编程Agent核心原理:感知与上下文工程如何决定AI编程效果
为什么同款模型效果天差地别
同样是AI写代码,有的工具改bug又快又准,有的却一上来就胡写一通,放进项目就是满屏报错。很多人以为这是模型强弱的差距,但真正拉开差距的往往不是模型本身,而是它动手之前的两件事——感知和上下文工程。
说白了,就是这个编程Agent到底有没有先看懂你的项目。
AI编程工具的进化,本质是它跟真实工程环境之间那根"接口"的进化。而这根接口的第一段,就是Agent怎么看见环境、又怎么决定哪些信息要装进自己的工作记忆里。很多工具用的是同款模型,效果却天差地别,深层原因就藏在感知和上下文工程这两块。


感知机制:编程Agent动手之前先睁眼
Agent的第一步不是写代码
很多人以为编程Agent拿到任务后第一步是写代码,其实不是。它真正的第一步是搞清楚自己现在在哪。
对编程Agent来说,环境就是你当前的代码项目,它得先定位。就像打仗之前要先确认坐标——一个没有真实环境信息的模型,本质上就是个闭着眼睛开枪的枪手。它可能很能打,但根本不知道往哪儿打。
这背后对应的是Agent系统设计中经典的感知-规划-执行(Perceive-Plan-Act)循环。在学术界和工业界的Agent架构中,感知模块始终是整个决策链的第一环。没有感知,后续的规划就是空中楼阁——模型无法基于真实状态做推理,只能依赖训练数据中的统计模式去"猜",而猜的结果在具体工程项目中几乎必然偏离实际。这也是为什么即便底层LLM能力相同,不同Agent框架的表现可以有数量级的差距。
感知具体要看清什么
Agent需要逐项回答几个基础问题:
- 项目结构:根目录有哪些文件夹,入口在哪儿
- 技术栈:前端是React还是Vue,后端是Express还是FastAPI
- 运行方式:测试命令、构建命令分别是什么
- 依赖管理:包管理器用的是npm、pnpm还是uv、cargo
- 规则文件:有没有项目级的规则文件,比如
CLAUDE.md、agents.md、.cursorrules
这一项项全确认通过,它才算真正站在了你的项目里。
跳过感知的代价:幻觉与错误代码
举个例子:你让Agent给项目加一个登录功能。如果它不看环境,不知道你用的是React还是Vue,不知道认证逻辑放在哪一层,不知道数据库怎么访问——它写出来的代码很可能语法挑不出一点毛病,但一放进项目就是接口404、依赖冲突、引用报错。
这就是典型的AI幻觉——不是它笨,是它压根没看就开了枪。
从技术角度理解,大语言模型的幻觉(Hallucination)本质上是模型在缺乏grounding信息(即与真实世界对齐的锚定信息)时,依赖训练语料中的高频模式进行补全的结果。模型见过成千上万个登录功能的实现,它会选择一个统计上最"合理"的版本输出——但"统计合理"和"在你这个项目里能跑"是两回事。感知机制的作用正是提供grounding:把模型的输出从"通用合理"拉回到"项目内正确"。没有grounding的生成,本质上就是一种高置信度的错误。
感知依赖的工具调用
落到工具调用层面,感知主要靠这几件武器:
- 列目录工具:看清整个项目结构
- 读配置文件:读
package.json或pyproject.toml,知道依赖和脚本命令 - 读规则文件:理解团队约定
- 代码搜索工具:按关键词定位相关文件,参考已有的同类组件和接口
这些动作对应通用Agent技术里的一个核心概念——Perception(感知),它是任务能不能开始的前提。
上下文工程:有限token预算下的精准取舍
为什么不能把整个项目全塞进去
讲到这里肯定有人会说:感知这么麻烦,我直接把整个项目代码全塞给模型,不就什么都看见了?
答案是不行,而且会出大问题。全量输入换来的是"缓冲区溢出"——把所有东西一股脑塞进去看着很全,实际上是摊多嚼不烂。
三个硬限制,一个比一个关键:
- 上下文窗口有限:就算模型号称上百万token,一个真实的中大型项目动辄几十万、几百万行代码,根本装不下
即便是2024-2025年最前沿的模型(如Gemini的百万token窗口、Claude的200K窗口),面对一个中等规模的企业级项目也捉襟见肘。一个典型的中型后端项目可能有5-10万行代码,加上依赖和配置文件轻松突破百万token。更关键的是,Transformer架构的注意力计算复杂度与序列长度呈二次方关系(标准自注意力为O(n²)),虽然各种稀疏注意力和线性注意力方案在缓解这个问题,但实际推理中,超长上下文的计算成本和延迟仍然是硬约束。
-
成本和速度:上下文越长,每次调用越贵越慢
-
中间遗忘(最致命):信息越多,模型的注意力反而越被稀释,重点淹没在无关代码里,它就找不着北了
这个现象在学术界被称为**"Lost in the Middle"**(中间遗忘效应),由斯坦福等机构在2023年的研究中系统性地揭示。实验表明,当关键信息被放置在长上下文的中间位置时,模型的检索和利用能力会显著下降——模型倾向于更好地利用开头和结尾的信息,而对中间部分的注意力分配明显不足。这意味着即使你把正确答案塞进了上下文,如果它被大量无关代码包围,模型很可能"视而不见"。这不是模型的bug,而是当前注意力机制的结构性局限。
上下文工程的核心定义
上下文工程一句话就能说清:在每一次模型调用之前,决定到底把哪些内容拼进prompt。
它的本质是一个带预算的取舍问题——在token总量有限的条件下,尽可能提高任务相关信息的密度。记住:决定了什么进入模型,其实就决定了它的输出。
这个概念近期被Anthropic等公司的工程团队反复强调,它标志着行业认知的一次重要转变:从"prompt engineering"(如何措辞提问)升级到"context engineering"(如何系统性地管理模型的输入信息流)。前者关注的是单次交互的措辞技巧,后者关注的是整个信息管道的架构设计——包括什么时候获取信息、获取哪些信息、如何压缩和组织信息、以及何时丢弃过时信息。
上下文分配的五个维度
预算就这么多token,要分配到五个地方:
| 维度 | 策略 |
|---|---|
| 文件选择 | 任务相关的进,无关的不进 |
| 片段选择 | 大文件只截取相关函数、类 |
| 历史对话 | 决定带几轮、要不要做摘要 |
| 规则文件 | 选择性带入项目约定 |
| 工具调用结果 | 刚搜到的文件名、报错信息等 |
实战对比:好Agent与差Agent的行为差异
同一个问题,两种处理方式
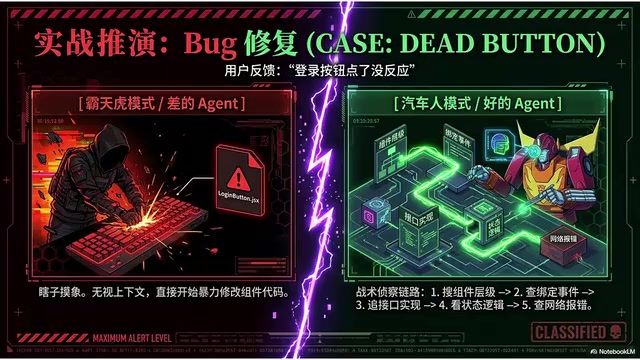
用户甩来一句话:"这个登录按钮点了没反应。"
差的Agent(莽夫模式):什么都不看,把"按钮没反应"直接理解成按钮组件有问题,抡起锤子就去改LoginButton。
好的Agent(侦探模式):
- 先搜
LoginButton出现在哪些文件,理清组件层级 - 看按钮绑了什么事件,处理函数在哪
- 追踪函数调了哪个接口,接口在哪实现
- 检查有没有loading状态、错误处理
- 翻控制台有没有报错,网络请求是404还是500
- 项目里有测试也看一眼
增量探索而非一次性全塞
好的编程Agent不是把所有信息一次性全塞进上下文。它是以任务为中心,一圈一圈分阶段往外探,增量获取,只把最关键的几条留在工作记忆里。
这才是上下文工程真正在做的事——动态构造一个跟当前任务相关的视野,让模型在每一步都恰好看到它需要的东西,又不被无关信息干扰。像雷达一样持续扫描、持续聚焦。
这种工作模式在技术上对应的是ReAct(Reasoning + Acting)框架及其变体。ReAct由Google和普林斯顿在2022年提出,核心思想是让LLM交替进行"思考"和"行动":模型先推理当前需要什么信息,然后调用工具获取,再基于新信息继续推理下一步。这与传统的"一次性输入-一次性输出"模式有本质区别。在编程Agent场景中,这意味着Agent会形成一个动态的探索链——每一步的工具调用结果都会影响下一步的决策方向,上下文在整个过程中被持续地重组和更新。这种多步交互模式让Agent能够处理远超单次上下文窗口容量的复杂任务。
感知与上下文工程在产品中的两种形态
这两块能力在产品里体现为两种形态:
显性感知(Claude Code、Codex CLI等终端Agent):你能直接看到它发了哪些工具调用、搜了什么、读了哪些文件、保留了哪些片段,整个过程明明白白。
隐性感知(Cursor等IDE Agent):天然知道你当前打开了哪个文件、选中了哪一段、光标停在哪、刚改了什么——这些都是IDE免费送的信号。
这两种形态背后的技术架构差异值得深入理解。终端Agent(如Claude Code)运行在一个相对"贫信息"的环境中,它必须主动通过工具调用去获取每一条信息,因此其感知过程是显式的、可审计的。而IDE Agent则运行在一个"富信息"的环境中——IDE本身就是一个强大的代码理解引擎,它维护着AST(抽象语法树)、符号索引、类型信息、Git历史等结构化数据。IDE Agent可以直接利用这些已经计算好的结构化信息作为上下文,而不需要从原始文本重新解析。这就是为什么Cursor能做到"你选中一段代码它就知道上下文"——这不是魔法,而是IDE的Language Server Protocol(LSP)和语法分析器已经帮它完成了大量感知工作。两种形态各有优劣:显性感知更透明可控,适合复杂的跨文件重构;隐性感知更流畅自然,适合日常的局部编辑。
不同工具的差距往往就在这里:模型同款,但感知做得细不细、上下文采得准不准,效果差很多。
提升编程Agent效果的五条实践原则
最后沉淀五条可以直接拿去用的原则:
- 相关性优先于全面性:宁可少一点但精准,别堆一大堆把重点稀释
- 结构化信息比原始文本值钱:一段Git Diff、一个符号定义、一张调用关系图,比整块未筛选的源码高效得多
- 规则文件是长期上下文的最佳载体:一次写好每次复用,比每轮对话重复输入可靠太多
- 上下文可以压缩但不能丢关键状态:早期细节可换成摘要,但当前TODO、关键决策、未解决的报错必须留着
- 上下文工程是持续进行的:每跑一个工具、每收一段反馈,上下文都在被重新组织
关于第3条值得多说几句:规则文件(如CLAUDE.md、.cursorrules)本质上是一种持久化的系统提示词。它解决的是一个根本性问题——LLM没有跨会话的记忆。每次新对话开始,模型对你的项目一无所知。规则文件相当于把项目的"元知识"(编码规范、架构决策、技术选型理由、常见陷阱)固化下来,让Agent在每次启动时都能快速加载这些长期有效的上下文,而不是每次都从零开始探索。这是目前最低成本、最高回报的上下文工程实践。
总结
感知是Agent主动看环境的能力,决定了任务能不能开始;上下文工程是把感知到的信息有选择地装进模型的能力,决定了任务能不能做好。
**模型决定上限,上下文工程决定下限。**一个真正好的编程Agent,往往是把上下文工程做扎实了,而不是一味去堆参数。
从更宏观的视角看,这个结论反映了AI应用层的一个普遍规律:在基础模型能力趋于同质化的今天,系统工程(而非模型本身)正在成为产品差异化的核心战场。上下文工程、工具设计、反馈循环、错误恢复机制——这些"模型之外"的工程能力,决定了同一个模型在不同产品中能发挥出多大的实际价值。这也是为什么我们看到越来越多的AI公司把重心从"训练更大的模型"转向"构建更好的系统"。
相关推荐
UE5.8接入MCP Server完整教程:Codex插件配置详解
详细讲解Unreal Engine 5.8接入MCP Server的完整流程,涵盖UE5.8安装注意事项、VS Code Codex插件配置、API密钥设置、MCP插件启用与Server启动,帮助开发者快速搭建AI辅助开发环境。
Claude Fable 5全球封禁:AI经济链条断裂危机深度解析
Claude Fable 5发布三天即遭美国政府封禁,仅限美国公民使用。深度分析越狱争议背后的真实动机、全球AI供应链断裂风险、Anthropic恐惧营销反噬,以及普通用户应对策略与本地AI部署方案。
Claude Fable 5实测:Token翻倍值不值?Rust编程对比Opus 4.8
通过Rust模拟项目实测对比Claude Fable 5与Opus 4.8的编程能力。Fable 5消耗两倍Token,输出质量仅略有提升,且存在稳定性问题。详细分析两款模型的规划、编译、功能完整性差异,帮助开发者做出合理的模型选择。