Claude Code会保存你的代码吗?隐私政策全解析
深度解析Claude Code等AI编程工具的隐私政策与数据安全风险
文章从数据存储、训练使用、竞品对比三个维度剖析了Claude Code的隐私机制。Claude Code作为代理型AI可直接访问本地文件系统,收集输入代码、AI输出、技术元数据和遥测数据四类信息。数据保留时长因账户类型而异:消费者用户最长5年,商业用户30天,企业用户可申请零数据保留。消费者用户代码默认用于模型训练,商业用户默认不参与。文章还横向对比了Cursor和GitHub Copilot的隐私政策差异。
为什么你应该关心AI编程工具的隐私问题
Claude Code 是 Anthropic 推出的终端 AI 编程助手,能在命令行中帮你写代码、改 Bug、执行命令、管理项目。与普通 AI 聊天不同,Claude Code 可以直接访问你的本地文件系统,读取代码,执行终端命令,甚至操作 Git 仓库。
Claude Code 作为「Agentic AI」(代理型AI)的典型代表,其架构与普通聊天机器人有本质区别。传统AI助手只能在对话框内接收文本输入,而Claude Code通过集成终端环境,获得了对操作系统级别的访问权限。这种设计借鉴了「工具调用(Tool Use)」范式——AI模型不仅能生成文本,还能调用预定义的工具函数来执行真实操作,包括文件读写、Shell命令执行、网络请求等。这种能力使其效率大幅提升,但也意味着一旦发生数据泄露,影响范围远超普通聊天记录,可能波及整个代码库乃至服务器凭证。
正因为这种深度访问能力,隐私问题就显得格外重要——你的代码是核心资产,可能包含商业机密、API 密钥、算法逻辑。了解数据怎么被处理、存到哪里、存多久,是使用任何 AI 编程工具的前提。
最近 Anthropic 更新了隐私政策,不少开发者开始担忧代码安全。本文将从数据存储、训练使用、竞品对比三个维度,彻底梳理 Claude Code 的隐私机制。
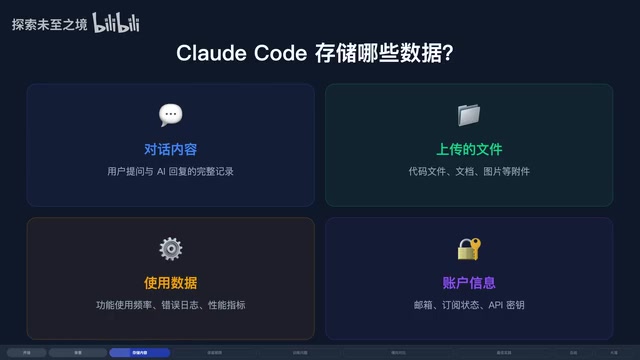
Claude Code 到底会存储哪些数据?
根据 Anthropic 官方隐私政策,Claude Code 收集的数据主要分为四大类:
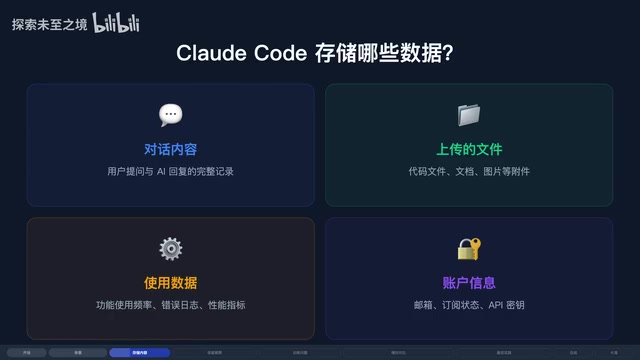
输入数据
包括你发送的提示词、让 Claude 读取的代码片段、项目文件内容,甚至截图和图像输入。这是最核心也最敏感的一类数据,因为它直接包含了你的业务代码。
AI 输出数据
模型生成的代码、回复和建议同样会被记录。输入和输出共同构成了一次完整的交互记录。
技术数据
IP 地址、设备类型、操作系统、浏览器信息、访问时间和使用模式等元数据。这类数据虽然不直接涉及代码内容,但可以用于用户画像。
遥测数据
包括 StatsIG 收集的性能指标、Sentry 记录的错误报告,以及你通过 /feedback 命令提交的反馈。
StatsIG 和 Sentry 是 AI 工具链中广泛使用的两类第三方服务,其数据收集逻辑值得深入了解。StatsIG 是一个功能标志(Feature Flag)和实验分析平台,主要收集用户行为事件、功能使用频率和 A/B 测试数据,帮助产品团队做决策。Sentry 则是错误监控平台,在捕获崩溃报告时可能附带堆栈跟踪信息,而堆栈跟踪有时会包含变量值——这意味着在极端情况下,代码中的局部变量内容可能出现在错误报告里。这两类服务都有各自独立的隐私政策和数据存储位置,形成了「数据流向多个第三方」的复杂局面,这正是通过环境变量关闭遥测的核心价值所在。
数据会存多久?关键看你的账户类型
数据保留时长取决于你的账户类型和隐私设置,差异非常大:
消费者用户(Free / Pro / Max 计划):
- 允许数据用于模型改进:Anthropic 会在训练流水线中保留数据最长 5 年
- 关闭模型改进选项:数据保留期缩短至 30 天,之后自动删除
商业用户(Team / Enterprise / API):
- 标准保留期为 30 天
- 企业用户可申请 Zero Data Retention(零数据保留),输入和输出在实时处理完成后立即删除,不落盘存储
零数据保留(ZDR)并非简单的「不保存文件」,而是一套涉及内存管理和数据流架构的技术承诺。在 ZDR 模式下,用户的输入和模型输出仅在 GPU 推理过程中短暂存在于内存中,推理完成后立即从所有存储层清除,不写入任何持久化存储(数据库、日志系统、缓存层)。这与 GDPR 中的「数据最小化原则」和「存储限制原则」高度契合。值得注意的是,ZDR 通常需要企业与服务商签订数据处理协议(DPA),并在合同层面明确责任边界,而非仅依赖技术手段。这也是为何 ZDR 通常只对企业用户开放——它需要法律合规框架的配套支撑。
需要注意的是,即使开启零数据保留,安全分类器结果仍会保留用于执行使用政策;反馈数据保留 5 年;违规标记的数据最长保留 2 年。
你的代码会被用来训练 Claude 模型吗?
这是开发者最关心的核心问题,答案取决于账户类型和设置。

消费者用户:默认参与训练
Free、Pro、Max 计划的用户,默认情况下聊天和编程会话会被用于改进 Claude 模型。如果你不想参与,必须主动关闭:
访问 Claude.ai → Settings → Data Privacy Controls → 找到「帮助改进 Claude」选项 → 关闭
商业用户:默认不参与训练
Team、Enterprise 和 API 用户默认不会被用于训练,除非你主动加入开发者合作计划并明确授权。
两种例外情况
即使关闭了训练选项,以下两种情况的数据仍可能被使用:
- 对话被标记为安全审查——涉及潜在违规内容时
- 你主动提交了反馈——通过点赞、点踩或
/feedback命令
Claude Code 与 Cursor、GitHub Copilot 隐私政策对比
三大主流 AI 编程工具的隐私政策各有特点,值得横向比较。
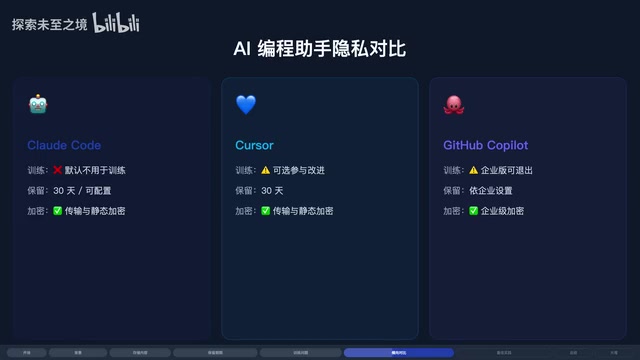
Cursor:隐私控制力度最细
Cursor 提供三种隐私模式:
- 隐私模式:零数据保留,代码不会被 Cursor 或第三方训练
- 非隐私模式:代码可能用于改进功能和训练模型
- 传统隐私模式:同样零数据保留
Cursor 的优势在于给用户明确的模式选择,控制粒度非常细。
GitHub Copilot:政策变化最激进
从 2026 年 4 月 24 日起,Free、Pro 和 Pro+ 用户的交互数据默认用于训练 AI 模型,包括输入、输出、代码片段和上下文。Business 和 Enterprise 用户不受影响。这意味着个人开发者需要主动去设置里退出,否则代码就会变成训练数据。
Copilot 的这一政策调整并非孤立事件,而是整个 AI 行业「数据飞轮」战略的缩影。所谓数据飞轮,是指用户使用产品产生数据→数据用于训练模型→模型能力提升→吸引更多用户的正向循环。对于微软/GitHub 而言,拥有数亿开发者用户意味着潜在的海量代码训练数据。这一政策变化也引发了开源社区的强烈反弹,部分开发者担忧其开源项目代码被用于训练商业模型,形成「用开源代码赚钱却不
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。