CodeRAG技术解析:四大核心组件让AI真正读懂你的代码库

CodeRAG通过四种技术协同让AI编程助手真正理解企业代码库
CodeRAG是面向代码的检索增强生成技术框架,通过向量相似度搜索(捕捉代码语义)、文件系统工具(模拟程序员导航)、代码知识图谱CKG(揭示代码间结构与依赖关系)和DeepWiki(整合设计意图与历史知识)四种技术的协同,让AI编程助手的输出真正扎根于真实代码语境,解决大模型的幻觉问题,实现可靠、可追溯的代码生成与理解。
引言:AI编程的核心挑战
AI编程助手如今越来越强大,从写代码、改Bug到代码审查,似乎无所不能。但一个核心挑战始终存在:这些AI怎么才能真正理解企业内部那个堆积如山、错综复杂的代码库?
光靠大模型自身的参数记忆去"猜"显然不行,经常会产生幻觉——给出看似正确但根本跑不起来的代码。CodeRAG(面向代码的检索增强生成)正是为解决这个问题而生的技术框架,其核心目标只有一句话:让AI的回答真正扎根在真实的代码语境当中。
RAG(Retrieval-Augmented Generation)最早由Facebook AI Research在2020年提出,其核心思想是在大语言模型生成答案之前,先从外部知识库中检索相关信息作为上下文输入。这一范式解决了大模型的两个根本性缺陷:参数化记忆的时效性问题(训练数据有截止日期)和幻觉问题(模型会自信地编造不存在的信息)。在代码领域,幻觉的危害尤为严重——一个看似合理但实际不存在的API调用可能导致编译失败甚至运行时崩溃。CodeRAG将RAG范式专门适配到代码场景,需要处理代码特有的结构性(AST、作用域、类型系统)和语义多层性(自然语言注释与形式化代码逻辑的交织)。
本文将CodeRAG拆解为四种技术实现形式,看看它们如何协同工作。
向量相似度搜索——CodeRAG的语义灵魂
向量相似度是CodeRAG最基础的能力。它的工作原理是将用户的问题(比如"如何实现一个二分查找")和代码库里成千上万个代码片段,全部转换成数学向量。然后不是做简单的关键词匹配,而是在高维空间里寻找与问题语义最相近的代码。
为了提升准确度,现在通常会使用专门为代码场景优化过的Embedding模型,它能同时理解自然语言的意图和代码的结构特征。这类模型(如微软的CodeBERT、GraphCodeBERT,以及OpenAI的text-embedding系列)将代码片段映射到通常768至1536维的向量空间中。与通用文本Embedding不同,代码Embedding需要同时捕捉三个层面的信息:词法层面(变量名、关键字)、语法层面(AST结构、控制流)和语义层面(代码的实际功能意图)。例如,一个用Python写的快速排序和一个用Java写的快速排序,虽然文本完全不同,但在向量空间中应该彼此接近。向量相似度通常使用余弦相似度或内积来衡量,配合FAISS、Milvus等向量数据库可实现毫秒级的近似最近邻搜索。

Cursor的实现案例
AI驱动的IDE Cursor就是一个典型案例,它的实现流程非常精巧:
- 客户端智能同步:本地客户端将代码库中发生变化的部分同步到云端服务器,进行向量化处理并建立索引
- 云端向量匹配:用户提问时,查询在云端通过向量匹配找到最相关代码片段的地址(文件路径和行号),但不传回代码本身
- 本地代码提取:客户端根据返回的地址,在本地把真实代码捞出来
- 打包推理:将问题和相关代码一起发送给大模型进行推理
这个流程巧妙地在效率与隐私安全之间找到了平衡点——敏感代码始终留在本地,云端只处理向量索引。增量同步机制(只同步变化部分)大幅降低了带宽消耗和索引重建成本——对于动辄数百万行代码的企业级仓库,全量重建索引可能需要数小时。其"索引在云端、代码在本地"的分离架构借鉴了搜索引擎的倒排索引思想:云端只存储向量和对应的文件位置元数据,不存储代码原文。这种设计对于金融、医疗等对代码安全性要求极高的行业尤为重要,因为它满足了数据不出域的合规要求,同时又能利用云端GPU集群的算力进行高效的向量检索。
文件系统工具——模拟程序员的导航习惯
光有语义理解还不够。一个优秀的程序员不会一上来就把整个代码库都读一遍,而是先看目录结构,再找关键文件,然后读文件大纲,最后才定位到具体代码行。
CodeRAG的第二个基石就是文件系统工具,它给AI智能体提供了一套类似人类程序员会用的工具集:
- FileTree:查看目录树结构
- FileOutline:查看单个文件的大纲
- ReadLines:按行号精确读取文件内容
- SearchInFolders:在文件夹中做关键词搜索

文件系统工具的设计遵循了AI Agent(智能体)的Tool-Use范式。在这一范式中,大语言模型不再是单纯的文本生成器,而是一个能够规划和执行多步操作的决策者。模型通过Function Calling机制选择合适的工具、构造参数、执行调用、解析结果,然后决定下一步行动。这种ReAct(Reasoning + Acting)循环让AI能够像人类程序员一样进行渐进式的代码探索:先用FileTree了解项目全貌,再用FileOutline定位关键模块,最后用ReadLines精确获取所需代码。相比一次性将整个代码库塞入上下文窗口,这种按需检索的方式极大地节省了token消耗,也避免了"大海捞针"式的注意力稀释问题——研究表明,当上下文过长时,模型对中间位置信息的关注度会显著下降(即"Lost in the Middle"现象)。
两大基石的协同价值
向量相似度让AI能"听懂话外之音",理解用户的真实意图,而不是傻傻做文本匹配。文件系统工具则把AI从一个信息过载的溺水者,变成了一个有条不紊的工程师——让AI的探索行为变得和人类程序员一样有逻辑、可追溯。
语义理解 + 工程导航的组合,是CodeRAG高效可靠处理海量代码的基础。
代码知识图谱(CKG)——从文本到可推理的网络
单纯的语义匹配和文件导航还不足以揭示代码之间错综复杂的关系。比如:一个函数的修改会影响哪些下游服务?一个API的废弃会波及哪些模块?
代码知识图谱(Code Knowledge Graph, CKG)就是为解决这类问题而生的。你可以把它想象成一张描绘整个代码世界的"活地图":
- 节点:代码中的关键元素(类、函数、接口、数据库表等)
- 边:元素之间的关系(调用、继承、读写等)

CKG的构建通常依赖静态分析工具链。对于不同编程语言,会使用对应的解析器(如Tree-sitter支持40+种语言的增量解析、Language Server Protocol提供跨编辑器的语义分析能力)提取AST(抽象语法树),再通过符号解析建立跨文件的引用关系。图数据库(如Neo4j、TigerGraph)或属性图模型用于存储和查询这些关系,支持Cypher或GSQL等图查询语言进行复杂的路径遍历和模式匹配。
CKG的三大核心价值
- 检索更精准:可以直接查询"哪些函数调用了CreateUser接口并最终写入了数据库"这种基于关系的复杂问题
- 上下文组织更合理:只把真正相关的代码片段喂给模型,避免token浪费
- 答案可验证可追溯:每个关系都能找到源头,大大降低AI"胡说八道"的风险
字节跳动开源的TreeAgent就是CKG在本地实现的一个典型案例。TreeAgent通过在开发者机器上构建轻量级的代码关系图,使得AI Agent能够在不依赖云端服务的情况下进行结构化的代码推理。它支持影响分析(修改X会影响哪些下游)、依赖追踪(Y依赖哪些上游组件)、死代码检测(哪些函数从未被调用)等典型查询模式,特别适合离线开发和高安全性场景。
DeepWiki——代码的语义百科全书
如果说CKG是代码的结构地图,那么DeepWiki就是代码的语义百科全书。它不仅仅是代码注释,而是系统化地回答了更深层次的问题:
- 代码为什么这么写?
- 它在整个系统里扮演什么角色?
DeepWiki会把散落在设计文档、PR讨论、甚至事故复盘里的知识整合起来,给AI提供最丰富的背景信息。这样当AI生成答案时,不仅能给出代码,还能解释背后的设计意图和历史演变。
DeepWiki代表了一种从"代码即文档"到"知识即文档"的范式转变。传统的代码文档(如Javadoc、Doxygen)只描述接口的What层面,而DeepWiki试图捕捉Why和How层面的知识。其知识来源包括:Git提交历史(揭示代码演变轨迹)、Pull Request讨论(记录设计决策的争论过程)、Issue追踪(关联Bug修复的上下文)、架构决策记录(ADR)、甚至Slack或飞书中的技术讨论。这些非结构化知识通过LLM进行摘要、关联和结构化处理后,形成一个可检索的语义知识库。这解决了软件工程中著名的"知识蒸发"问题——当核心开发者离职后,大量隐性知识(tacit knowledge)随之消失,新成员需要数月甚至数年才能重建对系统的深度理解。
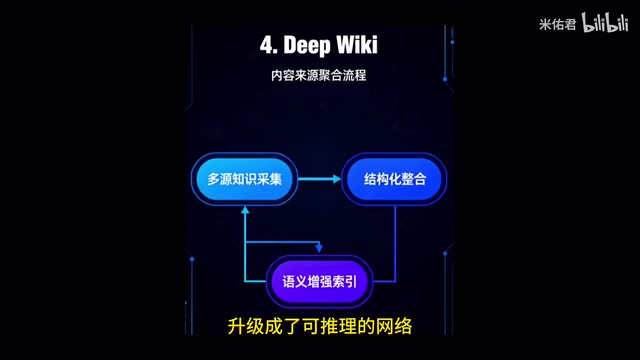
CKG与DeepWiki的互补关系
CKG的核心价值是把代码从文本集合升级成可推理的网络,让AI能理解代码间的因果关系。DeepWiki则更进一步,为AI补上了"为什么"这一课,填补了设计意图和历史背景的空白。
两者结合,使得AI的输出不再是孤立的代码片段,而是一个包含了上下文、设计逻辑和背景知识的集成答案。这种组合也呼应了软件工程中"代码考古学"(Code Archaeology)的理念——理解一段代码不仅需要知道它现在做什么,还需要知道它为什么变成现在这个样子。
总结:四位一体的CodeRAG完整方案
CodeRAG通过四种技术的协同,构成了一套完整的解决方案:
| 技术组件 | 核心能力 | 解决的问题 |
|---|---|---|
| 向量相似度 | 捕捉代码深层语义 | 理解用户真实意图 |
| 文件系统工具 | 模拟程序员导航习惯 | 高效安全获取信息 |
| 代码知识图谱(CKG) | 揭示结构和依赖关系 | 精准检索与推理 |
| DeepWiki | 整合设计意图与多元知识 | 提升答案深度 |
这四种技术的共同目标,就是让AI编程助手的输出能够真正扎根在真实的代码语境当中,使答案更可靠、更经得起推敲。在AI编程工具日益普及的今天,CodeRAG代表的不仅是一种技术方案,更是一种让AI从"看似聪明"走向"真正可靠"的工程哲学。
值得注意的是,这四种技术并非相互独立,而是形成了一个从粗到细、从表层到深层的渐进式理解体系:向量相似度提供初始的语义锚点,文件系统工具实现精确的信息获取,CKG揭示结构化的依赖关系,DeepWiki补充人类层面的设计智慧。随着上下文窗口的持续扩大和多模态模型的发展,CodeRAG的各个组件也在不断演进——但其核心理念不会改变:让AI的每一个输出都有据可查、有源可溯。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。