CodeGraph:给编程智能体一张代码地图,省47%Token
编程智能体的真正瓶颈:代码理解成本
当你把一个bug丢给Claude Code、Cursor或Codex时,模型通常不会一上来就知道答案。它会先搜索关键词,再打开路由文件,再追Controller,再追Service,再追Repository——中间还可能翻到类型定义、测试文件、配置文件。运气好时很快找到主路径,运气差时在grep、glob、read之间来回折返,把大量无关代码塞进上下文。
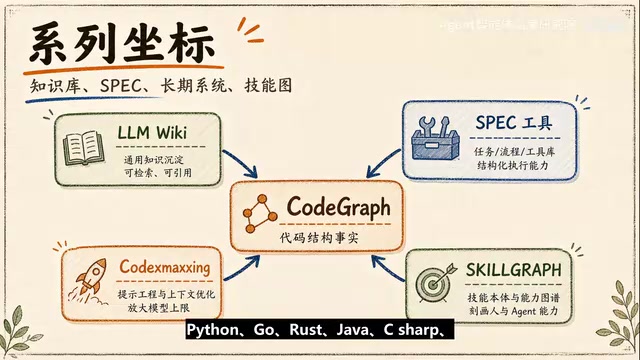
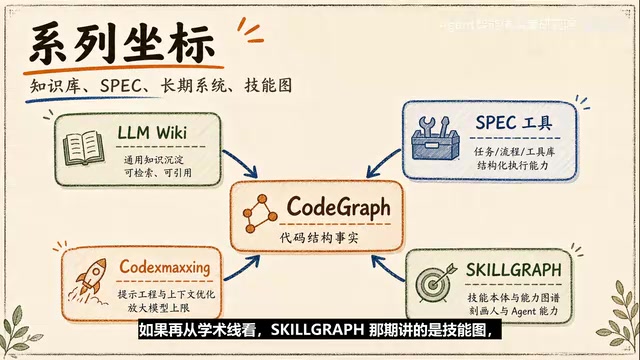
这正是在GitHub上获得约4万星的开源项目CodeGraph想解决的问题。它的核心思路很朴素:既然Agent每次进项目都要重新认路,那就提前把代码库读一遍,把函数、类、方法、调用关系、导入关系、继承关系、文件结构整理成一张本地可查询的代码地图。等Agent真正要做任务时,先查地图,再决定要不要读具体文件。
这个转变的关键在于:CodeGraph把"认识代码库"这件事从临时搜索变成了工程索引。Agent少靠猜,多靠已经整理好的代码事实来判断下一步。
CodeGraph的四步工作机制
第一步:抽取(Extract)
CodeGraph使用Tree-sitter解析源码。Tree-sitter是一种面向代码编辑器和代码工具的语法解析器,它会把源码变成AST(抽象语法树)。然后CodeGraph用不同语言的查询规则,从AST里抽出函数、类、方法、类型这些节点,再抽出调用、导入、继承、实现这些边。
第二步:存储(Store)
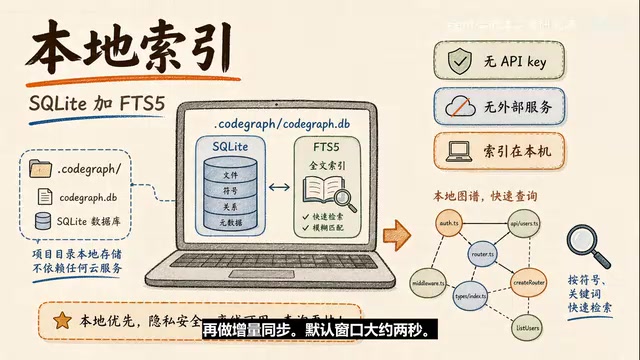
抽出来的节点和关系会进入项目本地的SQLite数据库,存放位置是.codegraph/codegraph.db。它还使用FTS5做全文搜索——FTS5是SQLite的全文检索能力,所以你既能查符号关系,也能按名字快速搜索代码实体。
第三步:解析(Resolve)
只抽到一个函数调用还不够。真正有用的是把调用连到定义,把import连到文件,把继承关系连到父类,把框架路由连到Handler。官方文档还提到,它会对一些动态分发边界做"补桥"——比如回调、React重新渲染、接口到实现,以及一些移动端和跨语言场景。
这里有一个重要边界:这些补出来的边并不等同于编译器级证明,官方会给heuristic类来源做标记,意思是它有工程价值,但你要知道它来自启发式规则。
第四步:同步(Sync)
CodeGraph作为MCP Server运行后,会用系统文件监听(macOS上是FSEvents,Linux上是inotify,Windows上是ReadDirectoryChangesW)项目里的源码变更。文件变更不会立刻重建图,而是经过一个短暂防抖窗口(默认约2秒)再做增量同步。
与普通代码搜索的本质区别
CodeGraph通过MCP Server暴露给Agent的工具很直接:
- Search:找符号
- Callers:看谁调用了某个函数
- Callees:看某个函数又调用了谁
- Impact:分析改一个符号可能影响哪里
- Files:查索引到的文件结构
- Trace:追踪请求从入口到下游的完整路径
普通搜索从文本开始——你搜一个关键词,得到一堆文件,再靠模型读文件和猜关系。CodeGraph从符号和关系开始,让Agent先看到谁定义了这个东西、谁调用了它、它又连向哪里。读源码仍然需要,只是读取范围会明显缩小。
举个例子:如果你问一个接口请求怎么一路走到数据库,普通搜索可能先从路由关键字开始一层层读文件。CodeGraph的路径是先找路由节点和Handler,再沿调用边看Controller → Service → Repository → 数据库访问函数。Agent拿到的是一条候选路径,不再只是一堆散落文件。
实测数据:省了多少Token?
官方README给出了一组Benchmark(用Opus 4.8重新验证):让Claude Code Headless模式在7个真实开源仓库里回答架构问题,每个仓库有/无CodeGraph两组,每组4次取中位数。
平均结果:
- 成本降低16%
- Token减少47%
- 时间快22%
- 工具调用减少58%
两个值得注意的细节:
第一,这组数字和一些早期文章里的说法(如"少烧57% Token、成本降低25%")不完全一样,官方页面有多个历史口径,最新README采用的是上述这组。
第二,这组数据有明确适用范围——测试的是Claude Code Headless + Opus 4.8 + 7个开源项目 + 架构理解问题。你的项目语言、代码风格、Agent是否真的调用CodeGraph、问题是不是结构性问题,都会影响收益。
支持范围与安装要点
语言支持已覆盖:TypeScript、JavaScript、Python、Go、Rust、Java、C#、PHP、Ruby、C/C++、Swift、Kotlin、Scala、Dart、Svelte、Vue、Lua等。
框架路由识别包括:Django、Flask、FastAPI、Express、NestJS、Rails、Spring、Gin、ASP.NET、React Router、SvelteKit等。
安装层面只需记住两层:先把CodeGraph接到你的Agent(支持Claude Code、Cursor、Codex CLI、Gemini CLI等),再在每个项目里建本地索引。
一个非常值得注意的设计选择:本地优先。CodeGraph不需要API key,不依赖外部服务,索引存在本机SQLite数据库里。对私有仓库、企业代码来说,这很关键。不过要讲准确——CodeGraph自己的索引和MCP服务是本地的,但如果你使用的是云端Coding Agent,后续Agent把哪些代码片段发给模型处理,取决于那个Agent的运行方式和权限设置。
CodeGraph的工程定位与边界
我更愿意把CodeGraph看成Agent工程化的一块基础设施。它不负责写更漂亮的代码,也不负责判断需求该不该做,它负责让Agent在动手之前先看清地形。
它改变了什么:
- 日常问答更接近结构查询——过去问"这个函数谁在用",Agent可能先搜文件;现在它可以先查callers
- 影响分析更容易前置——Impact工具先把影响半径摆出来,再决定测试哪些地方
- Agent的上下文更干净——无关信息变少,回答更容易贴着主路径走
- 索引新鲜度可纳入工作流——status、自动同步、增量更新都围绕"Agent查到的关系是不是最新的"设计
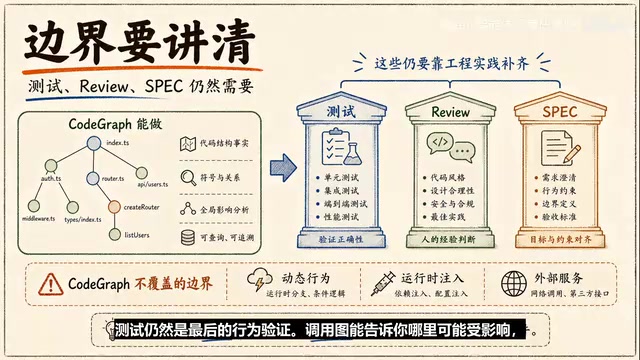
但它也有明确边界:
- 动态行为仍要谨慎看:反射、运行时注入、复杂依赖容器、数据库schema、外部服务调用,都可能超出静态图谱能力
- 测试仍是最后的行为验证:调用图能告诉你哪里可能受影响,测试才能告诉你行为有没有坏
- 依赖Agent的使用习惯:如果Agent继续无脑全文搜索,收益会被吃掉。企业最好把使用规则写进Agent指令里
- 图谱需要保持干净:索引要排除依赖目录、构建产物、缓存文件和大文件
为什么编程智能体需要代码地图?
编程智能体正在从"帮我补几行代码"走向"帮我理解一个系统并安全修改它"。模型能力越强,探索成本就越显眼。过去你可能觉得Agent多读几个文件无所谓,现在一个任务里可能有多个Agent、多个阶段、多个反馈循环,重复探索会变成实打实的时间、费用和错误来源。
CodeGraph给出的答案很工程化:把代码结构提前抽出来,存在本地,让Agent查询它。它没有承诺AI自动写完整个系统,也没有把问题包装成玄学——它把一个很具体的痛点(代码理解成本)转成了一个可以落地的索引问题。
如果你已经在用Claude Code、Cursor或Codex写真实项目,CodeGraph最适合那些Agent经常迷路的老项目:路由很多的后端系统、前后端混在一起的应用、调用层级很深的业务代码、或者多人维护多年后结构很难靠文件名猜出来的仓库。
一句话收住:CodeGraph的意义是让编程智能体先拥有更好的代码地图,再决定需要多少上下文。 未来Coding Agent的竞争,可能不只看模型多会写,还会看它在动手之前能不能更快、更准、更省地理解项目。
相关推荐
Claude Fable 5全球封禁:AI经济链条断裂危机深度解析
Claude Fable 5发布三天即遭美国政府封禁,仅限美国公民使用。深度分析越狱争议背后的真实动机、全球AI供应链断裂风险、Anthropic恐惧营销反噬,以及普通用户应对策略与本地AI部署方案。
Claude Fable 5实测:Token翻倍值不值?Rust编程对比Opus 4.8
通过Rust模拟项目实测对比Claude Fable 5与Opus 4.8的编程能力。Fable 5消耗两倍Token,输出质量仅略有提升,且存在稳定性问题。详细分析两款模型的规划、编译、功能完整性差异,帮助开发者做出合理的模型选择。
编译优先:用AI盘活硬盘里沉睡的本地资料
深入解析LLM Wiki开源项目如何基于编译优先范式,将硬盘中沉睡的本地文件自动编译为可检索的AI知识库。对比传统RAG方案,了解本地化、透明化的个人知识管理新方式。