AI早报:Codex跨主机会话、Claude Code重置限额、AlphaFold负责人加入Anthropic
2025年6月20日,AI领域多条重要动态集中爆发。从OpenAI Codex的跨主机会话功能更新,到Claude Code的额度Bug修复,再到AlphaFold核心负责人跳槽Anthropic,以及欧盟押注4000亿参数开源模型——今天的信息密度相当高。以下逐一解读。
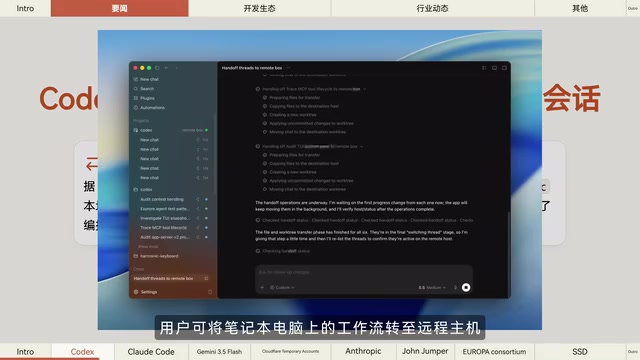
Codex桌面端支持本地与远程主机交接会话
OpenAI Codex桌面端发布了一项实用更新:支持在本地与远程主机之间无缝交接会话。开发者可以在笔记本电脑上启动工作流,随后将其流转至远程主机继续执行,需要时再随时切回本地。
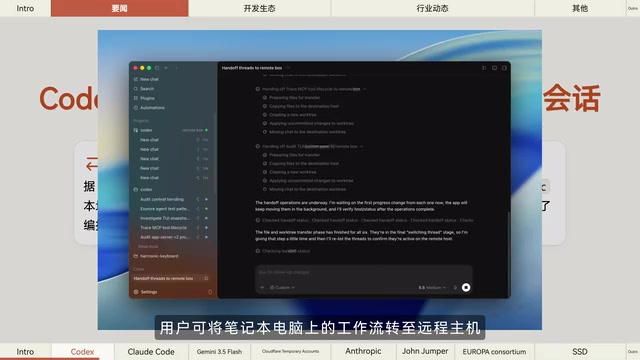
这一功能对于需要在不同环境间切换的开发者来说非常关键。例如,你可以在本地完成代码编写和初步调试,然后将会话交接到配备GPU的远程服务器进行训练或部署,全程无需重新建立上下文。这种"会话漫游"能力正在成为AI编程工具的标配方向。
从技术实现角度看,会话漫游(Session Roaming)的核心挑战在于上下文状态的序列化与恢复。在AI编程助手场景中,一个会话的上下文不仅包括对话历史,还涉及当前工作目录的文件状态、已解析的代码AST(抽象语法树)、依赖关系图谱以及运行时环境变量等。要实现跨主机无缝交接,需要将这些状态高效打包、传输并在目标主机上精确还原。这与传统的SSH远程开发或VS Code Remote Development有本质区别——后者是将开发环境固定在远程,而Codex的方案是让AI理解的上下文可以在任意节点间流动。
不过,社区同时反映了一个严重问题:Codex的InsIcolite日志默认使用全局Trace级别,以约5MB/s的速度持续写入磁盘。有用户推算,这一写入量年化约640TB,可能严重损耗SSD寿命。目前该问题尚未获得官方修复,使用Codex的开发者建议关注日志配置。
需要解释的是,Trace级别是日志系统中最详细的记录级别,通常仅在深度调试时启用。常见的日志级别从低到高依次为Trace、Debug、Info、Warn、Error、Fatal。以5MB/s的速度持续写入意味着每小时约18GB的数据量。现代消费级NVMe SSD的总写入量(TBW, Total Bytes Written)通常在300-600TB之间,这意味着如果不加干预,Codex的日志写入可能在一年内耗尽SSD的设计寿命。这类问题在软件工程中被称为"日志风暴"(Log Storm),通常是默认配置未针对生产环境优化的结果。
Claude Code额度Bug修复与Gemini配额重置
Claude Code:3%用户受额度显示错误影响
Anthropic旗下的Claude于6月19日发布通知,称约3%的Claude Code用户遭遇额度显示错误,部分用户甚至无法正常发送消息。官方表示该问题已修复,并重置了受影响用户的额度限制。
虽然影响范围看似不大,但考虑到Claude Code用户群体的快速增长,实际受影响人数可能不少。这也反映出AI编程工具在高速扩张期面临的基础设施挑战——额度系统、计费系统的稳定性直接关系到用户体验和信任。
深入来看,AI编程工具的额度管理系统远比传统SaaS的计费系统复杂。每次代码生成请求的Token消耗量差异巨大——一个简单的代码补全可能只需几百Token,而一次完整的代码重构可能消耗数万Token。加上Claude Code支持的多轮对话和长上下文窗口,额度的实时计算需要在高并发场景下保持精确一致性。这本质上是一个分布式系统中的一致性问题,尤其在用户量快速增长时,限流器(Rate Limiter)和配额追踪器的同步延迟很容易导致显示错误甚至服务中断。
AntiGravity修复Gemini 3.5 Flash循环输出问题
AntiGravity负责人宣布已修复Gemini 3.5 Flash输出文本循环问题,并部署了新版本。同时,所有用户的每周配额已重置,方便大家体验更新后的效果。

文本循环输出是大语言模型的常见顽疾之一,尤其在Flash等轻量级模型上更容易出现。此次修复对于依赖Gemini 3.5 Flash进行日常开发的用户是个好消息。
从技术原理上看,文本循环输出(Repetition Loop)是自回归语言模型的一个已知缺陷。其根本原因在于模型的解码策略:当模型在某个生成步骤中对特定Token序列赋予了较高概率,这些Token被生成后又会作为下一步的输入上下文,进一步强化同一模式的概率,形成正反馈循环。轻量级模型(如Flash系列)由于参数量较小、注意力头数较少,对长距离依赖的建模能力相对有限,更容易陷入局部概率陷阱。常见的缓解手段包括重复惩罚(Repetition Penalty)、频率惩罚(Frequency Penalty)、以及基于N-gram的去重检测等。
Cloudflare推出AI Agent临时账户功能
Cloudflare推出了一项面向AI Agent的Temporary Accounts功能。其核心设计理念是降低AI Agent的部署门槛:Agent无需提前注册账户,运行特定命令即可直接将Worker部署到Cloudflare,保持60分钟有效期。开发者后续可通过认领链接保留Worker及数据库等资源。
这一功能为AI Agent的"即用即走"场景提供了基础设施支持。想象一下,一个AI Agent在执行任务时需要临时部署一个API端点或数据处理服务,过去需要繁琐的账户注册和配置流程,现在可以直接完成。这是云服务商主动适配AI Agent工作模式的重要信号。
值得补充的是,Cloudflare Workers是一种基于V8引擎的边缘计算(Edge Computing)平台,代码运行在全球300多个数据中心的边缘节点上,而非集中式的云服务器。这种架构天然适合AI Agent的"即用即走"场景:Agent可以在距离用户最近的节点上快速部署轻量级服务,实现毫秒级响应。临时账户功能的60分钟有效期设计借鉴了"临时沙箱"(Ephemeral Sandbox)的理念——为每次任务创建隔离的运行环境,任务完成后自动清理,既降低了安全风险,也简化了资源管理。这种模式与Kubernetes中的Job和CronJob概念类似,但将抽象层级提升到了无需管理任何基础设施的程度。
AlphaFold负责人离开DeepMind加入Anthropic
AlphaFold核心负责人、诺贝尔奖得主John Jumper在任职Google DeepMind近9年后宣布离开,计划在休息后加入Anthropic。
这是一条极具象征意义的人事变动。John Jumper因领导AlphaFold项目解决蛋白质结构预测问题而获得2024年诺贝尔化学奖,是DeepMind最具标志性的科学家之一。他的离开和转投Anthropic,一方面说明Anthropic对顶尖科研人才的吸引力正在增强,另一方面也可能暗示Anthropic在科学计算和生物AI方向的布局野心。
要理解这一人事变动的分量,需要了解AlphaFold项目的里程碑意义。蛋白质结构预测是生物学领域持续半个世纪的核心难题,被称为"蛋白质折叠问题"(Protein Folding Problem)。蛋白质由氨基酸链组成,其三维折叠结构决定了生物功能,但从一维序列推断三维结构的计算复杂度极高。传统方法如X射线晶体学和冷冻电镜需要数月甚至数年才能解析一个蛋白质结构。AlphaFold2于2020年在CASP14(蛋白质结构预测关键评估)竞赛中达到了接近实验精度的预测水平,随后开源的AlphaFold数据库覆盖了超过2亿个蛋白质结构预测,彻底改变了结构生物学的研究范式。John Jumper作为该项目的技术负责人,其科学影响力在AI领域几乎无人能及。他加入Anthropic,可能意味着Anthropic正在认真考虑将大语言模型的能力延伸到科学发现领域。
政策与国际动态
白宫与Anthropic联合制定AI漏洞评估框架

据媒体报道,白宫与Anthropic正在联合制定AI模型漏洞评估框架。此前因Jailbreak(越狱攻击)争议引发了出口管制方面的讨论,目前双方的谈判已从政策层面转向制定具体的技术标准。
这一动向值得密切关注。如果最终形成标准化的漏洞评估框架,将对整个AI行业的安全合规产生深远影响,尤其是在模型出口和跨境部署方面。
这里有必要解释Jailbreak攻击的技术背景。Jailbreak(越狱攻击)是指通过精心构造的提示词(Prompt)绕过AI模型的安全对齐(Safety Alignment)机制,使其生成被禁止的内容。常见的越狱技术包括角色扮演诱导、多轮渐进式引导、编码混淆(如Base64编码指令)、以及利用多语言切换绕过安全过滤器等。目前业界尚无统一的漏洞评估标准——不同公司对"安全"的定义和测试方法各不相同。白宫与Anthropic联合制定的框架如果落地,可能类似于网络安全领域的CVE(通用漏洞披露)体系,为AI模型的安全缺陷建立标准化的分类、评级和披露流程。这对于AI模型的出口管制尤为关键,因为监管机构需要一个可量化的标准来判断模型是否满足安全要求。
欧盟选定4000亿参数开源模型项目
欧洲委员会宣布选定由意大利公司Doming领导的Europa联盟作为Frontier AI Grand Challenge项目的获胜者。该项目计划开发一款覆盖全部24种官方欧盟语言、参数超4000亿的开源前沿AI模型。

欧盟此举的战略意图非常明确:在美国和中国主导的AI竞赛中建立自主能力,同时通过多语言覆盖强化欧洲的数字主权。4000亿参数的规模虽然不算最前沿,但开源定位加上24种语言的全覆盖,使其在欧洲市场具有独特价值。
更深层来看,欧盟的"数字主权"(Digital Sovereignty)战略旨在减少对美国和中国科技巨头的依赖,确保欧洲在数据、算法和基础设施层面拥有自主控制权。此前欧盟已通过《AI法案》(EU AI Act)建立了全球最严格的AI监管框架,而此次投资开源大模型则是从"监管"转向"建设"的关键一步。24种官方语言的全覆盖具有特殊意义:目前主流大模型在英语上的表现远优于其他语言,欧洲的小语种(如马耳他语、爱沙尼亚语、爱尔兰语等)在训练数据中严重不足。一个专门优化这些语言的开源模型,不仅有技术价值,更是欧盟维护语言多样性和文化认同的政治工具。
小结
今天的AI动态呈现出几个清晰趋势:AI编程工具的基础设施正在快速成熟(Codex跨主机会话、Cloudflare临时账户);顶尖人才向Anthropic聚集的趋势明显(John Jumper加入);AI安全与合规正从政策讨论走向技术标准化(白宫-Anthropic框架)。而Codex的SSD损耗问题则提醒我们,工具的快速迭代中,细节上的疏忽可能带来意想不到的代价。
相关推荐
Claude Code安装配置教程:搭配国产模型低成本开启氛围编程
详细讲解Claude Code的安装步骤与配置方法,包括Node.js环境搭建、CCSwitcher模型管理工具使用,以及搭配DeepSeek等国产模型实现低成本氛围编程的完整流程。
Keyroll:一款主打稳定的Claude续杯工具深度体验
深度体验Claude续杯工具Keyroll,分析其稳定性、响应速度等核心优势,探讨续杯工具的安全性与合规性问题,帮助开发者在用量限制下做出理性选择。

OpenLLMVTuber:开源AI虚拟人框架深度解析
深度解析GitHub 10K星标开源项目OpenLLMVTuber,一套集成语音识别、大语言模型、语音合成与Live2D角色的AI虚拟人框架,支持语音打断、视觉感知、桌面陪伴等功能,模块化架构可灵活替换各层组件。