Claude Mythos Preview基准测试成绩曝光:时间跨度超次优模型2倍

Claude Mythos Preview在METR基准测试中时间跨度超次优模型2倍以上,标志AI Agent能力质变。
Anthropic的Claude Mythos Preview早期快照在METR 80%成功率基准测试中,任务时间跨度超过次优模型2倍以上。时间跨度是衡量AI Agent可靠处理复杂多步骤任务的关键指标,考验上下文管理、误差控制和层次化规划能力。这一成绩标志着AI从简单指令执行向自主完成复杂项目的质变,且作为早期快照,正式版可能更强。Anthropic将模型交由独立机构评估,也体现了其安全透明的开发理念。
Claude Mythos Preview核心突破:时间跨度超越次优模型2倍以上
Anthropic近日透露了一个令人瞩目的消息:他们提供给METR(Model Evaluation & Threat Research)的一个早期Claude Mythos Preview快照,在METR的80%成功率基准测试中,其时间跨度(time horizon)超过了次优模型的2倍以上。
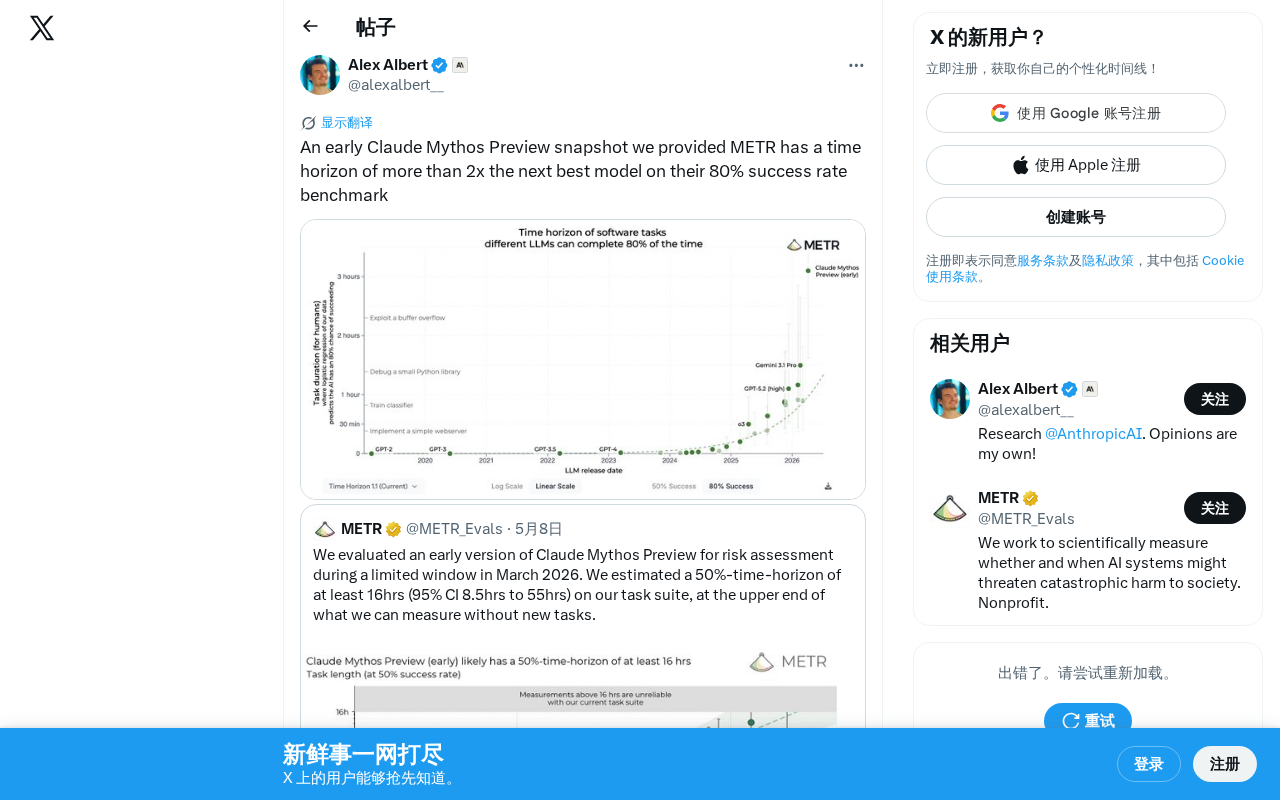
这一数据意味着,Claude Mythos Preview能够在保持80%成功率的前提下,处理时间跨度远超其他模型的复杂任务——这是衡量AI Agent能力的关键指标之一。
METR基准测试是什么?为什么它如此重要?
METR成立于2023年,是从对齐研究中心(ARC,Alignment Research Center)独立出来的非营利机构,专注于前沿AI模型的能力评估与威胁研究。与许多依赖合成数据集的传统基准不同,METR的评估方法论强调真实世界任务——测试场景通常涵盖代码编写、系统调试、网络搜索、文件操作等需要工具调用和多轮决策的复合任务,力求还原AI在实际部署环境中的表现。
其中,**时间跨度(time horizon)**是METR体系中的核心指标,它衡量的是模型能够可靠完成的任务所需的时间长度。这一指标的设计灵感来源于人类工作者的"任务完成时间"概念:一个需要人类工程师花费30分钟完成的任务,与需要花费3小时的任务,对AI的规划能力、上下文维持能力和错误恢复能力的要求有本质差异。
具体来说,METR的80%成功率基准测试关注的是:在保证至少80%任务成功率的条件下,模型能够处理多长时间跨度的任务。这一80%阈值的设定并非随意——它反映了工业应用对可靠性的基本要求,低于这一阈值的模型在生产环境中往往需要大量人工监督,难以实现真正的自动化价值。时间跨度越长,意味着模型具备以下能力:
- 维持更长时间的连贯推理,不会在多步骤任务中迷失方向
- 处理更复杂的工作流程,包括需要长时间规划和执行的任务
- 展现更强的自主Agent能力,在真实世界场景中具备更高的实用价值
时间跨度背后的技术挑战
时间跨度指标之所以难以突破,在于它同时考验着模型的多个深层技术能力。首先是上下文的有效利用:长时间跨度任务往往产生大量中间状态和历史记录,模型需要在有限的上下文窗口内始终保持对任务目标的准确追踪。其次是复合误差效应:多步骤任务中,早期的微小偏差会随步骤增加而指数级放大,最终导致任务失败。第三是层次化规划能力:长时间跨度任务要求模型能够将宏观目标分解为可执行的子任务,并在执行过程中根据实际情况动态调整计划。Claude Mythos Preview能够将这一指标提升2倍以上,意味着其在上述三个维度上均有显著突破。
Claude Mythos Preview的测试成绩意味着什么?
AI Agent能力从量变到质变
超过次优模型2倍以上的时间跨度,不是一个渐进式的改进,而是一个显著的跨越。在AI Agent领域,时间跨度的延长往往意味着模型从"能完成简单指令"跃升到"能自主执行复杂项目"。
这一跨越有着清晰的行业背景。AI Agent赛道在2024-2025年间经历了从概念验证到实际部署的关键转型期。早期的Agent框架(如LangChain、AutoGPT)受限于基础模型能力,往往在超过5-10步的任务中出现显著的性能衰减。随着OpenAI推出o系列推理模型、Google发布Gemini 2.0 Flash等具备原生工具调用能力的模型,以及Anthropic推出Computer Use功能,Agent能力的竞争已从"能否执行工具调用"升级为"能否可靠完成企业级复杂工作流"。在这一背景下,METR的时间跨度基准测试成为行业公认的能力标尺之一。
当一个模型能够可靠地处理更长时间跨度的任务时,它在软件开发、研究辅助、数据分析等需要持续多步骤推理的场景中,将展现出截然不同的实用价值。
Anthropic在Agent赛道上拉开差距
有意思的是,Anthropic强调这还只是一个"早期快照"(early snapshot),而非最终版本。这意味着Claude Mythos Preview在正式发布时可能还会有进一步的提升。在当前OpenAI、Google、Anthropic三方竞争日趋激烈的背景下,这一成绩无疑为Anthropic在Agent能力赛道上确立了显著的领先优势。
第三方评估彰显安全透明理念
将早期模型快照提供给METR这样的独立评估机构进行测试,也体现了Anthropic一贯强调的安全与透明理念。这一做法与其**"负责任扩展政策"(Responsible Scaling Policy,RSP)**密切相关——这是Anthropic于2023年发布的内部治理框架,要求在模型达到特定能力阈值前必须完成安全评估。METR作为独立第三方,其评估结果不受开发商商业利益影响,能够提供更客观的能力画像。
值得注意的是,这种做法在行业内尚未成为普遍标准——大多数AI公司仍主要依赖内部基准测试发布性能数据。随着欧盟AI法案和美国行政令开始要求高风险AI系统接受第三方审计,Anthropic的这一实践具有超越单纯技术展示的行业示范意义,通过第三方独立评估来验证模型能力,既增强了结果的可信度,也为行业树立了负责任的AI开发范例。
Claude Mythos Preview后续展望
Claude Mythos Preview的这一表现,预示着AI Agent能力正在进入一个新的阶段。随着模型能够可靠处理越来越长时间跨度的复杂任务,AI从"对话工具"向"自主工作伙伴"的转变正在加速。
不过,我们也需要等待更多细节的披露——包括具体的任务类型、测试条件,以及与其他模型的详细对比数据——才能更全面地评估这一突破的实际意义。Claude Mythos Preview的正式发布值得密切关注。
核心要点
- Claude Mythos Preview早期快照在METR 80%成功率基准测试中,时间跨度超过次优模型2倍以上
- METR是专注于真实世界任务评估的独立非营利机构,其时间跨度指标同时考验模型的上下文管理、错误恢复和层次化规划能力
- 时间跨度是衡量AI Agent自主执行复杂多步骤任务能力的关键指标,80%成功率阈值反映了工业部署的基本可靠性要求
- 这仅是早期快照版本,正式发布时可能还有进一步提升
- Anthropic将模型提供给独立评估机构METR测试,与其"负责任扩展政策"一脉相承,体现了安全透明的开发理念
- 该成绩标志着AI Agent能力正从简单指令执行向自主完成复杂项目的方向质变
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。