Claude顾问策略:小模型执行大模型把关,AI Agent省钱提效新范式
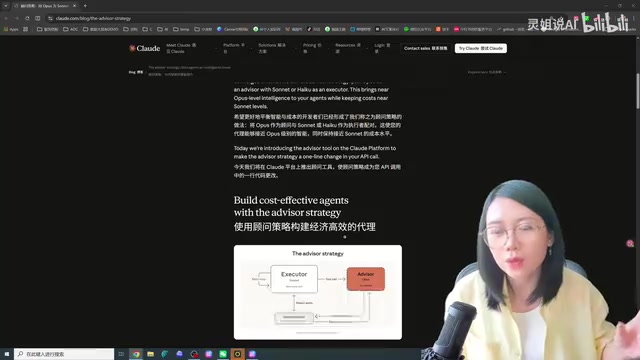
Anthropic提出顾问策略:小模型执行+大模型当顾问,花更少钱做更好事。
Anthropic发布的Advisor Strategy颠覆了AI Agent"无脑选最强模型"的思路。该策略让低成本模型(Sonnet/Haiku)负责主循环执行,仅在关键决策节点咨询高能力模型(Opus)作为顾问。实测显示成本降低12%而SWE-Bench分数反而提升2.7个百分点。这标志着AI竞争从"拼模型能力"转向"拼智能组织方式"的范式转变。
别再无脑选最强模型了
AI Agent时代,很多人选模型的策略非常简单粗暴——无脑堆最强模型。用Codex就选GPT-5.5,用Claude Code就选Opus。但Anthropic在4月9日发布的一篇博客,提出了一种名为**Advisor Strategy(顾问策略)**的全新Agent运行范式,彻底颠覆了这种思路:花更少的钱,反而能做更好的事。
这不仅仅是一个省钱技巧,更是一种对AI Agent组织方式的深层思考,对企业AI落地和个人开发者都极具参考价值。
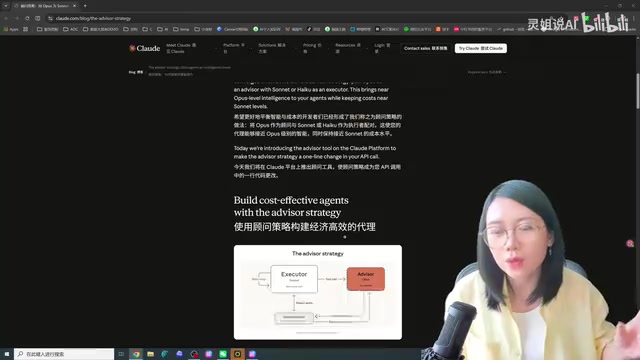
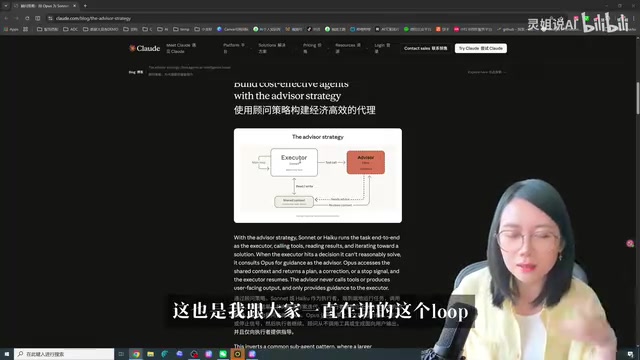
什么是Advisor Strategy(顾问策略)?
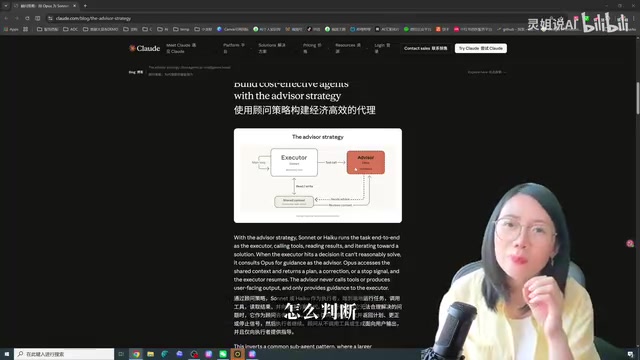
核心思路:小模型执行,大模型当顾问
传统的Agent运行范式是「强模型主导」——让最聪明的模型(如Opus)做总规划,Sonnet做子任务,Haiku做简单执行。这套逻辑的底层假设是:主循环必须由最强模型来驱动。
这里需要理解Anthropic的Claude模型家族的分层设计:Opus是旗舰级推理模型,擅长复杂分析和多步推理,但调用成本最高、响应延迟也最大;Sonnet是性能与成本的平衡之选,适合大多数日常任务;Haiku则以极低延迟和成本著称,适合轻量级任务。这种分层架构本身就暗示了多模型协作的可能性——不同层级的模型在不同环节各司其职,而非一刀切地使用同一模型。
而Claude的Advisor Strategy完全反过来:
- 执行者(Main Loop):由Sonnet或Haiku担任,负责端到端执行任务——调用工具、读取结果、反复推理
- 顾问(Advisor):由Opus担任,只在执行者遇到无法理解或解决的关键决策时被咨询,返回计划修正建议或停止信号
所谓Agent的主循环(Main Loop),是指Agent持续运行的核心执行流程:接收任务→思考下一步行动→调用工具(如代码执行器、文件读写、API调用等)→观察工具返回结果→再次思考→继续行动,如此循环直到任务完成。这个循环可能执行数十甚至数百轮,每一轮都会消耗模型的推理Token。因此,主循环使用的模型直接决定了整体成本——如果用Opus跑主循环,每一轮的推理成本都很高;而用Sonnet或Haiku来跑,单轮成本可以降低数倍甚至十倍以上,累积下来的节省非常可观。
Opus不直接调用工具,不直接输出给用户。它的角色更像一个外部专家顾问——不亲自干活,只在关键节点给方向、纠偏、建议停止。
数据说话:成本降低12%,效果反而更好
博客中给出了具体的对比数据:
| 方案 | SWE-Bench 分数 | 成本 |
|---|---|---|
| Sonnet 4.6 / Haiku 单独执行 | 72.1 | $1.09 |
| Sonnet 4.6 执行 + Opus 顾问 | 74.8 | $0.96 |
成本降低了约12%,SWE-Bench分数反而提升了2.7个百分点。
这里有必要解释一下SWE-Bench这个基准测试的含金量。SWE-Bench是由普林斯顿大学研究团队于2023年发布的软件工程基准,专门用于评估大语言模型解决真实世界GitHub Issue的能力。它从Django、Flask、scikit-learn等12个热门Python开源项目中提取了数百个真实的bug修复和功能请求任务,要求模型在理解问题描述后自主生成代码补丁。由于任务来源于真实的软件工程场景,SWE-Bench被广泛认为是衡量AI编程Agent实际能力的黄金标准。72分以上意味着模型能够独立解决超过七成的真实软件工程问题,在这一高难度基准上,2.7个百分点的提升属于相当显著的进步。
花更少的钱做更好的事情,这就是顾问策略的威力所在。
为什么顾问策略如此有启发性?
从「谁聪明谁主导」到「谁稳定谁主导」
这个策略的意义远不止省钱。它提供了一种全新的Agent运行范式:
- 旧范式:谁更聪明,谁做主位(强模型=总指挥)
- 新范式:谁便宜、稳定、能跑流程,谁做主位(执行模型=主循环)
想想看,这和真实的商业环境何其相似——普通员工负责日常工作的推进,遇到拿不准的重大判断时,再请外部专家来看一眼。专家不亲自干活,只给方向、纠偏、建议停止。这本质上就是一个精神导师式的角色。
值得注意的是,多Agent协作并非Anthropic首创的概念。早在2023年,斯坦福大学的「生成式Agent」论文就展示了多个AI角色协作完成复杂任务的可能性。此后,微软的AutoGen框架、CrewAI、LangGraph等开源项目都在探索不同的多Agent编排模式,包括层级式(Hierarchical)、对等式(Peer-to-Peer)、流水线式(Pipeline)等。顾问策略的独特之处在于它引入了一种「非对称协作」模式——顾问模型不参与执行流程,只在被显式咨询时介入,这大幅减少了模型间通信的开销,同时保留了高质量决策的能力。这种设计哲学与微服务架构中的「边车模式(Sidecar Pattern)」有异曲同工之妙。
AI竞争进入「智能组织」新阶段
从顾问策略的发布可以看到,AI行业的竞争正在从模型能力竞争转向智能组织方式的竞争。不再是单纯比谁的模型跑分高,而是比谁能用更低的成本实现同等甚至更好的效果。
这意味着未来会出现一个必拼的方向:智能算力预算分配。AI的成本治理不是少用AI,也不是土豪式地全部用最贵模型,而是建立一套分层的调用机制。
事实上,这一方向已经在行业中快速升温。OpenAI、Google、Anthropic等厂商都在推动模型路由(Model Routing)技术的发展——即根据任务的复杂度、风险等级和成本预算,自动将请求分发到最合适的模型。一些第三方平台如Martian、Unify等已经专门提供智能路由服务。Gartner预测,到2026年超过60%的企业AI部署将采用多模型混合架构,而非依赖单一模型。顾问策略可以看作是这一趋势在Agent领域的具体落地实践。
实战指南:四大场景如何选择模型策略?
顾问策略和传统的「强模型主导」策略并不冲突,它们适用于不同的场景。以下是四种典型场景的策略选择建议。
场景一:方向不清楚 → 强模型主导
如果你做的事情方向不明确,涉及大量战略决策,比如:
- 企业AI转型方向的判断
- 产品战略的制定
- 视频选题的决策
这类「看不清方向」的任务,更适合用强模型做主导,因为它需要的是高质量的判断力。
场景二:方向清楚但过程很长 → 执行模型 + 强模型顾问
如果方向已经明确,但执行过程很长,比如:
- 各平台的分发文案撰写
- 批量跑测试用例
- PPT的初稿生成
这类任务完全可以让Sonnet或Haiku一直跑,遇到卡点再请Opus来修正方向。这正是Advisor Strategy的最佳应用场景。
以Codex为例,这是OpenAI于2025年推出的云端AI编程Agent产品,定位为「数字软件工程师」。与传统的代码补全工具不同,Codex能够在独立的云端沙箱环境中自主完成完整的编程任务:阅读代码库、理解需求、编写代码、运行测试、提交PR。每个Codex任务实例本质上就是一个运行中的Agent主循环,单次任务可能涉及数百轮工具调用和推理。在这种长时间运行的场景中,模型选择对成本的影响被成倍放大,顾问策略的价值也因此被充分体现。
场景三:任务简单但结果风险高 → 普通模型执行 + 强模型验收
有些任务本身不复杂,但结果的风险很高——你必须为最终结果买单:
- 给客户的报价和提案
- 重要邮件的措辞
- 对外发布的正式文档
这时候让普通模型执行,强模型的角色不是给建议,而是验收把关。发出去一锤定音,AI不为结果买单,人要为结果买单。
场景四:容易出错但容错率高 → 多模型并行
如果任务容易出错但错了也不要紧,比如:
- 生成方案图
- 写提示词文档
- 产出多个标题做A/B Test
这时候可以让多个模型同时跑,模型之间不需要顾问角色,只需要在最后有一个评审员对结果进行评分。评分体系可以是自评、他评,甚至多个专家团评。
更深层的启示:Agent系统像一个组织
顾问策略的思想,本质上揭示了一个趋势:未来的AI Agent系统更像一个组织,而不是一个单体大脑。
一个高效的组织,并不是每件事都让最贵的人做、最聪明的人做。但组织里也不能没有专家、没有精英。一个成熟的Agent系统应该是:
- 让普通执行者持续推进日常任务
- 让专家只出现在最关键、最值钱、最容易犯错的节点
这套思想不仅适用于Claude的多模型切换,同样可以复用在:
- Codex的数字员工调度——在长时间自主编程任务中,用轻量模型跑主循环,关键架构决策时调用旗舰模型
- Claude Code的多Agent协作——多个Agent实例并行处理不同模块,共享一个高级顾问进行全局一致性审查
- 多模型工作流的架构设计——借鉴微服务中的边车模式和网关模式,构建灵活的模型路由层
- 企业AI落地的方法论制定——将智能算力预算分配纳入IT治理框架,建立模型调用的分级审批和成本监控机制
总结
Claude的Advisor Strategy看似只是一个模型调度的小技巧,实则标志着AI Agent领域从「拼模型能力」到「拼智能组织方式」的范式转变。在算力资源日益紧张的今天,谁能用更低的成本实现更好的效果,谁就能在Agent时代占据优势。
对于每一个AI实践者来说,现在就可以开始构建这样一套分层调度的系统——不需要等待自动化工具的到来,理解了顾问策略的核心思想,手动配置也能立刻见效。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。