Codex VS Claude Code:10倍差价背后的Token经济学

同一个复杂编程任务,Codex收费15美元,Claude Code收费155美元——整整10倍的差距。这个数字不是某次偶然,而是多家独立测评反复验证的结果。很多人第一反应是"便宜就选便宜的",但真相远没这么简单。今天我们把这笔账彻底算清楚。
单价几乎一样,差距根本不在这里
大多数人下意识认为Codex便宜是因为OpenAI的Token单价低。但拉出官方价目表一看,结论完全反直觉。
Codex主力模型GPT-5.5的定价:每百万Token输入5美元,输出30美元。Claude Code主力模型Opus 4.8的定价:每百万Token输入5美元,输出25美元。

输入价格一模一样,输出价格上GPT-5.5反而更贵。所以第一个结论就很明确:10倍差价跟单价没有任何关系。Codex在单价上甚至还略贵于Claude Code。
那钱到底差在哪?答案是Token用量。这里需要理解Token这个概念:Token是大语言模型处理文本的基本计量单位,一个Token大约对应英文中的3/4个单词,或中文中的1-2个汉字。模型每次调用时,输入(你发给它的内容)和输出(它生成的内容)的Token数量分别计费,且输出Token通常比输入Token贵3-6倍,因为生成文本比读取文本需要更多算力。在AI编程场景中,一次复杂任务可能涉及数十轮调用,每轮都会产生输入和输出Token,因此总消耗量可以轻松达到数百万级别。
同类复杂任务,Codex大约消耗150万Token,Claude Code则烧掉620万,差了4倍多。这个数据不是孤例,多家独立评测跑出来的区间在3.2到4.2倍之间,无论谁测、怎么测,Codex更省Token这一点是一致的。
至于最终账单为什么拉大到10倍而不是4倍,是因为620万Token中高价的输出Token占比更高,加上缓存命中率的差异,综合下来差距进一步放大。所谓缓存命中率,是指在多轮对话中,前几轮已经发送过的输入Token如果被API缓存,再次发送时可以享受折扣价(通常是原价的10%-50%)。Codex的架构设计更注重缓存复用,而Claude Code由于每轮都会塞入大量新读取的文件内容,缓存命中率相对较低,这进一步拉大了实际账单差距。
三层拆解:Codex凭什么只用1/4的Token
同样一个活,Codex凭什么用四分之一的Token就干完了?这才是真正值得深挖的问题。
第一层:输出风格的差异
GPT-5.5惜字如金,不铺垫、不绕弯。你让它写代码,它直接甩出一段能跑的程序。Claude则完全相反——它喜欢解释思考过程,会反问你确认需求,还会顺手讲讲为什么这么写。
简单说,一个是闷头干活的,一个是边干边汇报的。
有评测显示,在等价任务上GPT-5.5比Opus少用了大约72%的输出Token。这个精确数字仅来自单一测评,但"明显少很多"是各方共识。

更关键的是放大效应。AI编程不是一句话就完事,一个任务要来回调用几十次——读文件、跑命令、改代码。每一轮都省那么一点点,几十轮叠下来,差距就滚成了好几倍。这种复合累积效应在软件工程中非常常见:单次1%的效率差异,经过100次迭代后就会变成2.7倍的总差距,而AI编程中每轮的Token差异远不止1%。
第二层:上下文读取策略的差异
这里要理解一个关键概念:上下文。上下文就是AI当下"记着"的所有东西——你说过的话、它读过的文件,全部堆在一起,而且这部分同样按Token计费。上下文窗口(Context Window)是模型单次调用能处理的最大Token数量,目前主流模型的上下文窗口已达到128K甚至200K Token。窗口越大,模型能"记住"的内容越多,但也意味着每轮调用可能塞入更多需要计费的Token。
Claude Code的读法非常"实在":每读一个文件、每跑一条命令,都把整段原文完整塞进上下文,不做压缩摘要,而且一直留着不删。问题在于,如果中途读了一份上万行的日志,这份日志会在后面每一轮对话中持续占位、持续计费。读得越多,背的包袱越重,上下文像滚雪球一样越滚越大。
Codex的上下文管理更克制,读取更精简。同样大小的上下文窗口,它的实际利用效率更高。打个比方:同样是一个能装200本书的书架,Codex只放当前需要翻阅的几本,用完就归还;Claude Code则是每看过一本就留在书架上,直到书架快满了才不得不清理。
第三层:任务执行习惯的差异
Claude Code探索得更广、查得更细。同一个bug,它会主动多翻几个相关文件,多查几遍,反复跟自己确认没搞错。这些"再查一遍"的动作,全都在消耗Token。
Codex则更直奔目标,看准了就下手,少绕路。这两种策略的差异,本质上反映了AI系统设计中"探索与利用"(Exploration vs. Exploitation)这一经典权衡:探索更多可能性能降低遗漏风险,但会消耗更多资源;直奔目标效率更高,但可能错过边缘情况。
便宜不等于更好:Claude多烧的Token买到了什么
看到这里,你可能觉得Claude Code就是在浪费钱。但把前面三层倒过来看一遍,味道完全变了。
Claude多烧的那4倍Token,买的是两个字:彻底。

正因为它读得全、查得细、想得多,在实际对比中Claude Code抓到过一个Codex漏掉的竞态条件(Race Condition)。竞态条件是并发编程中最经典也最棘手的bug类型之一——当两个或多个线程同时访问共享资源,且最终结果取决于它们执行的先后顺序时,就可能出现竞态条件。它的危险之处在于:在开发和测试环境中几乎不会触发,因为单机负载低、时序稳定;但在生产环境的高并发场景下,微妙的时序差异就可能导致数据损坏、死锁甚至安全漏洞。历史上许多重大系统故障——包括2003年美加大停电事故中的软件缺陷——都与竞态条件有关。发现这类bug通常需要对代码进行极其细致的逐行审查,这正是Claude Code"多绕几圈"策略的价值所在。Claude多绕的那几圈,恰恰就把它给绕出来了。
代码质量的差距也有数据支撑:
- 盲评结果:把两边写的代码匿名摆在一起,67%的评审者认为Claude Code写的代码更干净,认为Codex更干净的只有25%。代码盲评借鉴了学术论文同行评审的双盲机制:评审者不知道代码由哪个AI生成,只根据代码的可读性、结构清晰度、错误处理完整性和最佳实践遵循程度来打分。这种方法能有效消除品牌偏见——如果评审者知道代码来自某个"更贵"的模型,可能会下意识给更高分。67%对25%的盲评结果具有较强的统计意义,说明Claude Code在代码工艺层面确实存在可量化的优势。
- 开发者调查:在一份500多人的调查中,65%的开发者日常主力仍然选择Codex
这两个数字必须放在一起看。Claude的代码质量确实更高,但大多数人日常照样选Codex——因为对大多数任务来说,省钱省事够用,确实比那一点点更干净更重要。
选型指南:不是谁更好,而是按场景算账
整条逻辑链到这里就通了:Codex把钱省在少说废话,Claude把钱花在多查一遍。没有谁占了便宜,是各花各的钱、各办各的事。

选Codex的场景
- 日常开发和快速迭代:写功能模块、调接口、处理常规逻辑
- 原型验证阶段:快速出MVP,先跑通再说。MVP(Minimum Viable Product,最小可行产品)是精益创业方法论的核心概念,由Eric Ries在《精益创业》一书中系统阐述。其核心思想是用最小的成本和最短的时间构建一个能验证核心假设的产品版本,通过真实用户反馈来决定下一步方向。在这种哲学下,代码的"完美度"远不如"能跑起来并收集反馈"重要,这也解释了为什么大多数开发者在迭代早期更倾向于选择成本更低的方案。
- 预算敏感的项目:个人开发者、初创团队、学习练手
- 已有ChatGPT会员:Codex基本是会员附带功能,不用额外付费
选Claude Code的场景
- 复杂系统重构:涉及多模块联动、历史遗留代码的大工程。这类项目中,代码之间的依赖关系错综复杂,修改一处可能引发连锁反应,Claude Code"多翻几个文件"的习惯在这种场景下反而成了优势——它更可能发现那些隐藏在模块交界处的兼容性问题。
- 生产级代码:容错要求严格、质量优先的场景
- 安全敏感领域:需要发现竞态条件等隐藏bug
- 代码审查和优化:需要更深入的分析和更干净的输出
值得一提的是,许多成熟的工程团队已经开始采用"混合策略":日常开发用Codex快速推进,在代码合并到主分支前用Claude Code做一轮深度审查。这种组合既控制了总成本,又在关键节点保证了代码质量。
核心结论
10倍差价的真相已经清楚:单价几乎一样(GPT-5.5输出还更贵),真正的差距在Token用量——Codex的4倍用量优势来自惜字、省读、不绕路。但Claude多消耗的Token不是浪费,它买到的是更彻底的排查和更干净的代码。
选型的本质不是比谁更强,而是根据你的具体场景做成本和质量的权衡。日常开发选Codex省钱省心,关键项目选Claude Code为质量买单——这才是理性的工程决策。
相关推荐
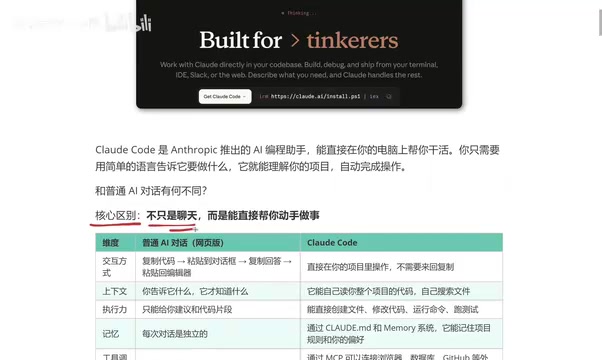
Claude Code是什么?与普通AI对话的五大核心区别
深入解析Claude Code与ChatGPT、DeepSeek等普通AI对话工具的五大核心区别,从交互方式、上下文理解、执行力、记忆能力到工具调用,全面了解这款AI编程助手的真正实力。
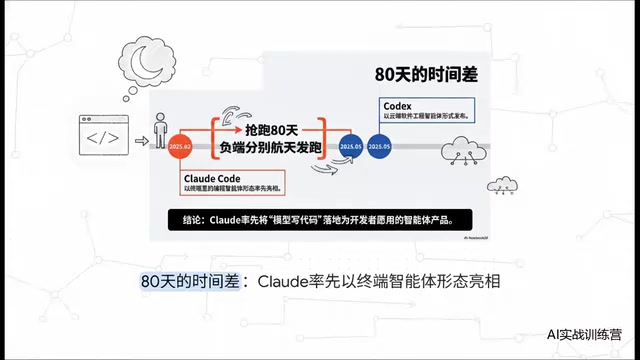
Claude Code vs Codex深度对比:技术趋同下谁更值得选
深度对比Claude Code与OpenAI Codex在先发优势、技术架构、市场份额和工程稳定性方面的差异。从18:4的创新领先到功能像素级对齐,解析AI编程工具趋同时代的终极选择标准。
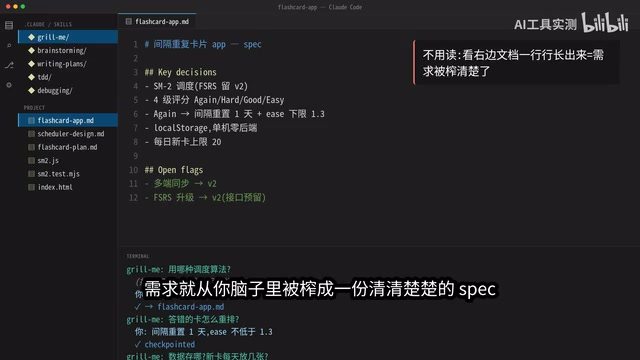
Claude Code每天必用的5个技巧:让AI反过来盘问你
分享Claude Code高效编程的5个实用技巧:Grill Me逼问需求、Brainstorming方案选型、Writing Plan执行计划、TDD测试驱动、Debugging精准修复,串成完整AI编程工作流,告别模糊需求和来回返工。