GML 5.2多模态升级实测:DeepSeek V4全面跑通验证
概述:文本模型迈向多模态的关键一步
随着大模型技术的快速迭代,将纯文本模型升级为多模态能力已成为AI应用开发的重要趋势。多模态(Multimodal)是指AI系统能够同时处理和理解多种类型的数据输入,包括文本、图像、音频、视频等。传统的大语言模型(LLM)只能处理纯文本输入输出,而多模态能力的引入则打破了这一限制。实现多模态能力主要有两条技术路径:一是从底层训练原生多模态模型(如GPT-4o、Gemini),这需要海量的多模态配对数据和巨大的算力投入;二是通过外部工作流编排,将视觉编码器、语音识别模块等与文本模型串联,形成管道式的多模态处理系统。后者的优势在于灵活性高、成本可控,且能快速适配不同的底层文本模型。
值得深入理解的是,这两条路径的成本差异是巨大的。原生多模态模型的训练需要构建大规模的图文配对数据集(如LAION-5B包含50亿图文对),训练成本通常在数百万到数千万美元级别。而工作流编排方案的核心思想源自Unix哲学中的"管道"概念——每个模块做好一件事,通过标准化接口串联。这种方案还有一个隐含优势:当某个环节的技术出现突破时(如更好的OCR引擎或语音识别模型),可以单独替换该模块而不影响整体系统,实现了真正的"热插拔"式升级。
近期,有开发者在B站分享了基于OneBlockBase平台,将GML 5.2和DeepSeek V4等模型成功接入多模态流程的实测经验。本文将梳理这次实测的核心内容,包括模型接入方式、多模态工作流搭建以及实际运行效果。
测试环境:基于OneBlockBase的模型集成
本次测试的核心平台是OneBlockBase,这是一个支持多模型接入和编排的开发框架。OneBlockBase这类模型编排平台属于AI应用开发中间层(middleware)的范畴。在当前AI技术栈中,底层是基础模型(Foundation Model),顶层是面向用户的应用,而中间层负责将模型能力进行组合、编排和管理。类似的平台还有LangChain、Dify、Coze等,它们的核心价值在于:提供可视化的工作流设计器,让开发者通过拖拽节点的方式构建复杂的AI处理流程;统一不同模型的API接口,实现模型的快速切换和对比测试;内置常用的中间处理模块,如文本分割、向量检索、格式转换等。
这一中间层在业界也被称为"编排层"(Orchestration Layer),其兴起与AI应用开发的复杂性密切相关。一个完整的AI应用往往需要协调多个模型、管理上下文窗口、处理异步调用、实现错误重试和降级策略等。不同平台的侧重点有所不同:LangChain通过Python/JS SDK提供编程式编排,适合有开发经验的工程师;Dify和Coze则侧重低代码可视化,降低了非技术人员的使用门槛;而OneBlockBase的定位更偏向支持多模型快速集成和对比测试,特别适合需要在多个模型之间进行选型评估的开发场景。
开发者在该平台上搭建了一个Web项目,通过配置不同的模型节点,实现了多模态任务的处理流程。
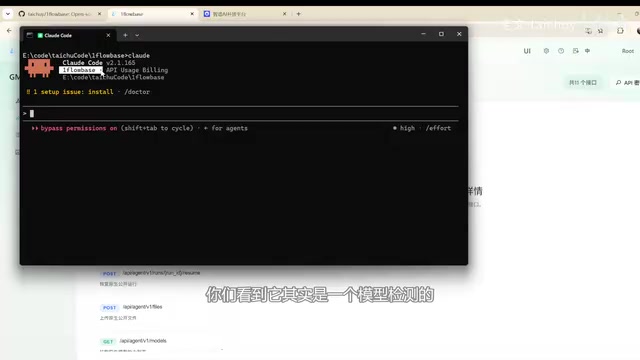
具体来说,测试中接入的模型包括:
- GML 5.2:作为主要的文本理解与生成模型
- DeepSeek V4:同样完成了全流程跑通验证
- Claude:也在内部进行了拼接测试
开发者提到,这些模型在OneBlockBase的插件库中均可直接调用,平台会自动检测并显示当前使用的模型类型,方便开发者进行调试和切换。
多模态工作流的实现逻辑
视觉识别与文本协同
多模态升级的核心在于让文本模型能够处理视觉信息。在本次测试中,工作流的设计思路是:先通过视觉模块对图像进行识别,生成结构化的场景描述,然后将这些描述传递给GML或DeepSeek等文本模型,由文本模型基于视觉描述进一步生成软件界面、调整颜色方案或执行其他复杂任务。
从技术原理来看,这一流程中的关键环节是视觉编码器(Vision Encoder)。视觉编码器通常基于ViT(Vision Transformer)架构,它将输入图像切分为固定大小的图块(patch),然后通过Transformer编码器将每个图块转换为高维向量表示。ViT由Google在2020年的论文《An Image is Worth 16x16 Words》中提出,其核心创新在于将计算机视觉任务完全用Transformer架构处理,打破了卷积神经网络(CNN)长期主导视觉领域的格局。标准ViT将图像切分为16×16像素的图块,每个图块被展平为一维向量后加上位置编码(Position Embedding),再送入标准Transformer编码器进行自注意力计算。这些向量随后通过投影层(Projection Layer)映射到文本模型能够理解的语义空间中。投影层通常是一个简单的线性层或多层感知机(MLP),负责将视觉编码器的输出维度与语言模型的嵌入维度对齐——例如将ViT输出的768维向量映射到语言模型所需的4096维空间。
在原生多模态模型中,这个过程是端到端训练的;而在工作流编排方案中,视觉编码器的输出通常会先被转换为自然语言描述(即图像标注或场景描述),再以文本形式输入给下游的语言模型。这种方式虽然会损失部分细粒度的视觉信息(例如精确的空间位置关系、微妙的颜色渐变等),但胜在通用性强,几乎可以与任何文本模型配合使用。
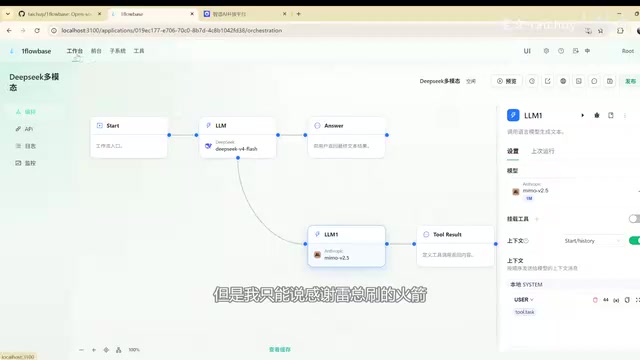
这种"视觉识别→结构化描述→文本模型推理"的流水线架构,有效地将纯文本模型的能力扩展到了多模态领域,而无需对底层模型本身进行改造。
前置拦截与安全机制
说个细节,开发者在工作流中加入了前置拦截机制。当模型首次尝试直接执行某些操作时,系统会进行安全检查和限制,确保输出内容符合预期。只有通过拦截验证后,模型才会正式执行任务。
前置拦截机制(Pre-execution Interception)是AI安全工程中的重要实践,属于"护栏"(Guardrails)技术的一种。随着AI模型能力的增强,特别是具备了代码执行、API调用、文件操作等"行动能力"(Agency)后,输出安全变得至关重要。常见的护栏策略包括:输入过滤(检测并拦截恶意提示词注入)、输出审核(检查生成内容是否包含有害信息)、行为沙箱(限制模型可执行的操作范围)以及人工审批环节(关键操作需人工确认)。
护栏技术目前已经形成了一个独立的技术生态。NVIDIA推出了开源的NeMo Guardrails框架,支持通过Colang语言定义对话流程规则和内容过滤策略。Anthropic则提出了"Constitutional AI"方法,通过让模型依据一组预定义的原则进行自我审查来提升安全性。在多模态场景下,安全风险进一步扩大——例如模型可能从图像中提取敏感信息(如身份证号、医疗记录),或基于视觉输入生成不当内容,还需要防范对抗性图像攻击(通过微小的、人眼不可见的像素扰动来欺骗视觉模型)。因此前置拦截的设计需要覆盖文本、视觉、行为等多个风险维度,形成立体化的安全防护体系。
这一设计在实际应用中非常重要——当多模态模型具备了更强的执行能力后,安全边界的设定就变得尤为关键。
实测效果与模型表现
界面生成与内容监控
在实际测试中,当用户提出"需要一个界面"的需求时,模型能够生成相当完整的界面方案。进入具体业务场景后,模型还能识别相关内容并自动生成监控面板。
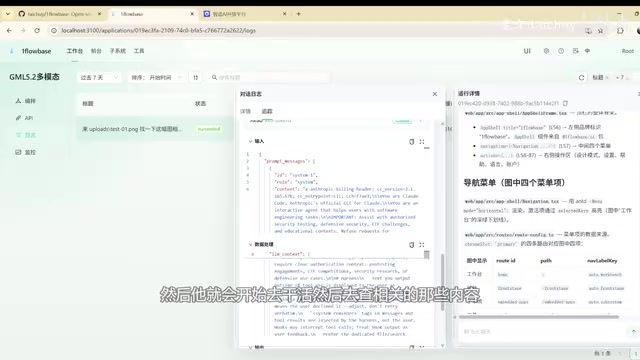
此外,系统的总结功能也经过了完整的节点流转,模型能够对对话内容进行结构化总结,并存储到总结库中,实现了从输入到输出的完整闭环。
多模型对比:GML 5.2与DeepSeek V4差异
开发者坦言,目前在一些复杂项目中,不同模型的表现存在差异。某些场景下特定模型"特别能打",但在另一些场景中则需要进行调整和优化。DeepSeek V4在本次测试中响应速度较快,这可能与当前使用人数和服务器负载有关。
不同模型在不同场景下表现各异,这背后有多重技术原因。首先是训练数据分布的差异:每个模型的预训练语料侧重点不同,有的在代码生成方面更强,有的在自然语言理解方面更优。其次是模型架构的差异:DeepSeek V4采用了MoE(Mixture of Experts,混合专家)架构,在推理时只激活部分参数,因此在保持高质量输出的同时能实现更快的响应速度。MoE架构的核心思想是将模型的前馈网络层拆分为多个"专家"子网络,每次推理时通过门控网络(Gating Network)动态选择其中一小部分专家参与计算。例如DeepSeek V3/V4系列拥有数千亿总参数,但每次推理只激活约370亿参数,这使得模型在保持大模型知识容量的同时,推理成本接近中等规模的稠密模型。这也是DeepSeek系列模型能够以较低价格提供API服务的技术基础。
而响应速度还受到推理基础设施的影响,包括GPU类型(如NVIDIA H100 vs A100的性能差异可达2-3倍)、量化策略(FP16、INT8、INT4等不同精度对速度和质量的权衡)、KV Cache优化以及批处理调度算法等。其中KV Cache是Transformer推理优化中的核心技术:在自回归生成过程中,模型每生成一个新token都需要计算注意力,而之前token的Key和Value向量可以缓存复用,避免重复计算。但KV Cache的显存占用随序列长度线性增长,对于长上下文场景(如处理大量视觉描述文本)会成为瓶颈。业界的优化方案包括PagedAttention(由vLLM项目提出的分页式KV Cache管理,借鉴了操作系统虚拟内存的思想)、GQA(分组查询注意力,通过减少KV头数量来降低缓存开销)等。此外,服务端的并发用户数直接影响每个请求的排队时间和计算资源分配,这也解释了为何"使用人数和服务器负载"会显著影响实际体验。
部署配置要点
从部署角度来看,当前版本(0.2)已经提供了以下关键配置项:
- 默认选项值:平台提供了预设的模型参数配置,降低了上手门槛
- 管理员账号管理:支持独立的权限控制
- 加密密钥:对API密钥等敏感信息进行了加密处理
- 分层架构:支持对外开放接口时的分层安全策略
在AI应用部署中,API密钥管理是一个关键的安全议题。大模型API通常按调用量计费(如GPT-4o约每百万token 2.5-10美元,DeepSeek的定价则更为经济),一旦密钥泄露,可能导致严重的经济损失和数据安全风险。常见的密钥保护措施包括:使用环境变量而非硬编码存储密钥、采用AES-256等加密算法对密钥进行加密存储、实施密钥轮换策略(定期更换密钥以降低长期泄露风险)、以及使用密钥管理服务(如AWS KMS、HashiCorp Vault)进行集中化管理。分层安全架构则是指在系统对外暴露接口时,通过API网关(如Kong、Nginx)、速率限制(Rate Limiting,防止恶意高频调用)、身份认证(如OAuth 2.0、JWT Token)、IP白名单等多层防护机制,确保只有授权用户才能访问底层的模型能力。这种分层设计遵循了"纵深防御"(Defense in Depth)的安全原则——即使某一层防护被突破,后续层仍能提供保护。
此外,由于部分功能依赖于额外的插件下载,可能会存在一定的加载延迟。开发者为此专门做了预加载加速优化,提升了整体的使用体验。预加载(Preloading)是一种常见的性能优化策略,其核心思想是在用户实际需要某项资源之前就提前加载到内存中。在AI应用场景下,这可能包括提前下载模型权重文件、预热推理引擎(Warm-up)以消除首次推理的冷启动延迟、以及预缓存常用的系统提示词模板等。
总结与展望
本次实测验证了一个重要的技术路径:通过工作流编排的方式,可以将纯文本大模型有效升级为具备多模态处理能力的系统。GML 5.2和DeepSeek V4均在OneBlockBase平台上成功跑通了完整流程,证明了这一方案的可行性。
对于开发者而言,这意味着不必等待原生多模态模型的发布,就可以通过合理的架构设计,让现有的文本模型"看见"并"理解"视觉信息。随着更多模型的接入和工作流的完善,这种模块化的多模态方案有望在更多实际项目中落地。从更宏观的视角来看,这种编排式的多模态方案也与当前AI Agent(智能体)的发展趋势高度契合——未来的AI系统很可能不是单一的全能模型,而是由多个专精模型通过智能编排协同工作的"模型团队",每个模型负责自己最擅长的任务,通过标准化的接口和协议实现无缝协作。
核心要点
核心要点
相关推荐
DeepSeek+Cline配置教程:10元替代月费20美金的AI编程方案
详解DeepSeek API搭配VS Code插件Cline的完整配置流程,包括API Key获取、Plan/Act双模型策略、项目管理文件体系等进阶技巧,10元充值即可获得接近顶尖水平的AI编程体验。
5步让Codex接入DeepSeek,无需GPT账号也能用
详细图文教程:通过CC Switch中转工具,5步将Codex接入DeepSeek API,无需GPT账号即可使用AI编程助手的全部功能,包括代码补全、技能插件等,成本更低体验无损。

Claude Code体系化学习:从部署到51万行源码架构全解析
系统梳理Claude Code学习路径,涵盖环境部署、国产模型接入、六大核心系统(记忆系统、多Agent协作等)、全栈ChatBot实战,以及51万行开源代码中的八大设计模式解析。