Generic Agent:3000行代码打造自进化AI智能体
3000行代码的Generic Agent通过自进化机制击败53万行成熟框架
Generic Agent以仅3000行核心代码和9个原子工具,通过自进化机制实现能力持续增长,在多个评测中击败拥有53万行代码的成熟框架。其核心设计包括技能固化(任务完成后自动存储为可复用技能)、五层记忆架构(支持跨会话持久记忆)以及极致的Token效率(仅为竞品六分之一),证明了AI Agent领域"少即是多"的设计哲学。
核心理念:能力不是堆出来的,是长出来的
在AI智能体领域,一个反常识的现象正在发生:核心代码仅3000行的Generic Agent,在多个评测中击败了拥有53万行代码的OpenClaw等成熟框架。它更省资源、更稳定,而且——它会自己写新技能,越用越强。
在软件工程领域,代码量与系统能力之间的关系从来不是线性的。OpenClaw等成熟Agent框架积累53万行代码,很大程度上源于「防御性编程」的惯性——为每一种可能的场景预先编写处理逻辑,为每一类工具单独开发适配器。这种「大教堂式」的构建方式在早期能快速覆盖需求,但随着代码库膨胀,维护成本呈指数级上升,新功能的引入往往需要理解并兼容大量历史逻辑。Generic Agent的3000行核心代码则代表了另一种哲学:只保留不可再简化的原语,将复杂性推迟到运行时由AI自主解决。
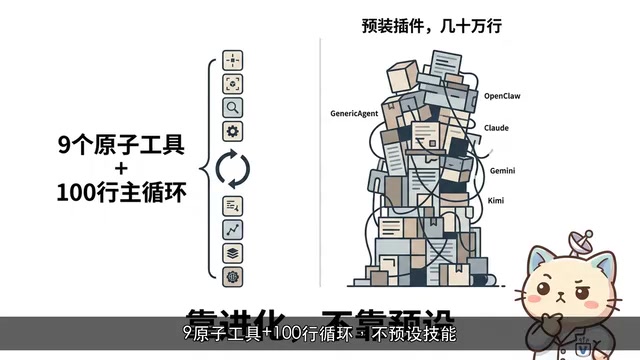
这背后的设计哲学与主流Agent框架截然不同。当大多数框架忙着用插件堆功能、用代码量换覆盖面时,Generic Agent选择了一条极简路线:9个原子工具 + 约100行主循环,不预设任何技能,全靠使用过程中自我进化。
「9个原子工具」的设计灵感与计算机科学中的「最小指令集」理念一脉相承。就像RISC架构用少量精简指令通过组合实现复杂运算,Generic Agent的原子工具(浏览器、终端、文件系统、键鼠、屏幕视觉、ADB等)覆盖了计算机交互的基本维度。理论上,任何复杂任务都可以被分解为这些原子操作的序列组合。关键的突破在于:过去需要人类程序员来完成这种「分解与组合」,而现在大语言模型具备了足够的推理能力来自主完成这一过程。这使得「少量工具 + 强推理」的路线在2024年后才真正具备实用价值。
自进化机制:从笨拙到熟练的自我成长
技能固化:一次折腾,终身受益
Generic Agent最核心的特性是「自进化」。用一个具体场景来说明:
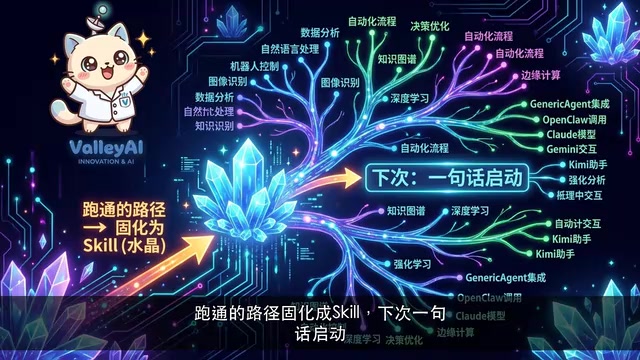
第一次让它监控股票,它需要自己安装依赖、编写脚本、反复调试,整个过程可能相当曲折。但关键在于——这条跑通的路径会被固化为一个技能存储下来。下次再提出同样的需求,一句话就能启动,无需重复折腾。
任务做得越多,它积累的技能库就越丰富。这不是简单的缓存或模板复用,而是真正意义上的经验积累与能力生长。
Generic Agent的技能固化机制,在学术上与「程序合成」(Program Synthesis)和「少样本学习」(Few-shot Learning)领域的研究高度相关。当Agent首次完成一项任务时,它实际上完成了一次从自然语言需求到可执行程序的合成过程。将这个过程的产物(调试通过的脚本、参数配置、执行路径)持久化存储,本质上是在构建一个由实际使用驱动的「程序库」。这与DeepMind在Voyager(Minecraft AI Agent)中提出的「技能库」概念相似,但Generic Agent将其应用于真实计算机环境,挑战性更高——现实世界的网站结构、API接口、系统环境远比游戏沙箱复杂多变。
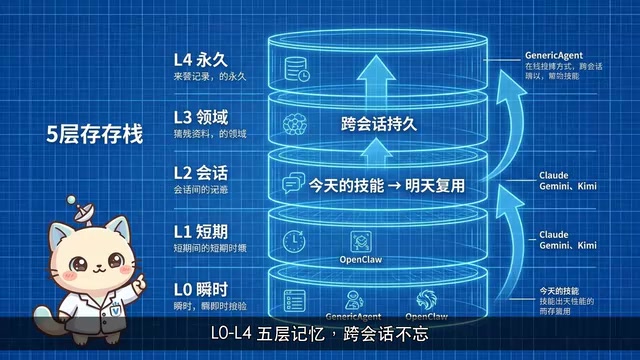
五层记忆架构:跨会话的持久记忆
Generic Agent采用了从L0到L4的五层记忆结构来管理知识和技能。这种分层设计的核心优势在于:跨会话也不会遗忘。今天学会的技能,明天可以接着用,真正实现了能力的持续积累。
这一架构在设计上借鉴了认知科学对人类记忆系统的分层模型。人类记忆被分为感觉记忆、工作记忆、短期记忆、长期记忆等层次,不同层次在容量、持久性和提取速度上各有侧重。AI Agent的记忆架构面临类似的工程权衡:L0层通常对应当前上下文窗口内的即时信息(类似工作记忆),L4层则对应经过高度抽象和压缩的长期技能知识。跨会话持久化的核心技术挑战在于「记忆检索」——当任务到来时,如何从庞大的历史技能库中快速定位最相关的经验,这通常依赖向量数据库和语义相似度搜索来实现。
这与大多数AI Agent框架形成了鲜明对比——后者往往在每次新会话中都要从零开始,无法利用历史经验。
极简架构下的全面能力
3000行代码能做什么?
别被代码量迷惑,Generic Agent的能力覆盖相当全面:
- 浏览器操控:注入真实浏览器,保留登录态
- 终端操作:直接执行命令行任务
- 文件系统:读写、管理本地文件
- 键鼠输入:模拟人类操作
- 屏幕视觉:理解屏幕内容
- 移动设备:通过ADB控制手机
基本上你电脑能做的事,它都能触及。
真实浏览器注入:一个聪明的设计决策
值得单独说说浏览器注入策略。浏览器自动化领域长期存在两种技术路线的争论:沙箱方案(如Playwright、Puppeteer启动独立浏览器实例)的优势在于环境隔离、安全可控,但代价是每次任务都需要重新建立会话状态,面对需要登录的网站时往往束手无策或需要额外的凭证管理系统。真实浏览器注入(通过Chrome DevTools Protocol连接用户已运行的浏览器)则直接继承了用户的完整会话状态——包括Cookie、LocalStorage、已登录账户等。
与沙箱方案不同,Generic Agent直接注入用户的真实浏览器环境,保留已有的登录状态和Cookie。这意味着它不需要每次都重新登录各种网站,所有必要的上下文都已就绪。这种方式在隐私和安全上需要更高的信任度,但在实用性上大幅领先,特别适合个人助手类场景——Generic Agent选择后者,是一个明确的「实用优先」价值取向的体现。
Token效率:仅为竞品的六分之一
在大模型应用中,Token消耗直接关联使用成本和响应速度。Token消耗在大模型应用中扮演着类似「燃料效率」的角色,直接决定了产品的商业可行性。以GPT-4o为例,输入Token约0.005美元/千Token,一个消耗20万Token上下文的Agent任务,仅上下文成本就达1美元,若每天执行数十次任务,月成本可轻松突破数百美元。Generic Agent在这方面的表现堪称惊艳:
- 上下文窗口不到3万Token,而很多Agent动辄20万起步
- 同样的任务,Token消耗仅为竞品的六分之一
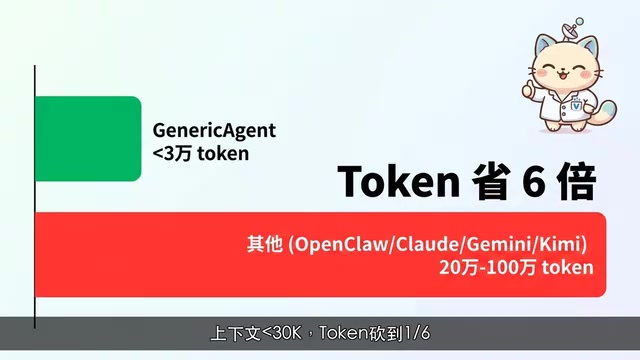
Generic Agent将上下文压缩至3万Token以内,背后依赖的是精心设计的「上下文压缩策略」——只保留当前任务最相关的记忆片段,而非将全部历史信息塞入上下文。这种「按需加载」的记忆机制,与数据库索引的设计思想异曲同工。省Token就是省钱,同时也意味着更快的响应速度。随着技能库成熟,Agent能直接调用已验证的技能而非重新推理,进一步压缩Token消耗,形成正向飞轮。
在SWEBench、Lifelong Agent Bench等多个评测中,Generic Agent在工具使用效率、Token消耗和请求数上据称全面领先。SWEBench(Software Engineering Benchmark)是目前AI Agent领域最具权威性的评测基准之一,由普林斯顿大学于2023年发布,从GitHub真实Issue中提取任务,要求Agent在实际代码仓库中定位Bug、编写修复代码并通过测试,全程无人工干预。Lifelong Agent Bench则专注于评测Agent在持续多任务场景下的表现,特别关注知识积累和迁移能力,这与Generic Agent的自进化设计理念高度契合。更关键的是,测试表明它在连续多轮执行后,能收敛到稳定的低成本状态——这正是自进化机制带来的红利。
目前Generic Agent支持Claude、Gemini、Qwen等主流大模型,兼容性良好。
冷静思考:极简路线的机遇与挑战
Generic Agent提出了一个值得深思的方向:AI智能体的能力,是否一定要靠代码量和插件数来堆砌?
它的自进化思路确实优雅——用最少的预设,通过实际使用来生长能力。这种方式有几个明显优势:
- 维护成本低:3000行代码的维护难度远低于53万行
- 适应性强:不依赖预设技能,理论上可以适应任何新场景
- 成本可控:Token消耗随技能积累持续降低
但也需要正视潜在的挑战:
- 初次执行新任务时的成功率和效率如何?
- 技能库膨胀后的管理和冲突问题怎么解决?
- 在复杂企业场景中,极简架构是否足够健壮?
正如原作者所言,「能不能真打过成熟框架,还得让子弹飞一会儿」。但无论最终结果如何,Generic Agent至少证明了一件事:在AI Agent的设计中,少即是多并非空谈,自进化可能是比堆功能更有生命力的路径。
核心要点
- Generic Agent仅用3000行核心代码和9个原子工具,通过自进化机制实现能力增长,无需预设技能
- 采用五层记忆架构(L0-L4),借鉴认知科学分层记忆模型,支持跨会话的技能积累和持久记忆
- Token消耗仅为竞品的六分之一,上下文窗口不到3万Token,大幅降低使用成本
- 能力覆盖浏览器、终端、文件系统、键鼠、屏幕视觉和移动设备控制,注入真实浏览器保留登录态
- 在SWEBench等多个评测中表现优异,提出了「能力是长出来的而非堆出来的」这一AI Agent新范式
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。