DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
每月20美金的AI编程订阅费让你肉疼?其实只需要DeepSeek的API加上一个免费的VS Code插件Cline,就能以极低成本获得接近顶尖水平的AI编程体验。本文将详细介绍从零配置到高效使用的完整流程。
为什么选择DeepSeek + Cline这套AI编程组合
目前市面上主流的AI编程工具如Cursor、GitHub Copilot等,月费普遍在20美金左右。对于个人开发者或只是偶尔写些小应用的用户来说,这笔费用并不划算——很多时候额度还没用完月份就过去了。
而DeepSeek + Cline的组合提供了一种按量付费的替代方案。DeepSeek是由深度求索公司开发的国产大模型,采用了混合专家架构(MoE),这意味着模型虽然总参数量巨大(DeepSeek-V3达到671B参数),但每次推理时只激活部分专家网络,从而在保持高性能的同时大幅降低计算成本——这也是其API定价能够远低于OpenAI、Anthropic等竞品的核心技术原因。
混合专家架构(Mixture of Experts, MoE)是深度学习领域的一种稀疏激活技术,最早由Hinton等人在1991年提出概念,近年来被Google的Switch Transformer和Mixtral等模型发扬光大。传统的密集模型(Dense Model)在每次推理时会激活所有参数,而MoE模型通过一个"门控网络"(Gating Network)动态选择少量专家子网络参与计算。例如DeepSeek-V3拥有671B总参数但每次推理仅激活约37B参数,这使得其计算成本仅为同等规模密集模型的十分之一左右。这种架构的核心挑战在于负载均衡——如何确保各专家被均匀调用而非出现"赢者通吃"的退化现象,DeepSeek在这方面采用了无辅助损失的负载均衡策略,是其技术创新之一。
在逻辑推理能力方面,DeepSeek已接近国际顶尖水平,实测充值10元人民币用了很久都没花完,性价比可见一斑。
Cline(前身为Claude Dev)则是一款基于MIT协议的开源VS Code插件,与GitHub Copilot的行内代码补全不同,Cline的定位是一个完整的"AI开发代理"——它能够创建和编辑文件、运行终端命令、甚至浏览网页获取文档。Cline所代表的"AI开发代理"(AI Coding Agent)是AI编程工具演进的第三阶段。第一阶段是代码补全(如早期的TabNine),仅提供行内建议;第二阶段是对话式编程(如ChatGPT),用户需要手动复制粘贴代码;第三阶段则是代理式编程,AI能够自主操作开发环境。Cline基于VS Code的Extension API,通过Language Server Protocol与编辑器深度集成,能够直接调用文件系统API和终端模拟器。其MIT开源协议意味着任何人都可以自由使用、修改和分发,这与Cursor的闭源商业模式形成鲜明对比。
通过标准化的API接口,Cline支持接入OpenAI、Anthropic、Google、DeepSeek等多家模型提供商,相当于给你提供了一个灵活的AI编程助手框架,用户可以随时切换底层模型而无需更换工具。
DeepSeek + Cline完整配置教程
第一步:安装VS Code和Cline插件
首先下载并安装VS Code,这是开发者最常用的代码编辑器。安装完成后,在插件市场中搜索"Cline",找到带有机器人图标的插件并安装。
安装完成后,Cline默认显示在侧边栏。为了同时查看工程文件结构和与AI对话,建议将Cline面板拖到右侧的聊天区域。注意区分:VS Code自带的Chat面板是Copilot(需要付费),而我们要用的是带机器人图标的Cline面板。
第二步:获取DeepSeek API Key
前往DeepSeek的Platform API平台,完成以下操作:
- 充值:建议先充10元试水,实测足够长时间使用
- 实名验证:按平台要求完成身份验证
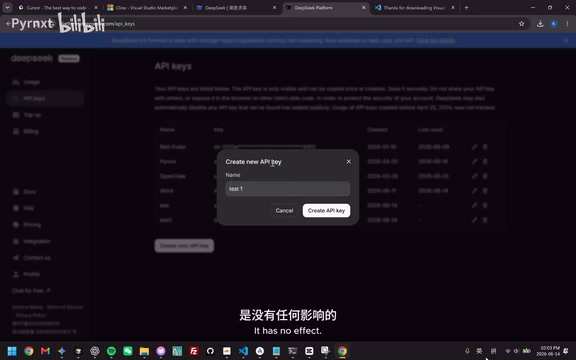
- 创建API Key:点击创建,随便取个名字,然后立即复制保存——API Key只会显示一次
API Key本质上是一个身份认证令牌,平台通过它来识别调用者并进行计费。一旦泄露,他人可以用你的额度调用API,因此务必妥善保管,不要将其提交到公开的代码仓库中。API Key泄露是云服务安全领域最常见的事故之一,GitHub曾报告每天有数千个有效的API密钥被意外推送到公开仓库。业界推荐的最佳实践包括:使用环境变量而非硬编码存储密钥、通过.gitignore排除包含密钥的配置文件、定期轮换密钥、以及设置API调用的速率限制和预算上限。DeepSeek平台支持设置月度消费上限,建议用户在充值后立即配置此项,以防止密钥泄露后产生意外费用。
第三步:在Cline中配置DeepSeek API
回到VS Code,首次打开Cline时会提示填入API Key。操作步骤:
- 选择模型提供商为DeepSeek
- 填入刚才复制的API Key
- 开启"Different models for Plan and Act"功能——这是一个关键优化
这个功能允许你在规划阶段和执行阶段使用不同的模型。其设计理念源于"思考-执行"分离的架构:在Plan阶段,AI需要理解需求、分析代码结构、制定实施方案,这要求更强的深度推理能力;在Act阶段,AI主要执行具体的代码编写和文件操作,对推理深度要求相对较低但对响应速度要求更高。推荐的配置方案是:
- Plan(规划阶段):使用DeepSeek Pro版本(对应deepseek-reasoner),具备链式推理能力,确保思路清晰
- Act(执行阶段):使用DeepSeek Flash版本(对应deepseek-chat),速度快且省Token
从技术角度来看,deepseek-reasoner和deepseek-chat在底层架构上有本质区别。deepseek-reasoner基于DeepSeek-R1模型,采用了强化学习训练的链式思维(Chain-of-Thought)推理机制,模型会在输出最终答案前生成详细的推理步骤,这些中间推理步骤虽然消耗额外Token但显著提升了复杂问题的解决能力。而deepseek-chat基于DeepSeek-V3,是一个优化了响应速度的通用对话模型,更适合执行明确指令的场景。这种分工策略在工程上被称为"认知架构分层",类似于人类大脑中前额叶皮层(负责规划)和运动皮层(负责执行)的功能分区。
这种双模型搭配类似于"架构师+程序员"的分工模式,能在保证代码质量的同时,显著降低Token开支。
实际使用效果测试
配置完成后,用经典的"24点计算"程序进行了实测。
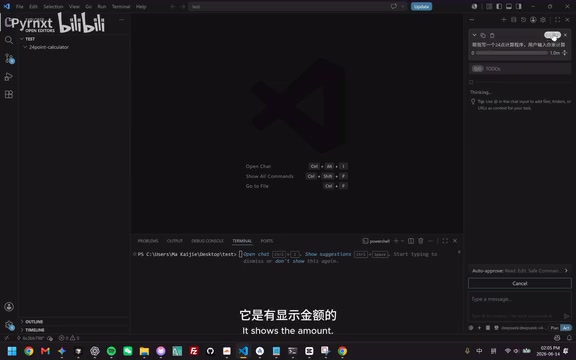
几个值得关注的细节:
- 费用透明:右上角实时显示Token消耗和对应金额,花了多少钱一目了然。这里解释一下Token的概念——它是大语言模型处理文本的基本单位,中文大约每1-2个字对应一个Token,英文则大约每4个字符对应一个Token。更准确地说,Token是通过分词算法(如BPE,Byte Pair Encoding)将文本切分后得到的子词单元,不同模型使用的分词器不同,因此同一段文本在不同模型中对应的Token数量可能有所差异。API按量计费时分为输入Token和输出Token,输出Token通常比输入Token贵2-4倍,这是因为生成输出需要逐Token自回归解码,计算量远大于一次性编码输入。DeepSeek的定价约为输入1元/百万Token、输出2元/百万Token(缓存命中时更低),相比GPT-4o的输入2.5美元/百万Token,价格差距可达数十倍。
- 代码生成速度快:很快就完成了代码编写,并自动运行测试
- 逻辑能力强:用历史上最难的24点组合"3、3、7、7"测试,成功算出结果(答案是(3÷7+3)×7=24),说明算法质量过关
还有一个重要的效率设置:在Cline的权限选项中,建议勾选自动执行权限,否则AI每次执行代码都需要你手动点击同意,非常影响工作效率。Cline的权限系统设计了多个粒度级别,包括文件读取、文件写入、终端命令执行等,你可以根据自己的安全需求选择性开放。胆子大的同学可以直接勾选"Read All",让代码执行更加通畅。
进阶技巧:用Development文件管理AI输出质量
对于真实项目,仅仅配置好工具还不够。这里分享一套通过项目管理文件来约束和引导AI输出的方法论,这也是从Anthropic内部实践中借鉴的经验。
Anthropic是Claude模型的开发公司,由前OpenAI研究副总裁Dario Amodei于2021年创立,公司以"AI安全"为核心使命,其研究团队在可解释性、宪法AI(Constitutional AI)等领域做出了开创性贡献。该公司在内部大量使用AI辅助开发,并总结出一套"AI协作工程"的最佳实践。其核心洞察在于:大语言模型在单次对话中不具备跨会话记忆能力(这是由Transformer架构的无状态特性决定的——模型权重在推理时不会更新),但通过将关键信息持久化为项目文件,可以在新会话中通过上下文注入的方式实现"伪记忆",从而让AI的表现随着项目推进而持续改善。这种方法在学术上与RAG(Retrieval-Augmented Generation,检索增强生成)的思路一脉相承,只不过检索源从外部知识库变成了项目本地文件。
核心文件体系详解
1. 原则与要求文件
将项目的编码规范、架构原则等写入其中,让AI在生成代码时遵循这些约束。例如你可以规定"所有函数必须包含类型注解""优先使用组合而非继承""错误处理必须使用自定义异常类"等。因为Cline的输入框较小,不适合输入大量信息,所以将详细需求写在文件中是更好的做法——Cline会自动读取项目中的文件作为上下文。这种做法在提示工程(Prompt Engineering)领域被称为"系统提示词外置",相比直接在对话中反复声明规则,文件化的方式更加稳定且易于版本管理。
2. 错误记录文件(Zero File)
每次AI犯错时,将错误原因和纠正方式记录在此。这样AI在后续任务中可以参考,避免重复犯同样的错误。这个方法的本质是利用文件系统来弥补大语言模型缺乏长期记忆的固有缺陷——模型本身不会"记住"上次犯了什么错,但如果错误模式被写入文件并在下次对话时作为上下文提供,模型就能据此调整行为。从认知科学的角度看,这相当于为AI构建了一个"外部工作记忆"(External Working Memory),类似于人类使用笔记本记录易犯错误的习惯。实践中,这个文件会越来越有价值,逐渐成为项目特有的"AI行为指南"。
3. 日志文件(Log/Run File)
用于追踪AI的工作过程,记录每个文件的用途和修改历史。虽然不是必需的,但它能帮助你回溯问题,让AI认识到自己的不足。这在调试复杂Bug时尤其有用——你可以让AI回顾日志,分析是哪一步引入了问题。这种做法与软件工程中的"变更日志"(Changelog)和"Git提交历史"理念相通,但更侧重于记录AI的决策过程和推理逻辑,而非仅仅记录代码变更本身。
4. 技术文件(Technology File)
记录项目的所有技术细节,包括使用的框架版本、数据库schema、API接口规范、第三方服务配置等。AI写完代码后,要求它将技术实现写入这个文件,确保知识的持续积累和传承。这对于长期维护的项目尤为重要,即使更换了AI模型或开始新的对话会话,新的上下文也能快速理解项目全貌。
从Cursor迁移到Cline的技巧
如果你之前使用Cursor(一款基于VS Code fork的AI编辑器,内置了Claude和GPT模型,由Anysphere公司开发,2024年估值已超过25亿美元),可以创建一个交接文件(Docking File):先让Cursor生成一份项目的完整交接文档,包括项目架构、核心模块说明、已知问题和待办事项等,然后让Cline阅读并写出它的理解。这样可以确保项目上下文的无缝衔接,避免新工具对代码内容的理解偏差。这个过程类似于团队中新成员的入职交接,只不过交接双方都是AI。值得注意的是,不同AI模型对同一段代码的理解可能存在微妙差异(这与各模型的训练数据和对齐方式有关),因此交接文件中应尽量使用明确、无歧义的描述,避免依赖隐含假设。
总结:谁适合这套方案
DeepSeek + Cline的组合为个人开发者提供了一个极具性价比的AI编程方案。10元人民币的充值就能用很久,配合Plan/Act双模型策略进一步优化成本,再加上一套完善的项目管理文件体系,完全可以替代每月20美金的订阅服务。
当然,这套方案也有其局限性:相比Cursor等集成方案,配置门槛稍高;DeepSeek的API偶尔会遇到高峰期排队的情况(这是因为DeepSeek采用了动态定价和排队机制来管理GPU资源,高峰时段的请求可能需要等待数秒到数十秒);对于超大型项目,上下文窗口的限制可能需要更精细的文件管理策略。大语言模型的上下文窗口(Context Window)是指模型单次能处理的最大Token数量,DeepSeek-V3的上下文窗口为128K Token,约相当于一本中等篇幅的技术书籍。然而在实际AI编程场景中,上下文需要同时容纳系统提示词、项目文件内容、对话历史和模型输出,可用空间会被快速消耗。当项目代码量超过上下文窗口容量时,就需要采用RAG(检索增强生成)策略——即只将与当前任务最相关的代码片段注入上下文,而非加载整个项目。Cline通过智能文件选择机制部分解决了这个问题,但对于超大型项目,用户仍需手动管理哪些文件应被纳入上下文。
但对于预算有限但又想体验AI辅助编程的开发者来说,这套方案绝对值得一试。
相关推荐
GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
基于OneBlockBase平台实测GML 5.2与DeepSeek V4多模态升级,详解视觉识别与文本协同工作流搭建、前置拦截安全机制、界面生成效果及部署配置要点,验证纯文本模型通过工作流编排升级多模态的可行方案。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。

Claude Code体系化学习:从部署到51万行源码架构全解析
系统梳理Claude Code学习路径,涵盖环境部署、国产模型接入、六大核心系统(记忆系统、多Agent协作等)、全栈ChatBot实战,以及51万行开源代码中的八大设计模式解析。