Claude Haiku 4.5深度解析:速度翻倍成本降三分之二的性价比之王

Anthropic发布轻量模型Claude Haiku 4.5,以极低成本实现接近旗舰级性能。
Anthropic推出Claude Haiku 4.5,速度提升近一倍,成本降至前代三分之一(每百万输入Token仅1美元)。该模型在部分任务上超越旗舰模型Sonnet 4.5,并支持与Sonnet组成"大脑+手脚"的多智能体协同架构。同时,它在安全对齐方面表现优异,错误拒绝率为同系列最低,已全面上线多个主流云平台。
Anthropic 近日推出了轻量级 AI 模型 Claude Haiku 4.5,作为旗舰模型 Claude Sonnet 4.5 的精简版,它在效率、速度与成本三个维度上实现了全面突破。对于追求高性价比 AI 解决方案的开发者和企业来说,这款模型的发布意义重大。
极致性价比:成本仅为前代三分之一
Claude Haiku 4.5 最引人注目的特点是其惊人的性价比。在保持接近旗舰模型性能的同时,它的速度提升了近一倍,而成本仅为前代的三分之一——每百万输入 Token 仅需 1 美元,输出 Token 仅需 5 美元。

要理解这个定价的含义,首先需要了解 Token 的概念。Token 是大语言模型处理文本的基本单位,一个英文单词通常被拆分为 1-3 个 Token,而一个中文汉字通常对应 1-2 个 Token。AI API 的定价按输入 Token 和输出 Token 分别计费,输出价格通常更高,因为生成文本比理解文本需要更多的计算资源。每百万输入 Token 1 美元的定价,在当前市场中属于极具竞争力的价位,相比 GPT-4o mini 等同级别模型仍有明显优势。
这个定价策略意味着什么?对于一个日均处理百万级请求的企业级应用来说,仅 API 调用成本一项就能节省超过 60%。在当前 AI 应用大规模落地的背景下,成本往往是决定一个项目能否从原型走向生产环境的关键因素。对于客服、内容生成等高频调用场景,Token 成本是运营支出中最大的变量之一,成本差异会被放大数百倍。Haiku 4.5 的出现,实质上降低了 AI 应用的商业化门槛。
性能不打折:部分任务超越旗舰模型
轻量级并不意味着性能妥协。Claude Haiku 4.5 在多项基准测试中表现优异,甚至在部分计算机使用任务上超越了更大型的 Sonnet 4.5,展现出强大的实际应用能力。

AI 模型的基准测试(Benchmark)是衡量模型能力的标准化评估方法,涵盖编程能力(如 HumanEval、SWE-bench)、数学推理(如 MATH、GSM8K)、通用知识(如 MMLU)等多个维度。文中提到的「计算机使用任务」是 Anthropic 近期重点推进的能力方向,指模型直接操控计算机界面完成实际任务的能力,如浏览网页、填写表单、操作软件等。Haiku 4.5 在这类任务上超越 Sonnet 4.5,说明轻量级模型在特定任务上的优化可以弥补参数规模的差距——这也反映了模型训练中「蒸馏」技术的成熟,即将大模型的知识高效压缩到小模型中。
该模型在以下场景中表现尤为突出:
- 编程辅助:代码生成与调试响应迅速,延迟极低
- 实时问答:能够快速理解并回应用户查询
- 客服响应:在高并发场景下保持稳定的响应质量
特别有意思的是,Haiku 4.5 在低延迟方面的表现使其天然适合聊天机器人、智能助手、自动化工作流等对响应速度有严格要求的应用场景。对于需要实时交互的产品来说,用户体验的提升是显而易见的。
多智能体协同:大脑加手脚的新范式
Anthropic 提出了一种颇具前瞻性的混合调用策略:由 Sonnet 4.5 负责复杂推理与任务拆解,再交由多个 Haiku 4.5 并行执行子任务,实现高效协同。
多智能体系统(Multi-Agent System)是当前 AI 架构设计的前沿方向,其核心思想源自分布式计算和微服务架构。在传统的单模型调用模式中,一个请求由一个模型从头到尾处理;而在多智能体模式中,任务被拆解为多个子任务,由不同的 AI 代理(Agent)协同完成。OpenAI 的 Swarm 框架、微软的 AutoGen、以及 LangChain 的 Agent 模块都在探索类似方向。Anthropic 的 Sonnet+Haiku 组合策略的独特之处在于,它利用同一家族模型的 API 兼容性,大幅降低了多智能体编排的工程复杂度。
这种「大脑加手脚」的架构正在成为新一代 AI 系统的设计范式。具体来说:
- Sonnet 4.5 充当「大脑」:负责理解复杂意图、制定执行计划、进行深度推理
- 多个 Haiku 4.5 充当「手脚」:并行执行具体任务,如数据检索、文本生成、代码编写等
这种多智能体编排模式的优势在于,既保留了复杂任务的推理质量,又通过并行化大幅提升了整体执行效率,同时将成本控制在合理范围内。这种架构的技术挑战包括任务分解的准确性、代理间的通信协议设计、结果聚合与冲突解决等,但 Anthropic 通过统一的模型家族生态有效缓解了这些问题。这不是简单的模型替换,而是一种系统架构层面的创新思路。
安全性与透明度:迄今最安全的模型之一
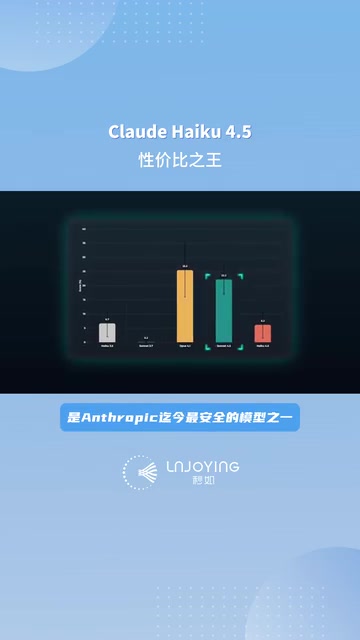
在安全性方面,Haiku 4.5 经过全面对齐测试,其错误拒绝率低于 Sonnet 4.5 和 Opus 4.1,是 Anthropic 迄今最安全的模型之一。
对齐(Alignment)是 AI 安全领域的核心概念,指确保 AI 系统的行为与人类意图和价值观保持一致。错误拒绝率(False Refusal Rate)是衡量模型对齐质量的关键指标之一,指模型错误地拒绝了本应正常回答的合理请求的比例。早期的安全对齐方法往往过于保守,导致模型在面对涉及医学、法律、安全等敏感但合理的问题时频繁拒绝回答,严重影响用户体验。降低错误拒绝率同时保持对真正有害请求的拦截能力,需要在 RLHF(基于人类反馈的强化学习)和 Constitutional AI(宪法 AI,Anthropic 提出的独特对齐方法)等技术上进行精细调优。Haiku 4.5 在这方面的突破意味着它在拒绝有害请求的同时,不会过度拒绝正常的用户需求,在安全与可用性之间取得了更好的平衡。
此外,Anthropic 公开了详细的系统卡(System Card),涵盖训练数据来源、提示工程策略以及在 AIMTerminal Bench 等基准上的完整测试结果。系统卡是 AI 模型发布时附带的技术文档,这一实践最早由 Google 的 Model Cards 和微软的 Datasheets for Datasets 推动,目前已成为负责任 AI 发布的行业标准之一。Anthropic 公开系统卡的做法,与欧盟《AI 法案》等监管框架对 AI 透明度的要求高度契合,也为下游开发者评估模型适用性提供了关键参考依据。这种透明度在行业中并不多见,体现了 Anthropic 对可信赖 AI 的长期承诺。
全平台上线:无缝迁移即刻可用
Claude Haiku 4.5 已全面上线多个主流平台,开发者可以根据自身技术栈灵活选择:
- Claude API:直接调用,适合自建应用
- Claude Code:面向开发者的编程辅助工具
- Amazon Bedrock:AWS 生态内的无缝集成
- Google Cloud Vertex AI:GCP 用户的便捷选择
Amazon Bedrock 和 Google Cloud Vertex AI 是目前两大主流的模型即服务(Model-as-a-Service, MaaS)平台。Bedrock 是 AWS 于 2023 年推出的全托管 AI 服务,允许企业通过统一 API 访问来自 Anthropic、Meta、Mistral 等多家厂商的基础模型,同时提供微调、RAG(检索增强生成)等企业级功能。Vertex AI 则是 Google Cloud 的对应产品,深度集成了 Google 的搜索和数据分析能力。模型同时上线多个云平台的策略,意味着企业无需担心云厂商锁定(Vendor Lock-in),可以根据现有基础设施灵活选择部署方式。
对于已经在使用 Claude 系列模型的开发者来说,迁移成本极低——只需更换 API 端点即可快速切换到 Haiku 4.5,无需修改业务逻辑代码。
总结:AI 平民化的重要一步
Claude Haiku 4.5 的发布代表了 AI 行业的一个重要趋势:顶级 AI 能力正在变得更快、更便宜、更易获取。它不仅是一个性能出色的轻量级模型,更是 Anthropic 构建高效、安全、可协作 AI 生态系统的关键拼图。
对于开发者和企业决策者来说,Haiku 4.5 提供了一个极具吸引力的选项:在不显著牺牲性能的前提下,大幅降低 AI 应用的运营成本。结合多智能体编排策略,它有望推动更多 AI 应用从实验阶段走向大规模生产部署。
核心要点
- Claude Haiku 4.5 速度提升近一倍,成本仅为前代三分之一,每百万输入Token仅需1美元
- 在部分计算机使用任务基准测试中超越了更大型的旗舰模型Sonnet 4.5
- Anthropic提出Sonnet+Haiku的多智能体编排策略,形成大脑加手脚的新型AI系统架构
- 经过全面对齐测试,错误拒绝率低于同系列其他模型,是Anthropic迄今最安全的模型之一
- 已全面上线Claude API、Amazon Bedrock、Google Cloud Vertex AI等主流平台,支持快速迁移
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。