教AI理解人类指令意图,对齐则通过RLHF让AI掌握回答的分寸感和安全底线。这三层能力叠加在同一模型中。AI编造新闻等"幻觉"现象,本质源于预训练阶段只学会了"语言像什么样"而非"事实是什么样"。
你有没有遇到过这样的场景:让AI帮你查几条最新新闻,它一本正经地列出标题、时间、链接,看起来有模有样,点进去却发现——全是编的。
AI为什么会"骗人"?要回答这个问题,我们需要搞清楚AI到底是怎么被训练出来的。整个过程分为三个阶段:预训练、后训练和对齐。理解了这三步,你就能明白AI的能力边界在哪里,也能更聪明地使用它。
一个形象的类比:培养新员工
AI的训练过程,不是把全网内容背一遍,也不是程序员一行一行写规则告诉它"客户骂你的时候先道歉"。它更像是我们培养一个新员工:
- 第一步:丢一堆资料给新员工看——公司过去十年的文档、邮件、合同、产品说明,让他先了解这个行业长什么样。
- 第二步:老员工手把手带他做几个标准案例,告诉他遇到这种情况该怎么回复。
- 第三步:主管反复盯着他的输出打分,告诉他这版好在哪、那版差在哪、哪句话不能说、哪个客户不能怼。
AI的三个训练阶段,差不多就对应这三步。
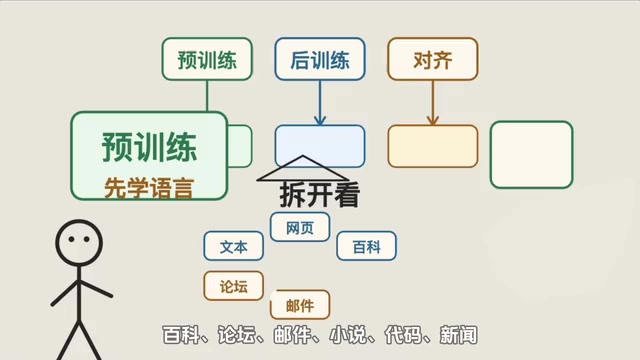
第一阶段:预训练——先把语言学会
预训练阶段,工程师把所有能找到的文本——网页、百科、论坛、邮件、小说、代码、新闻——全部喂给一个空白的模型。以GPT-4这种规模来说,训练数据量大约是几万亿个词。
关于这些数据的规模,有必要多说几句。 以GPT-4为例,其参数量估计超过1万亿,训练数据来源包括Common Crawl(全网爬取数据)、Wikipedia、GitHub代码库、学术论文等多个来源的混合语料。这些数据在输入模型前会经过严格的去重、过滤和质量筛选——低质量内容、重复文本、有害内容会被剔除。训练过程本身需要数千块高端GPU并行运算数月,耗资通常在数千万到数亿美元之间。正是这种规模的训练,让模型形成了对语言统计规律的深度理解,但也同时继承了训练数据中存在的偏见、错误和时效性限制。
模型在这个阶段干的事情只有一件:学习语言长什么样。学到什么程度呢?学到你只给它前半句,它就能猜出下半句最可能是什么。
比如你说"今天天气真……",它会接"好",不会接"自行车"。这不是因为它懂天气,而是因为它见过几亿次"天气真好"这个搭配。
这个阶段结束后,你让它写邮件,它能写出来吗?能。但你一看就觉得哪里怪怪的——开头是"尊敬的客户",中间冒出一句论坛风格的吐槽,结尾又像某篇播客的文案。因为它学的是"全网怎么写字",不是"客户邮件该怎么写"。
一句话总结:预训练之后,AI会说话了,但还不怎么会做事。
第二阶段:后训练——教它听懂你到底想要什么
这一步,AI标注员登场了。标注员会准备几万对、几十万对"用户请求 + 标准回答"的配对数据。
举个例子:
用户请求:帮我写一封延期交付的客户邮件,语气专业,要道歉,要给出新的交付时间。
标准回答:一封结构规范、语气得体的邮件示范。
模型会根据这些示范一对一对地去学,学到它能听懂"延期交付邮件"这几个字背后的完整意图——要道歉、要解释原因、要给新时间、要保持专业语气。

这个时候你再让它写邮件,结构、语气、段落就都对了。但还是有问题:
- 过度承诺:"我保证下次绝不延期"——这种话在商务场景里其实是大忌。
- 过度啰嗦:一句道歉能写成五段。
- 拿不准分寸:客户如果在邮件里粗鲁骂人,它要么硬杠回去,要么过度卑微道歉。
一句话总结:后训练之后,AI会做事了,但还不懂分寸。
第三阶段:对齐——教它什么叫"做得好"
这一步最有意思。工程师不再给标准答案,而是换了一种方式:同一个请求,让模型生成A版和B版两个回答,扔给标注员选哪个更好。标注员的偏好被训练进模型里,经过几十万次、上百万次的反复迭代,模型慢慢学到了一件事:什么叫人喜欢的回答。
这种方法在业界被称为RLHF(基于人类反馈的强化学习),是目前ChatGPT、Claude等主流大语言模型对齐的核心技术。
RLHF的完整工作流程值得深入了解。 这一技术由OpenAI在2022年的InstructGPT论文中系统提出并应用于ChatGPT。其完整流程分为三步:首先训练一个"奖励模型"(Reward Model),专门用来预测人类对某个回答的偏好分数;然后用强化学习算法(通常是PPO,近端策略优化)不断调整语言模型的参数,使其生成的回答能获得更高的奖励分数;最后通过KL散度约束防止模型为了追求高分而偏离原有语言能力。这个过程的关键挑战在于:人类标注员本身存在偏见,且不同标注员的判断标准不一致,这意味着"对齐"的方向本质上反映的是参与标注的人群的价值观,而非某种客观标准。
它学到的不是某一个标准答案,而是一种"感觉"——一种"这种话该说、那种话不该说"的分寸感:
- 道歉要诚恳,但不要过度
- 不能给客户承诺自己做不到的事
- 客户情绪激动的时候,先共情再说事
- 不能在邮件里透露公司内部供应链的问题
这些东西没有一条是写死的规则,它是被"调教"出来的分寸。
此外,对齐阶段还会不断强调底线:不能写出冒犯客户的话、不能编造产品发货时间、不能泄露内部价格、不能帮别人写诈骗邮件。这些底线在训练时被明确标注,模型永远不会直接输出这类内容。
预训练、后训练、对齐不是三个版本,而是三层能力
很多人会误以为这三个阶段是AI的三个版本——先做1.0,再升级到2.0,最后变成3.0。其实不是。它们是三层不同的能力,叠加在同一个模型里:
| 阶段 | 核心能力 | 具体表现 |
|---|---|---|
| 预训练 | 语言和世界的基本常识 | 知道曹雪芹写了《红楼梦》,水的沸点是100度,邮件开头常常是"亲爱的" |
| 后训练 | 听懂人类指令的格式和意图 | 你说"帮我写"就是要它写,说"总结一下"就是要它压缩,说"举三个例子"就给你三条 |
| 对齐 | 在多个合理答案中挑出更安全、更受欢迎的那个 | 面对争议话题不一边倒,语气平和地列出两边观点 |
当GPT告诉你"《红楼梦》的作者是曹雪芹,后四十回一般认为是高鹗续写"——这是预训练的功劳。当你说"帮我把刚才那段话整理成三列表格",它就给你一个标准表格——这是后训练的功劳。当你问一个争议话题,它没有一边倒,而是平和地列出两方观点——这是对齐的功劳。
回到最初的问题:AI为什么会"瞎编"?
现在我们可以回答开头的问题了。AI编造三条不存在的新闻,本质上是预训练阶段埋下的问题。
预训练让它学会的是"语言看起来像什么样",而不是"事实是什么样"。它知道一条新闻应该有标题、有时间、有来源,所以你让它给新闻,它能照着格式写得很像。但它并不知道这条新闻是否真实存在。
这就是我们常说的AI幻觉(Hallucination)——模型生成了看起来合理但实际上不存在的内容。它不是在"骗你",而是它从根本上就不具备区分"像真的"和"是真的
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。