Claude Code + Codex 交叉验证:大幅降低AI编程Bug率
AI编程的痛点:代码越改越乱怎么办
相信很多AI编程爱好者都有过这样的经历:代码刚开始写得好好的,但越改越乱,最终整个项目变得无法运行,甚至连修复都困难重重。这个问题的根源往往不在于AI模型不够强,而在于我们没有建立一套科学的开发流程。
B站UP主「三少科技」分享了他在实践中摸索出的一套开发经验——通过 Claude Code 和 Codex 的组合使用,实现交叉验证,大幅降低Bug率,同时让代码更加规范。这套方法论对于AI编程新手尤其值得借鉴。
工具选择:为什么是 Claude Code + Codex
顶级工具的必要性
在AI编程工具的选择上,三少科技的态度很明确:直接用顶级工具。他目前主力使用的就是 Claude Code 和 Codex 两款工具,而像 GLM、Kimi 等国产模型则基本不用于编程场景。
这并非否定其他工具的价值,而是基于一个朴素的逻辑——"时间就是金钱"。一个小Bug反复捣鼓半天的成本,远高于使用更好工具的费用。目前 Claude Code 和 Codex 的价格并不算昂贵,但在代码生成和Bug修复方面的效果确实是第一梯队。
两者各有所长,单独使用效果有限
关键洞察在于:这两个工具单独使用都不是最优解,必须配合使用才能发挥最大效果。
三少科技总结了两者的能力差异:
-
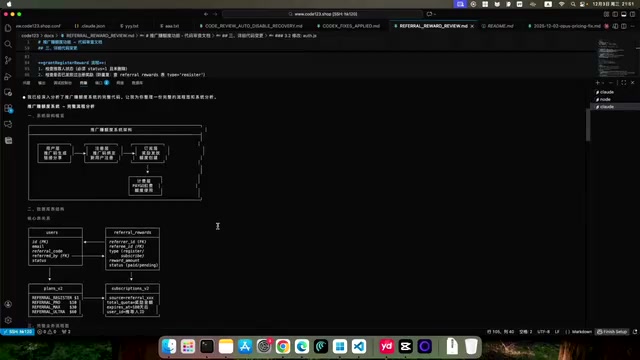
Claude Code:Anthropic推出的命令行AI编程工具,直接在终端中运行,能够读取、编辑本地代码文件,执行shell命令,并与Git等开发工具深度集成。它以Agent模式运行,可以自主规划多步骤任务、浏览项目结构、运行测试,基于Claude Sonnet/Opus模型,在代码生成、架构设计和快速原型开发方面表现突出。它擅长写代码、架构设计,能让程序快速跑起来,开发速度明显优于 Codex。但在实际运行中,经常会产生意想不到的Bug。
-
Codex:这里指的是OpenAI于2025年推出的云端AI编程Agent(区别于早期的Codex代码补全模型)。它运行在OpenAI的云端沙箱环境中,基于o3/o4-mini等推理模型,能够独立完成代码编写、Bug修复、代码审查等任务,并以Pull Request的形式提交结果。在代码理解和逻辑推理方面具有独特优势,特别是在发现代码中的逻辑漏洞和边界条件问题上表现出色。但在架构代码和大规模开发方面不如 Claude Code。甚至有开发者反馈,让 Codex 直接改代码,反而会"把代码改烂"。
简单来说,Claude Code 是更好的"建设者",Codex 是更好的"审查者"。两者搭配使用,才能在AI编程中实现高效且稳定的产出。
核心工作流:开发-审查-修复的迭代循环
第一步:用 Claude Code 分析项目全貌
在开始一个较大的任务之前,首先让 Claude Code 阅读整个项目代码,深入了解系统的运作流程和逻辑关系,并画出流程图。
这一步的目的不仅是让开发者自己理清思路,更重要的是让AI充分理解系统的逻辑关系。经过这轮分析后,AI对系统的了解程度可以达到70%-80%,后续修改代码时会考虑得更加周全。
第二步:用 Claude Code 执行开发任务
分析完成后,直接告诉 Claude Code 具体的开发需求。比如修改某个奖励机制,要求它深入分析后再动手修改。
不过三少科技也坦言,即使明确要求"深入分析",Claude Code 也未必能做到完全全面的修改。这主要受限于当前大模型的 Token 上限——20万 Token 其实非常少。
这里需要理解Token的概念:Token是大语言模型处理文本的基本单位,一个中文字通常对应1-2个Token,一个英文单词对应1-4个Token。当前主流大模型的上下文窗口(Context Window)决定了模型在一次对话中能"记住"多少信息。Claude的上下文窗口为200K Token,看似很大,但对于一个中等规模的代码项目来说远远不够。当输入内容接近上下文窗口限制时,模型会通过滑动窗口或摘要压缩等方式丢弃早期信息,这就是为什么在长代码修改任务中,AI可能会"忘记"之前分析过的代码逻辑,导致修改不完整或引入新Bug。
光是阅读代码和画流程图就可能消耗六七万 Token,到后面修改代码时,上下文就会被自动压缩,导致信息丢失。
他认为,除非未来大模型的 Token 能达到1000万级别,否则真正全面的代码修改仍然难以实现。
第三步:生成代码审查文档(关键衔接)
开发完成后,让 Claude Code 写一份 MD格式的代码审查文档,详细记录:
- 用户的原始需求
- 修改了哪些代码文件
- 整个修改过程的详细说明
这份文档是连接 Claude Code 和 Codex 两个工具的桥梁,也是整个交叉验证工作流中最关键的衔接环节。
选择Markdown格式作为信息传递载体有其深层考量:在多工具协作的工作流中,每个AI工具都有独立的对话上下文,直接让一个工具"看到"另一个工具的完整工作过程是不可能的。通过精心设计的结构化审查文档,可以将关键信息(需求背景、修改范围、技术决策、代码变更点)以最小信息损失的方式传递给下一个工具。这本质上是为AI工具之间建立了一个标准化的通信协议——既保证了信息的完整性,又控制了Token的消耗量,让接收方能够快速理解上下文并进入工作状态。
第四步:用 Codex 进行代码审查
将这份审查文档发给 Codex,要求它深入分析本次修改,发现潜在的Bug,确保系统稳定运行。
Codex 审查完成后,会列出当前系统中存在的问题和潜在Bug。由于 Codex 在代码审查方面的能力更强,它往往能发现 Claude Code 自身难以察觉的问题。
第五步:交叉验证与迭代修复
将 Codex 发现的问题反馈给 Claude Code,让它检查这些问题是否真实存在。三少科技的经验是,大部分情况下 Claude Code 都会承认 Codex 指出的问题确实存在,然后进行修复。
修复完成后,再让 Codex 重新审查更新后的代码,确认问题是否已解决。
经过2-3轮这样的迭代,基本上Bug都能被解决。 这种开发-审查-修复的循环机制,正是交叉验证降低AI编程Bug率的核心所在。
为什么不用 Claude Code 审查 Claude Code
一个自然的疑问是:为什么不用另一个 Claude Code 实例来审查代码,而要引入 Codex?
三少科技的回答很直接:在审查代码的仔细程度上,Claude Code 不如 Codex。 同一个模型审查自己生成的代码,容易陷入"思维盲区",而不同模型之间的交叉验证能更有效地发现问题。
这背后有深层的方法论基础。交叉验证的思想源自软件工程中的代码审查(Code Review)实践和机器学习中的模型集成(Ensemble)方法。在传统软件开发中,代码审查由不同的开发者执行,利用不同人的知识盲区互补来发现问题。将这一思路迁移到AI编程领域,不同模型由于训练数据来源、RLHF(人类反馈强化学习)策略、推理架构的差异,会形成不同的"认知偏差"。Claude系列模型在代码生成时可能倾向于某种编码风格或设计模式,而基于o3/o4-mini的Codex则有不同的推理路径。一个模型生成代码时的盲区,恰好可能是另一个模型的强项,这就是多模型交叉验证能够有效降低Bug率的理论基础。
这个思路其实可以进一步扩展——比如还可以尝试用 Gemini 2.5 Pro 来参与代码审查,形成多模型交叉验证的体系。不同AI模型的训练数据和推理方式存在差异,这种差异恰恰是交叉验证能够奏效的底层原因。
总结与思考
这套工作流的核心思想可以概括为:让擅长建设的去建设,让擅长审查的去审查,通过交叉验证消除盲区。
具体流程为:
- Claude Code 分析项目 → 画流程图,理解系统全貌
- Claude Code 执行开发任务 → 完成代码编写和修改
- Claude Code 生成代码审查文档(MD格式)→ 记录需求和修改详情
- Codex 审查代码 → 找出潜在Bug和问题
- Claude Code 修复Bug → 根据审查结果进行修复
- Codex 再次审查 → 循环直到无Bug
这套方法论的价值不仅在于降低Bug率,更在于它揭示了一个重要原则:在当前AI能力水平下,单一工具难以完美完成所有任务,合理的工具组合和流程设计才是提升效率的关键。 这与软件工程中"关注点分离"(Separation of Concerns)的设计原则不谋而合——将复杂任务拆解为不同的职责,由最适合的角色来承担,最终通过标准化的接口(这里是MD文档)实现协作。
随着大模型 Token 上限的不断提升,未来AI编程的能力边界还会继续扩展,但"交叉验证"的思维方式,在任何阶段都不会过时。
相关推荐
一人+AI Agent团队开发Web游戏:从创意到成品全流程实战
一位开发者通过自研AI Agent协作系统,仅输入一句话创意,自动生成GDD策划文档并产出完整可玩的Web小游戏。本文详解Multi-Agent多角色分工、全流程自动化开发的技术路径与实际效果。
Godot 4开发2D RPG游戏:从零开始的新手实战教程
使用Godot 4引擎和GDScript从零开发2D RPG游戏的完整教程,涵盖瓦片地图搭建、角色控制与动画、敌人AI战斗系统、场景切换等核心模块,适合零基础游戏开发初学者。
Mythos/Fable模型极限压榨指南:10天烧完8000美元推理额度
深度解析Anthropic Fable/Mythos模型的极限使用策略,包括五小时会话限制破解、双账户轮换、多Agent编排工作流、Mac Mini远程部署等实战技巧,教你用200美元订阅费最大化利用推理额度。