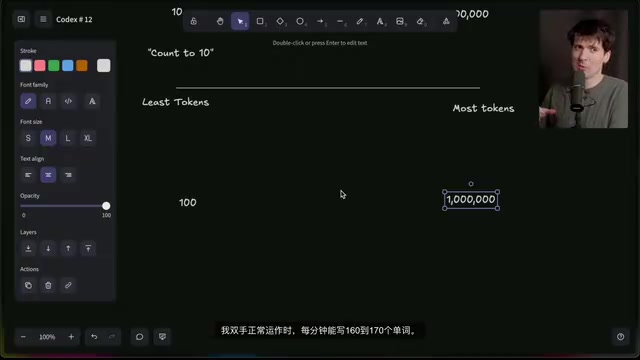
#Token消耗对比
共 7 篇相关文章
·10 分钟
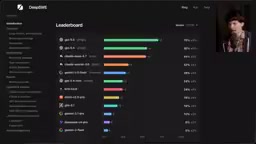
DeepSWE基准测试深度解析:揭露SWE-Bench缺陷与真实编程能力排名
深度解析DeepSWE编程基准测试如何揭露SWE-Bench Pro的数据污染和作弊问题。GPT-5.5以70%通过率领先,开源模型差距明显。涵盖测试结果、成本对比与开发者实用建议。
阅读全文 →
·9 分钟
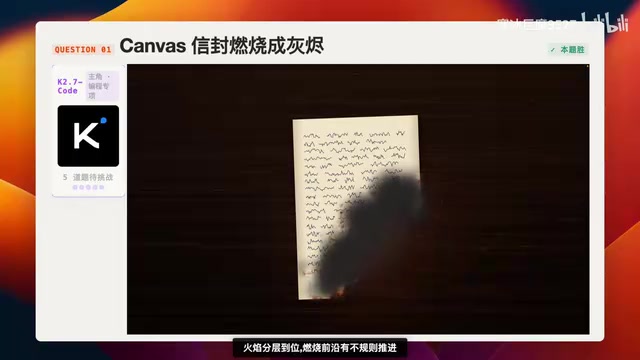
Kimi K2.7-Code vs K2.6实测对比:五道硬核题谁更强?
通过粒子特效、刚体物理、软体物理、UI设计和代码Review五道硬核题,实测对比Kimi K2.7-Code与K2.6的质量得分、Token消耗和运行时间,揭示K2.7-Code真实升级成色与性价比。
阅读全文 →

·8 分钟
AI三种形态:从聊天窗到协同办公再到命令行
AI不只是聊天窗口。本文详解AI的三种使用形态:Chatbox聊天问答、Cowork协同办公、CLI命令行工具,并给出Claude、Codex、Kimi、DeepSeek四款产品的选择建议与实际组合方案。
阅读全文 →

·8 分钟
Codex VS Claude Code:10倍差价背后的Token经济学
同一个编程任务,Codex收费15美元,Claude Code收费155美元。深度拆解10倍差价的真正原因:不是单价差异,而是Token用量、输出风格和上下文策略的根本不同。附详细选型指南。
阅读全文 →
 科技前沿
科技前沿·8 分钟
Generic Agent:3000行代码打造自进化AI智能体
Generic Agent用仅3000行核心代码实现自进化AI智能体,通过9个原子工具和五层记忆架构,Token消耗仅为竞品六分之一。深度解析其极简架构、技能固化机制与实际能力表现。
阅读全文 →
 产品体验
产品体验·7 分钟
Trae Solo深度实测:字节跳动免费AI编程工具到底能用吗
深度实测字节跳动Trae Solo免费AI编程工具,从Token额度、6项目并发、三端协同、模型质量等维度全面评估,揭示这款国内个人完全免费的AI编程工具的真实表现。
阅读全文 →