Andrej Karpathy加入Anthropic:顶级AI研究者重返前沿研发
重磅人事变动:Karpathy加入Anthropic
近日,AI领域知名人物Andrej Karpathy在社交媒体上宣布了一则重要的个人动态——他已正式加入Anthropic公司。这位曾在OpenAI和特斯拉担任核心技术角色的AI研究者,选择在这个关键时刻重返大模型前沿研发一线。
Karpathy在推文中写道:"我认为未来几年在LLM前沿领域将尤为关键(formative)。我非常兴奋能加入这里的团队,重新投入研发工作。"
为什么Karpathy加入Anthropic意义重大
Karpathy的行业分量不容忽视
Andrej Karpathy是深度学习领域最具影响力的研究者和工程师之一。他的职业轨迹几乎串联了整个现代AI发展史:斯坦福大学博士(师从李飞飞)、OpenAI创始团队成员、特斯拉AI与自动驾驶视觉总监,再到后来回归OpenAI后又独立创业做AI教育。每一次他的职业选择,都被业界视为某种风向标。
值得深入了解的是,Karpathy在斯坦福大学攻读博士期间,师从计算机视觉领域的先驱李飞飞教授,其博士研究聚焦于将卷积神经网络(CNN)与循环神经网络(RNN)结合,实现图像与自然语言之间的跨模态理解,为后来的图像描述生成(Image Captioning)领域奠定了重要基础。在特斯拉担任AI与自动驾驶视觉总监期间,他主导了从雷达+摄像头的多传感器融合方案向纯视觉(Vision-only)方案的战略转型,这一决策在当时极具争议,但最终被证明是可行的技术路线,充分展示了他在大规模工程系统中做出关键技术判断的能力。
作为OpenAI 2015年成立时的创始团队成员之一,Karpathy与Ilya Sutskever、Greg Brockman、Sam Altman等人共同参与了这家如今全球最知名AI实验室的早期建设。OpenAI成立之初是一家非营利研究机构,其使命是确保通用人工智能(AGI)能够惠及全人类。Karpathy在OpenAI早期主要参与了深度强化学习和生成模型方面的研究工作,他对Gym(OpenAI开源的强化学习环境工具包)等基础设施的贡献,帮助奠定了整个强化学习研究社区的实验标准。他后来离开OpenAI加入特斯拉,再回归OpenAI,又再次离开——这种在产业界和研究界之间的反复切换,使他同时具备了学术深度和工程广度,这在AI领域是极为稀缺的复合型能力。
此次加入Anthropic,意味着这位顶级人才认为Anthropic正处于一个值得全力投入的位置。他用"formative"(塑造性的、关键的)一词来形容未来几年的LLM发展,暗示我们可能正站在大模型技术范式转变的关键节点上。当前业界正在从单纯的预训练规模扩展(Scaling Laws)向更多元的技术路线演进:包括推理时计算扩展(test-time compute scaling)、多模态融合、长上下文窗口处理、工具使用与Agent架构、以及合成数据训练等方向。OpenAI的o1/o3系列模型展示了通过链式思维推理提升模型能力的可能性,而Anthropic的Claude系列则在长文本理解和代码生成方面展现了独特优势。这些技术路线的竞争和融合,可能在未来2-3年内决定下一代AI系统的基本架构形态——这正是Karpathy所说的"formative"时期的深层含义。
Anthropic的人才吸引力持续增强
作为由前OpenAI核心成员Dario Amodei和Daniela Amodei创立的公司,Anthropic一直以其对AI安全的重视和Claude系列模型的出色表现著称。Karpathy的加入进一步巩固了Anthropic在顶级AI人才争夺战中的优势地位。
近年来,Anthropic在技术路线上展现出独特的竞争力——Claude模型在编程、推理和长文本处理等方面持续获得用户好评,其"Constitutional AI"等安全对齐方法也在学术界产生了广泛影响。所谓Constitutional AI(宪法AI),是Anthropic提出的一种创新性AI对齐方法论,其核心思想是让AI系统依据一组预先定义的原则(即"宪法")来自我评估和修正输出内容。与传统的RLHF(基于人类反馈的强化学习)方法不同,Constitutional AI引入了RLAIF(基于AI反馈的强化学习)机制——先让模型生成回答,再让模型自身根据宪法原则对回答进行批评和修订,最后用这些修订后的数据进行强化学习训练。这种方法大幅减少了对人类标注员的依赖,同时使AI的行为准则更加透明和可审计,体现了Anthropic"安全优先"的技术哲学。
从模型演进的角度来看,Anthropic的Claude系列经历了快速而显著的迭代。从早期的Claude 1.0到Claude 2,再到2024年推出的Claude 3系列(Haiku、Sonnet、Opus三个不同规模的版本),以及后续的Claude 3.5和Claude 4系列,每一代模型都在能力边界上实现了明显突破。特别值得关注的是,Anthropic在产品创新方面也展现出独到的眼光:其推出的MCP(Model Context Protocol,模型上下文协议)是一个开放标准协议,旨在为AI模型与外部数据源、工具之间建立统一的连接方式,类似于AI世界的"USB接口",极大地简化了AI应用的集成开发流程。此外,Anthropic率先推出的Computer Use(计算机使用)功能,让Claude能够直接操作计算机界面——移动鼠标、点击按钮、输入文字,这标志着AI从"对话助手"向"数字化行动者"的重要跨越。这些技术布局显示出Anthropic不仅在基础模型能力上持续追赶,更在AI应用范式的定义上展现出前瞻性的战略思维。
能够吸引Karpathy这样既有深厚研究功底又有大规模工程落地经验的人才,充分说明Anthropic的技术愿景和团队文化具有强大的吸引力。
Karpathy的教育事业:暂缓但未放弃
有意思的是,Karpathy在声明中特别提到:"我对教育依然充满热情,计划在适当的时候恢复这方面的工作。"
此前,Karpathy离开OpenAI后曾全身心投入AI教育领域,创办了Eureka Labs,并在YouTube上发布了一系列广受好评的深度学习教程(如"Neural Networks: Zero to Hero"系列),这些内容帮助了无数开发者和学生入门AI。Eureka Labs致力于探索AI辅助教育的新范式,其愿景是让AI成为个性化学习的核心引擎。而他的YouTube教程系列从最基础的反向传播算法手写实现开始,逐步构建到GPT级别的语言模型,全程使用纯Python代码从零实现,不依赖任何深度学习框架。这种"从第一性原理出发"的教学方法,让学习者真正理解每一层抽象背后的数学原理和工程实现,而非仅仅学会调用API。他的另一个知名项目minGPT/nanoGPT,用极简代码复现了GPT架构,成为全球AI教育领域被引用最多的开源教学项目之一,在GitHub上获得了数万颗星标。
Karpathy对AI教育的投入,实际上反映了当前AI行业面临的一个深层挑战:人才供给与需求之间的巨大缺口。随着大模型技术从实验室走向大规模商业应用,行业对既理解底层原理又能进行工程实践的复合型AI人才的需求呈指数级增长。然而,传统的大学教育体系在课程更新速度上远远跟不上技术迭代的节奏——一门关于Transformer架构的课程从设计到开设可能需要一到两年,而在这段时间内,技术前沿可能已经发生了多次范式级别的变化。Karpathy通过YouTube和开源项目构建的"非正式教育管道",在某种程度上填补了这一空白,其影响力甚至超过了许多顶级大学的正式课程。
"暂缓"而非"放弃"的表态,说明Karpathy将教育视为长期使命,但当前阶段他判断回到研发前线更为紧迫。这种优先级的调整本身就传递了一个信号:LLM领域正在进入一个技术突破的密集期,一线研发的机会成本正在急剧上升。
AI行业格局的微妙变化
从更宏观的视角来看,Karpathy加入Anthropic折射出当前AI行业竞争格局的几个趋势:
-
顶级AI人才流动加速:顶级AI研究者在主要实验室之间的流动越来越频繁,这既反映了行业的活力,也说明各家公司在技术路线和文化上的差异化正在加深。值得注意的是,Anthropic本身就是这种人才流动的产物——Dario Amodei等核心创始成员正是因为在AI安全理念上与OpenAI产生分歧而选择独立创业,这种"理念驱动"的人才流动正在重塑整个行业的竞争版图。事实上,AI领域的人才流动已经形成了一种独特的"裂变-创新"模式:Google Brain的研究者创立了OpenAI的技术基础(Transformer论文的多位作者来自Google),OpenAI的核心成员又分裂出Anthropic,而从这些顶级实验室走出的研究者还创办了Cohere、Adept、Character.AI、xAI等一系列新兴AI公司。每一次分裂都伴随着技术理念的分化和新方向的探索,客观上加速了整个领域的创新节奏。
-
Anthropic发展势头强劲:在OpenAI、Google DeepMind、Meta AI等巨头的竞争中,Anthropic作为相对年轻的公司,正在通过技术实力和人才吸引力证明自己的行业地位。截至目前,Anthropic已获得来自Google、亚马逊等科技巨头的大规模投资,估值跻身AI领域前列,其Claude模型也已成为ChatGPT最有力的竞争者之一。从资本层面看,Anthropic的融资历程本身就是AI行业资本竞赛的缩影——亚马逊对Anthropic的投资总额高达数十亿美元,这不仅是财务投资,更是云计算巨头在AI时代争夺生态位的战略布局。亚马逊通过投资Anthropic,将Claude模型深度整合进AWS(亚马逊云服务)的Bedrock平台,为企业客户提供差异化的AI服务;而Google同样通过投资Anthropic对冲自身在AI竞争中的风险。这种"科技巨头+AI实验室"的联盟模式,正在成为AI行业的主流竞争形态。
-
前沿研发的紧迫感上升:Karpathy选择放下教育事业重返研发一线,暗示业内人士普遍感受到当前是技术突破的关键窗口期。从技术层面看,当前大模型领域正面临多个可能的突破方向——如何突破现有Transformer架构的效率瓶颈、如何实现更可靠的推理能力、如何让模型真正具备持续学习和自我改进的能力——这些问题的答案可能在未来几年内逐步揭晓。这种紧迫感的一个重要来源是所谓的"数据墙"(Data Wall)问题。根据Chinchilla Scaling Laws(由DeepMind在2022年提出的训练计算最优分配法则),模型参数量和训练数据量应当按比例同步扩展才能实现最优性能。然而,互联网上高质量文本数据的总量是有限的,多项研究估计,以当前的训练数据消耗速度,高质量英文文本数据可能在未来几年内面临枯竭。这迫使研究者们积极探索替代方案:合成数据生成(用AI生成训练数据来训练AI)、课程学习(Curriculum Learning,按照由易到难的顺序组织训练数据)、数据质量过滤与去重、以及从多模态数据(视频、音频、代码、科学文献)中挖掘新的训练信号。与此同时,以Mamba为代表的状态空间模型(SSM)正在挑战Transformer在序列建模领域的统治地位,其线性复杂度的计算特性有望解决长序列处理的效率问题。这些技术路线的探索和竞争,正是Karpathy所感受到的"formative"时期的具体体现。
无论对于Anthropic还是整个AI行业,Karpathy的这一选择都值得持续关注。他在新岗位上的研究方向和成果,或将成为未来LLM发展的重要推动力。
核心要点
核心要点
相关推荐
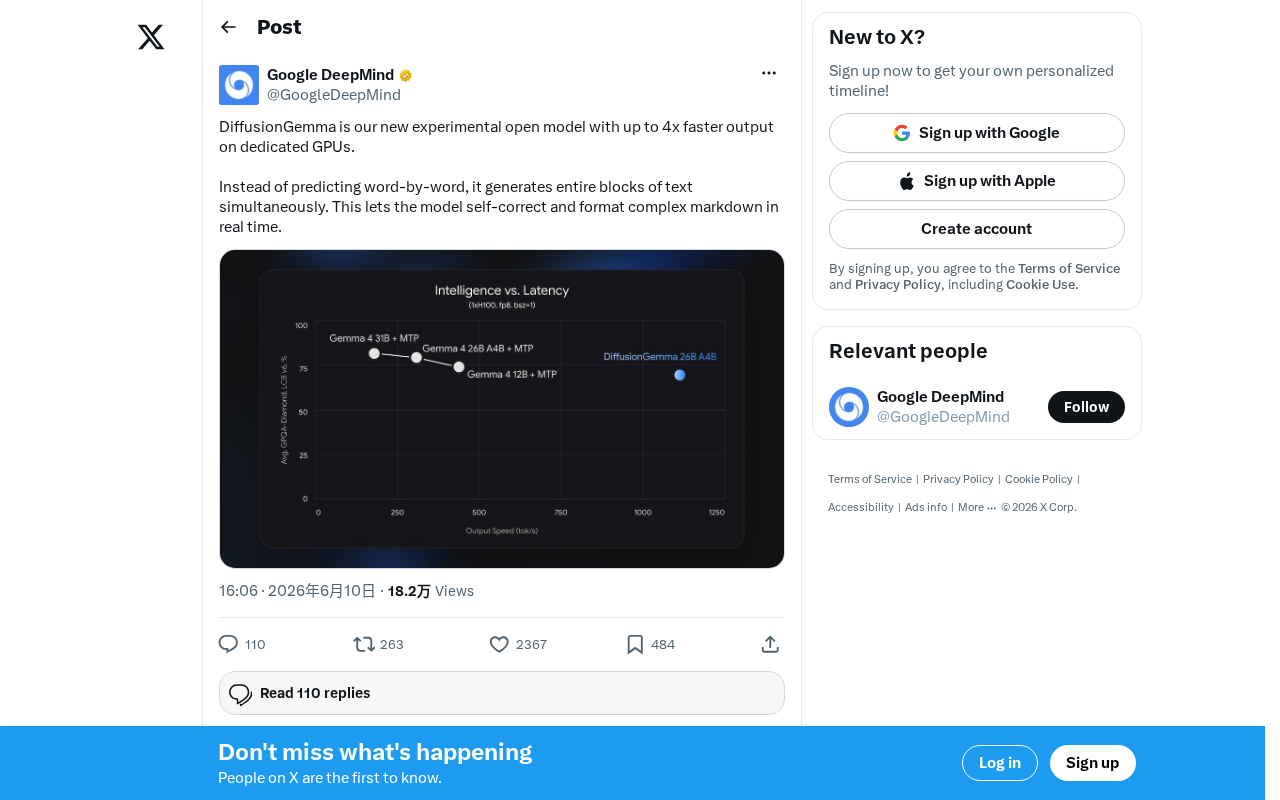
DiffusionGemma:谷歌开源扩散式语言模型,推理速度提升4倍
谷歌发布开源扩散式语言模型DiffusionGemma,将扩散模型思路引入文本生成,实现最高4倍速度提升与实时自我纠错能力。本文详解其核心技术原理、与传统自回归模型的差异及行业影响。
Claude Code Skills详解:AI自动生成测试用例实战指南
深入解析Claude Code Skills技能文件的四大核心优势:篇幅扩展、复用传播、版本控制与渐进式加载,详解如何利用Skills实现AI自动生成测试用例的工程化落地流程。

独立开发者晒账单:花2366元做的小程序,零收入
一位独立开发者花半年时间、2366元开发英语阅读小程序,上线一个月仅10个用户零收入。逐笔拆解API调用、云服务、小程序认证等成本明细,复盘市场验证缺失、Azure隐藏扣费等典型教训。