Codex Memory机制详解:跨会话记忆如何让AI编程助手不再失忆

OpenAI Codex Memory机制让AI编程助手拥有跨会话长期记忆,提升开发效率。
OpenAI Codex推出Memory功能,通过持久化存储历史会话中的关键上下文信息并在新会话中自动注入,解决了LLM无状态导致的"失忆"问题。该机制采用类RAG架构,经过智能筛选、信息抽取、脱敏处理、额度校验等环节,将用户的项目规范、技术选型、命名习惯等长期偏好本地存储,实现跨会话知识传递,显著减少重复沟通成本。
OpenAI 的 Codex 近期上线了一项备受关注的功能——Memory(记忆机制)。这项功能让 AI 编程助手不再"失忆",能够在多次对话之间保留关键上下文,从而显著提升开发效率。本文将深入解析 Codex Memory 的工作原理、核心架构以及最佳使用策略。
从"失忆"到"记住":Codex Memory 解决了什么问题?
在没有 Memory 机制之前,每次与 Codex 开启新会话,AI 都是从零开始。你之前告诉它的项目规范、命名习惯、技术选型偏好——全部丢失。开发者不得不在每次新对话中反复重申相同的上下文信息,效率极低。
这一问题的根源在于大语言模型(LLM)的上下文窗口限制。当前主流 LLM 都有一个固定的上下文长度(Context Window),例如 GPT-4 Turbo 支持 128K tokens,Claude 3 支持 200K tokens。每次新会话开始时,上下文窗口是空白的,模型无法访问之前会话的任何信息。即使在同一会话内,当对话长度超过上下文窗口限制时,早期的对话内容也会被截断或丢失。这就是所谓的"无状态"特性——LLM 本质上是一个无记忆的函数,输入什么就处理什么,不会自动保留历史状态。
Memory 机制的核心思路非常直观:将历史会话中有价值的上下文信息持久化存储,并在后续新会话中自动注入。简单来说,就是在模型层之上构建了一层持久化抽象,让 AI 拥有了"长期记忆",从根本上弥补了 LLM 无状态的局限性。
用一个简化模型来理解:当你依次创建会话1、会话2、会话3时,每次会话的关键信息都会被提取并存入 Memory 数据库。当你创建会话4时,系统会从 Memory 中读取之前积累的上下文,自动注入到新会话中。这样,Codex 就"记住"了你之前的偏好和项目背景。
有意思的是,Memory 功能支持手动开关。你可以通过斜杠命令来启用或关闭记忆功能,这给了开发者充分的控制权——有些临时性的对话可能并不需要被记录。
Codex Memory 完整工作流程解析
Codex Memory 的运作并非简单的"存储-读取",而是经过了多个精心设计的环节。从技术架构上看,这套"存储-检索-注入"的模式与当前 AI 领域广泛使用的 RAG(Retrieval-Augmented Generation,检索增强生成) 架构有着密切的技术关联。RAG 的核心思想是:在生成回答之前,先从外部知识库中检索与当前问题相关的文档片段,然后将这些片段作为上下文注入到 LLM 的提示词中,从而让模型基于更准确的信息进行推理。Codex Memory 可以被视为一种个性化的 RAG 系统——它的"知识库"不是通用文档,而是用户历史会话中提炼出的个人偏好和项目知识。在新会话创建时,系统会根据当前任务的语义相关性,从 Memory 中检索最相关的记忆条目进行注入,而非简单地将所有历史记忆一股脑塞入上下文窗口。
以下是完整的工作流程拆解。
第一步:观察与判断——智能筛选有价值的信息
当你开启 Memory 开关后,系统并不会盲目记录所有对话内容。它会先进入一个观察期,判断当前会话是否包含值得提取的信息。
这个判断机制非常关键——如果把每一次对话的上下文都保存到记忆中,不仅浪费存储空间,还会引入大量噪声信息。系统会根据特定条件进行筛选,只有满足提取条件的会话内容才会进入下一步。
第二步:后台抽取与脱敏——保护敏感数据
当会话内容满足提取条件后,系统会在后台进行信息抽取。但在写入 Memory 之前,还有一个至关重要的步骤——脱敏处理。
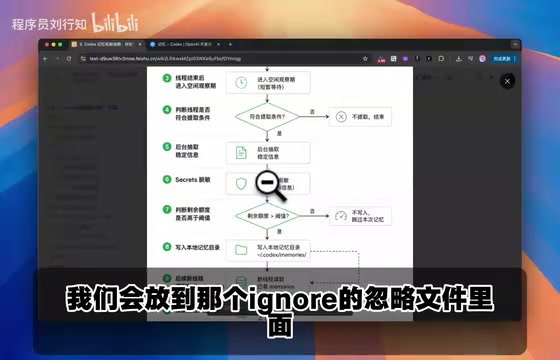
脱敏处理(Data Masking / Data Sanitization)是信息安全领域的核心技术之一。在 Codex Memory 的场景中,脱敏主要依赖正则表达式匹配和语义识别两种手段协同工作。正则匹配可以捕获具有固定格式的敏感信息,例如以 sk- 开头的 OpenAI API Key、以 ghp_ 开头的 GitHub Personal Access Token,以及符合特定模式的 AWS 密钥等。语义识别则通过 LLM 自身的理解能力,判断某段文本是否属于凭证类信息——比如用户在对话中说"我的数据库密码是 xyz123",即使没有固定格式,模型也能识别其敏感性。
在实际开发中,对话上下文中经常会包含敏感信息,比如:
- API Key(如 DeepSeek、OpenAI 等服务的密钥)
- 数据库连接字符串
- 账号密码等凭证信息
虽然这些信息通常应该放在 .gitignore 文件中,但对话中难免会涉及。Codex 会自动识别并脱敏这些内容,防止敏感信息被持久化存储。这种双重机制大幅降低了敏感信息泄露的风险,但开发者仍应保持警惕,不要主动在对话中粘贴完整的密钥内容。
第三步:额度校验与写入
脱敏完成后,系统还会检查当前用户的 Memory 额度是否充足。只有在额度满足阈值的情况下,信息才会最终写入本地 Memory 数据库。如果额度不足,则跳过写入。
第四步:新会话自动读取与注入
当用户创建新的会话时,系统会从 Memory 中读取已有的记忆条目,并将其注入到新会话的上下文中。这样,新会话就自动继承了之前积累的项目知识和用户偏好,实现真正的跨会话记忆。
Codex Memory 的核心数据结构
Codex Memory 默认存储在 CODEX_HOME 目录下的 memories 子目录中。CODEX_HOME 是 Codex CLI 工具的配置根目录,类似于 Git 的 .git 目录或 npm 的 .npm 目录。这种将配置和数据存储在用户本地文件系统的设计遵循了 XDG Base Directory 规范的理念——将应用数据、配置文件和缓存分别存放在约定的目录结构中。Memory 数据存储在本地而非云端,意味着记忆数据不会跨设备自动同步(除非手动迁移),但也带来了显著的隐私优势:用户的项目知识和偏好信息不会上传到第三方服务器。这种**本地优先(Local-first)**的存储策略在开发者工具中越来越常见,它在数据主权和使用便利性之间取得了良好的平衡。
每一条记忆由四个核心模块组成:
- 线程阶段性摘要:对每次会话的关键内容进行阶段性总结
- 稳定记忆条目:长期不变的项目规范、技术选型等信息
- 近期上下文线索:最近几次对话中的关键信息片段
- Agents Markdown 规范:可以自定义的详细规范文档
这四个模块协同工作,帮助系统判断在新会话中应该读取哪些历史信息。其中,稳定记忆条目会与你在仓库中设定的项目规范绑定,确保 AI 始终遵守你的项目约定。
Memory 使用最佳实践:什么该存、什么不该存?
理解了 Memory 的工作原理后,更重要的是知道如何合理使用它。以下是一份经过实践验证的使用指南。
适合存入 Memory 的内容
- 长期稳定的输出偏好:比如你习惯的代码注释风格、文档格式等
- 命名习惯:变量命名规范、文件命名约定等(例如 BEM 命名规范——Block-Element-Modifier 的缩写,是一种广泛使用的 CSS 命名方法论,由 Yandex 团队提出。它将界面组件拆分为 Block(独立功能模块,如
menu)、Element(Block 的组成部分,如menu__item)、Modifier(状态变体,如menu__item--active)三个层级。将这类命名规范存入 Memory 后,AI 在后续生成代码时会自动遵循该约定,避免每次手动纠正。) - 技术选型决策:项目使用的框架、库、工具链等
- 已踩过的坑:特定场景下的 bug 修复经验、性能优化方案等
- 固定的代码模板:如果你有特定的开头/结尾模板习惯
不适合存入 Memory 的内容
- 密钥和 Token:API Key、Secret 等敏感凭证
- 账号密码:任何形式的认证信息
- 团队内部机密规范:不宜持久化的内部约定
- 临时性的调试信息:一次性的问题排查内容
实际应用场景:以小程序开发为例
以小程序开发为例,假设你正在用 Codex 辅助开发一个微信小程序:
第一次会话:你告诉 Codex 项目使用 Taro 框架、TypeScript 语言、采用 BEM 命名规范。这些信息会被提取并存入 Memory。
这里值得展开说明一下 Taro 框架的背景。Taro 是由京东凹凸实验室开发的开源跨端开发框架,允许开发者使用 React/Vue 等主流前端语法编写代码,然后编译为微信小程序、支付宝小程序、H5、React Native 等多个平台的应用。Taro 3.x 版本采用了运行时适配的方案,通过在各小程序平台上模拟 DOM/BOM API,使得几乎所有前端框架都可以在小程序环境中运行。选择 Taro 作为技术选型是一个典型的需要被 Memory 记录的决策,因为它直接影响了项目的目录结构、组件写法、API 调用方式和构建配置,是贯穿整个开发周期的基础性约定。
第二次会话:你让 Codex 帮你写一个新页面组件。此时 Memory 自动注入,Codex 会直接使用 Taro + TypeScript + BEM 规范来生成代码,无需你再次说明。
第三次会话:你发现某个 API 有兼容性问题并告诉了 Codex。这个"坑"也会被记录,后续涉及类似 API 调用时,Codex 会自动规避。
这就是 Memory 机制带来的效率提升——随着使用时间的增长,Codex 对你的项目理解会越来越深入。
总结
Codex Memory 机制的本质是一套智能化的上下文持久化与复用系统。它通过观察判断、信息抽取、脱敏处理、额度校验、写入存储、读取注入这一完整链路,实现了跨会话的知识传递。从技术视角来看,它是 RAG 架构在个人开发场景中的一次精巧应用,将"通用知识检索"转化为"个人偏好与项目知识检索"。
对于开发者而言,合理利用 Memory 功能可以显著减少重复沟通成本,让 AI 编程助手真正成为一个"了解你"的长期协作伙伴。关键在于:开启 Memory 时要有意识地引导它记录有价值的信息,同时注意避免敏感数据的写入。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。