Kimi K2.7-Code vs K2.6实测对比:五道硬核题谁更强?
背景:K2.7-Code发布,升级成色几何?
Kimi 近期在 AI 编程领域势头很猛——在B站UP主进行的15期 AI 挑战中,Kimi 上场5次拿下3次冠军。就在近日,Kimi K2.7-Code 正式发布,官方宣称代码能力显著提升,Thinking Token 消耗降低30%。
但口说无凭,PPT升级还是真升级?B站UP主设计了一场"父子局"内部对决:K2.7-Code vs K2.6,五道题涵盖粒子特效、刚体物理、软体物理、UI设计和代码审查,每道题记录质量得分、Token消耗和运行时间三项数据。结果如何?让我们逐题拆解。
五道硬核题逐一拆解
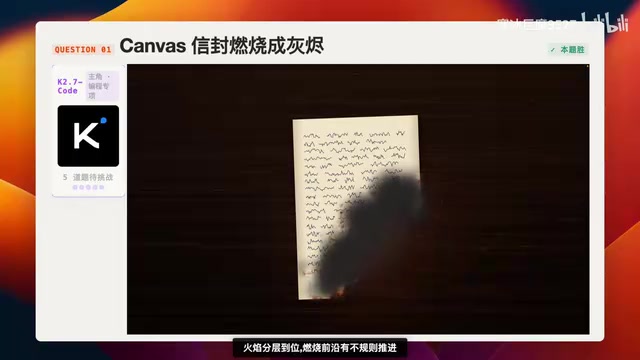
第一题:信封燃烧——粒子与形变基础测试
这道题主要考察火焰形态和灰烬飘散效果,是粒子系统和形变能力的基础检验。粒子系统(Particle System)是计算机图形学中模拟火焰、烟雾、爆炸等非刚性现象的核心技术——其基本原理是生成大量微小粒子,每个粒子拥有位置、速度、生命周期、颜色等属性,通过物理规则驱动其运动和消亡,最终在视觉上呈现出复杂的自然现象。信封燃烧这类效果的难点在于,它不仅需要粒子系统模拟火焰,还需要对纸张网格进行实时形变(Mesh Deformation),让燃烧前沿以不规则方式推进,同时协调焦化变色、灰烬剥离等多个子系统的时序关系。这对AI模型的多系统协调编码能力是一个综合考验。
K2.6 表现翻车:2分41秒极速出结果,但直接黑屏。更尴尬的是,它自己 review 修改后依然无法运行,最终得分 0分。
K2.7-Code 耗时21分钟(近9倍于K2.6),但完整跑通。火焰分层到位,燃烧前沿有不规则推进,纸张焦化经历了深褐→黑色→消失三个阶段,整体效果不错。不过也有瑕疵——纸都消失了,灰烬却凭空出现,逻辑上说不通。它还使用了 Headless Chrome 抓取关键帧进行多轮验证,工程化程度明显更高。
Headless Chrome 是 Google Chrome 浏览器的无头模式,可以在没有图形界面的环境下运行完整的浏览器引擎。在AI编程场景中,模型利用 Headless Chrome 自动打开生成的网页,截取关键帧画面,然后对截图进行分析以判断渲染效果是否符合预期。这种"生成-渲染-截图-评估-修改"的闭环验证流程,本质上是一种自动化测试驱动开发(TDD)的思路。它显著提升了输出的可靠性——模型不再是"盲写代码然后祈祷能跑",而是主动验证结果并迭代修正。但代价也很明显:每一轮验证都需要启动浏览器、等待渲染、分析截图,这直接导致了运行时间的大幅增加。
第二题:两车相撞——刚体物理碰撞测试
刚体物理碰撞几乎没有模型能一遍过,这道题难度不小。刚体物理(Rigid Body Physics)是物理引擎中最基础也最经典的模块,模拟不会发生形变的物体之间的碰撞、弹跳和摩擦。然而"两车相撞"这个场景远超基础刚体范畴——真实的车辆碰撞涉及碰撞检测(Collision Detection)、冲量响应(Impulse Response)、车身形变(Deformable Body)以及碎片飞溅等多个层次。碰撞检测的精度尤为关键:如果使用简单的包围盒(Bounding Box)而非精确的网格碰撞检测,就容易出现"还没碰上就触发碰撞"的假阳性问题。
K2.6 再次秒出结果(57秒),但造出的是个空壳 UI——有按钮看不到车,点击开始演示毫无反应,0分。
K2.7-Code 用了9分33秒,至少能看到车并且可以运行。碰撞有慢动作、有粒子效果,但存在致命 bug:两辆车距离还很远就触发了碰撞动画,实际根本没碰上,车身形变也没做。这个"假碰撞"bug 大概率就是碰撞检测阈值设置过大或使用了过于粗糙的包围体导致的。虽然是致命缺陷,但至少比完全不能运行强。
第三题:风吹窗帘——软体物理与实时交互
这道题考验软体物理模拟和鼠标交互的实时响应——鼠标在画面上移动,窗帘就要被"吹动"。软体物理(Soft Body Physics)模拟的是可以发生形变的物体,如布料、果冻、绳索等。窗帘模拟通常采用质点-弹簧模型(Mass-Spring Model)或基于位置的动力学(Position Based Dynamics, PBD):将布料离散化为网格上的质点,质点之间通过弹簧约束连接,然后在每一帧中根据外力(重力、风力)和约束条件更新质点位置。鼠标交互则需要将鼠标位置映射为一个力场,实时影响附近质点的运动。这类任务的难点在于物理参数的调优——弹簧刚度、阻尼系数、风力方向等参数稍有偏差,就会出现"物理方向全反"或布料穿模等问题。
K2.6 46秒出结果,物理方向全反,但好歹能看见窗帘,拿到了 30分。
K2.7-Code 3分25秒完成,还主动询问要不要加背景——态度很好,但结果令人哭笑不得:挂窗帘的环都做出来了,唯独没有窗帘本体。这道题 K2.6 反而实现了反超。
第四题:iOS 29 UI 设计——创意与工程并行
这道题考验设计能力和代码并行输出,需要同时生成桌面端和移动端两种形态。

K2.6 3分20秒完成,UI完整但毫无创新,布局处理也不到位,不过拿到了 40分。
K2.7-Code 7分58秒,UI做了很多细节,但大量使用 emoji 表情——"是不是怕别人不知道是AI设计的"。而且顶部状态栏在每个页面都没处理好。这道题 K2.6 再次反超。
第五题:代码Review——真实项目实战检验
测试者拿出自己正在开发的桌面 Agent 项目,让两个模型做代码审查。项目是真实的"史山代码",bug 确实存在,但不告诉模型有几个。
代码审查(Code Review)是软件工程中保障代码质量的关键环节,传统上由资深开发者完成。AI 进行代码审查时,需要理解项目的整体架构、识别潜在 bug、发现安全漏洞、评估代码风格和可维护性。"史山代码"(指长期迭代、缺乏重构的遗留代码)对 AI 审查能力是极大的考验,因为这类代码往往缺乏清晰的结构和文档,bug 隐藏在复杂的上下文依赖中。
K2.6:2分59秒,消耗97.7k Token,找到 7个真问题,得分9分。
K2.7-Code:5分07秒,消耗83.3k Token,找到 6个真问题,得分8.5分。
两个模型都找到了清单外的真实问题,没有幻觉,基本算是平手。值得注意的是,两者都没有产生"幻觉"(即编造不存在的问题),这在代码审查场景中尤为重要——误报会严重降低开发者对工具的信任度。两者表现持平也暗示,代码理解和分析能力的提升可能需要不同于代码生成能力的训练策略。K2.6在这道题上略胜0.5分。
综合数据对比:谁赢了?
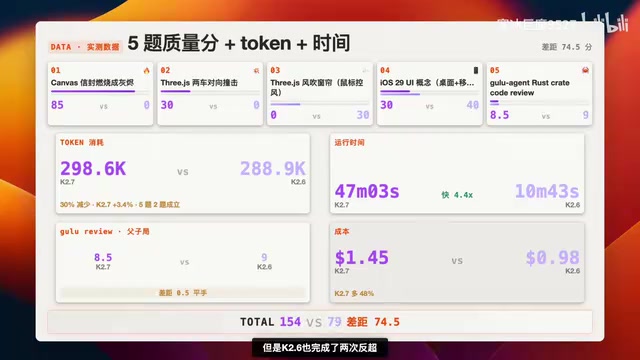
质量得分对比
| 指标 | K2.7-Code | K2.6 |
|---|---|---|
| 总分 | 153.5 | 79 |
| 差距 | +74.5分 | - |
K2.7-Code 在总质量上大幅领先,但 K2.6 并非完全被碾压——在第三题(窗帘)和第四题(iOS UI)实现了两次反超。
Token消耗对比
K2.7-Code 消耗 298.6k Token,K2.6 消耗 288.9k,K2.7 多出约 10%。
Thinking Token 是大语言模型在"思维链"(Chain of Thought)推理过程中内部消耗的 Token。与直接输出给用户的 Output Token 不同,Thinking Token 是模型"自言自语"进行推理的部分,用户通常看不到这些内容,但它们会被计入 API 调用的总 Token 消耗中,直接影响使用成本。对于代码生成这类复杂任务,模型往往需要大量 Thinking Token 来规划架构、推演逻辑、检查错误。官方宣称"Thinking Token 降低30%"意味着模型在推理效率上进行了优化——用更少的内部推理步骤达到相同或更好的输出质量。但实测中这一指标仅在五道题中的两道成立,其余三道 K2.7 反而消耗更多。这说明优化效果可能与任务类型高度相关,在需要多轮验证的复杂任务中,额外的工程化流程反而抵消了推理效率的提升。
运行时间对比
K2.7-Code 总耗时47分03秒,K2.6 仅10分43秒——K2.6 快了 4.4倍。K2.7-Code 的工程化验证流程(如 Headless Chrome 多轮验证)显著拖慢了整体时长。
成本对比
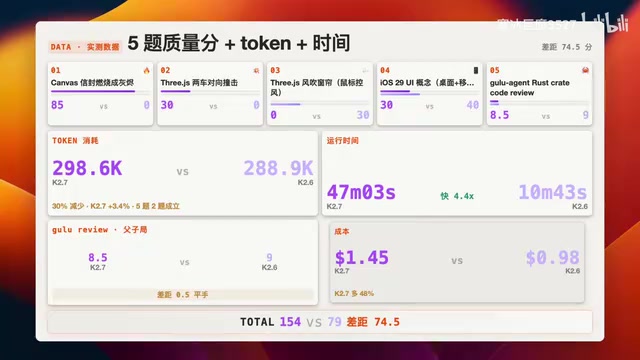
K2.7-Code 花费 1.45美元,K2.6 花费 0.98美元,K2.7 贵了 48%。
核心结论:真升级,但代价不小
K2.7-Code 赢得了这场内部对决,但赢得并不算压倒性。总结几个关键发现:
1. 质量确实提升了,但不是全面碾压。 K2.7-Code 在粒子特效、物理模拟等复杂任务上明显更强,但在 UI 设计和软体物理上反而不如 K2.6。它的核心优势在于"能跑通"——K2.6 三道题直接翻车(黑屏、空壳UI),而 K2.7 至少都能产出可运行的结果。这种从"不能用"到"能用但有瑕疵"的跨越,在实际开发中往往比从"80分"到"90分"的提升更有价值。
2. 时间和成本是真实的代价。 慢4.4倍、贵48%,这不是小数字。K2.7-Code 的工程化流程(主动验证、多轮迭代)提升了可靠性,但也大幅增加了时间和 Token 开销。这本质上是一个经典的工程权衡:用更多的计算资源换取更高的输出可靠性。对于生产环境中的关键任务,这种权衡通常是值得的;但对于快速原型验证等场景,K2.6 的"秒出结果"可能更实用。
3. "Thinking Token 降低30%"的宣传需要打折。 五道题中仅两道符合预期,整体 Token 消耗反而增加了10%。这提醒我们,模型厂商的基准测试结果往往基于特定的任务分布,实际使用中的表现可能存在显著差异。
4. 代码Review能力基本持平。 这可能是最出乎意料的结果——作为主打代码能力的升级版本,K2.7-Code 在真实项目审查中并未展现出明显优势。代码生成和代码理解可能是两种不同维度的能力,前者更依赖模式匹配和代码补全,后者更依赖深层语义理解和逻辑推理,两者的提升路径未必同步。
最终选择哪个版本,取决于你的实际需求:追求输出质量和可靠性,K2.7-Code 是更好的选择;更在意速度和成本,K2.6 依然有竞争力。 这不是一次"套皮升级",但也远非革命性的飞跃。
相关推荐
GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
基于OneBlockBase平台实测GML 5.2与DeepSeek V4多模态升级,详解视觉识别与文本协同工作流搭建、前置拦截安全机制、界面生成效果及部署配置要点,验证纯文本模型通过工作流编排升级多模态的可行方案。
DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
详解DeepSeek API搭配VS Code插件Cline的完整配置流程,包括API Key获取、Plan/Act双模型策略、项目管理文件体系等进阶技巧,10元充值即可获得接近顶尖水平的AI编程体验。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。