Agent Loop核心机制详解:从零构建ReAct循环(附踩坑实录)
深入解析AI Agent核心机制Agent Loop的原理、实现与常见陷阱
本文作为「Build your own Claude Code」系列第四期,详细讲解了AI Agent的核心运行机制——基于ReAct架构的Agent Loop。文章阐述了其"推理-行动-观察"的循环流程,重点分析了Tool Call ID的作用、上下文管理策略,并通过实际踩坑经历揭示了一个关键Bug:必须将Assistant消息原样回传到上下文中,否则会导致Agent无限循环。
什么是Agent Loop
在当前基于大模型的AI Agent工具中,Agent Loop(智能体循环)是最核心的运行机制。无论是Claude Code、Cursor还是其他Coding Agent,它们的底层都遵循同一个架构模式——ReAct(Reasoning + Acting),即推理加行动的循环模型。
ReAct架构最早由Yao等人在2022年的论文《ReAct: Synergizing Reasoning and Acting in Language Models》中提出。在此之前,学术界对大模型的研究主要沿着两条独立路线展开:一条是Chain-of-Thought(思维链)推理,让模型通过逐步推理来解决复杂问题;另一条是Action-based方法,让模型直接与外部环境交互。ReAct的核心贡献在于将这两条路线统一到一个交替执行的框架中——模型先进行推理(Reasoning),生成行动计划,然后执行行动(Acting),观察结果后再进入下一轮推理。这种设计显著降低了幻觉率,因为模型可以通过实际的工具调用来验证自己的推理,而不是凭空生成答案。如今,几乎所有主流的AI Agent框架——从LangChain到AutoGPT——都以ReAct作为默认的推理范式。
本文是「Build your own Claude Code」系列的第四期,我们将深入探讨如何实现一个自动执行任务的Agent Loop,理解其工作原理,并通过实际编码中的踩坑经历来加深对上下文管理的认知。
ReAct架构:推理与行动的循环
Agent Loop的基本工作流程
Agent Loop的核心思想并不复杂:用户通过自然语言输入任务,大模型进行推理,在需要时调用工具获取信息,工具的输出再作为下一轮的输入,如此循环直到任务完成。
具体流程如下:
- 用户输入:通过自然语言描述任务
- 大模型推理:基于System Prompt和上下文进行推理
- 工具调用判定:模型决定是否需要调用工具(如读取文件、获取网页信息等)
- 工具执行:执行对应的工具操作,获取结果
- 结果回传:将工具输出作为下一轮输入,继续循环
- 任务完成:当模型判断任务已完成时,输出最终结果并退出循环
这些工具可以包括网页内容获取(fetch)、文件读写、通过LSP获取代码文档等。其中,LSP(Language Server Protocol,语言服务器协议)是由微软在2016年为VS Code开发并开源的一套标准化协议,用于在编辑器和语言分析工具之间提供统一的通信接口。它支持代码补全、跳转到定义、查找引用、悬停文档等功能。在Coding Agent的上下文中,LSP作为工具被调用时,可以为大模型提供精确的代码结构信息——比如某个函数的完整签名、参数类型、所在文件位置等——而不需要模型去"猜测"或扫描整个代码库。这种结构化的代码理解能力是Cursor等产品实现精准代码编辑的关键技术基础之一。
所有这些工具的核心目的是减少大模型产生幻觉的概率,尽可能提升Agent自动化完成任务的准确度。
从单轮对话到多轮循环:关键的跨越
在前几期中,我们已经实现了单轮对话——发送一个Prompt,获取一次响应,如果有工具调用就执行一次。但真正的AI Agent需要的是持续循环:上一轮的输出成为下一轮的输入,直到任务彻底完成。
工具调用(Function Calling / Tool Use)作为大模型API的标准能力,经历了快速的演进过程。OpenAI在2023年6月首次在GPT-3.5和GPT-4的API中引入了function_calling参数,随后在同年11月将其升级为更通用的tools参数,支持并行调用多个工具。Anthropic则在2024年为Claude模型引入了类似的tool_use能力。两家的API在设计哲学上略有不同:OpenAI采用JSON Schema定义工具参数,模型返回结构化的function调用;Anthropic则将工具调用嵌入到content block中。但核心模式一致——模型通过特殊的stop_reason(如tool_calls或tool_use)来表明它希望调用工具而非直接回复用户,这个信号正是Agent Loop中判断是否继续循环的关键条件。
伪代码逻辑大致如下:
初始化 messages = [system_prompt, user_input]
while True:
response = call_llm(messages)
messages.append(response) # 关键:将模型输出原样塞回
if response 包含 tool_call:
result = execute_tool(tool_call)
messages.append({tool_call_id, result}) # 带上ID回传
else:
print(response.content)
break
实现过程中的关键细节
Tool Call ID:工具结果与语义请求的桥梁
每次模型返回工具调用时,会携带一个唯一的Tool Call ID。在下一轮将工具结果回传给模型时,必须带上这个ID。
这是因为模型的注意力机制需要通过这个ID,将工具返回的结果与之前的语义请求精确对应。从技术原理上说,Transformer架构中的注意力机制(Attention Mechanism)通过Query、Key、Value矩阵运算来确定序列中每个token应该"关注"哪些其他token。当对话历史中存在多个工具调用时,Tool Call ID本质上充当了一种显式的对齐信号——它帮助注意力机制在长序列中快速定位"哪个工具结果对应哪个调用请求",而不需要模型仅凭语义相似度来推断这种对应关系。这类似于数据库中的外键约束,提供了一种结构化的关联方式,使得模型在处理复杂的多工具并行调用场景时也能保持准确的上下文追踪。
从原理上说,没有ID理论上也能工作,但主流大模型API(如OpenAI、Anthropic)通常强制要求携带此ID——否则模型可能认为输出不可靠,导致推理质量下降。
上下文管理:简单但至关重要
在成熟的AI Agent产品中,通常会有专门的上下文管理模块,包含压缩、摘要等策略。但在我们的原型中,上下文管理就是简单的messages.append()——虽然简单,但必须做对。
值得注意的是,当前主流大模型的上下文窗口虽然在不断扩大(如Claude的200K tokens、GPT-4 Turbo的128K tokens),但在实际的Agent Loop场景中,上下文消耗速度远超普通对话。每一轮循环都会累积模型响应和工具输出,尤其是读取文件等操作可能一次就注入数千tokens。生产级Agent通常采用多层次的上下文管理策略:滑动窗口法保留最近N轮对话;摘要压缩法用另一个模型将历史对话压缩为简短摘要;重要性评分法根据与当前任务的相关性对历史消息进行优先级排序。Claude Code在实际实现中就包含了上下文压缩机制,当对话历史接近窗口上限时会自动触发压缩,同时保留关键的工具调用结果和决策节点。对于我们的原型来说,理解这些策略的存在有助于后续的工程化演进。
踩坑实录:Assistant消息必须原样回传
问题现象:Agent陷入无限循环
在实际编码过程中,我遇到了一个构建Agent Loop时非常典型的Bug:Agent陷入了无限循环,模型不断调用工具但永远无法完成任务。
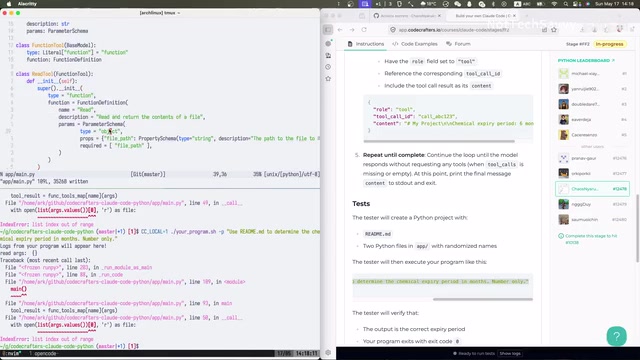
具体表现为:
- 工具被反复调用,参数为空
- 模型似乎"忘记"了之前已经调用过工具
- 循环无法正常终止
根因分析:上下文链条断裂
经过排查,发现问题出在上下文构建上:没有将模型的Assistant响应原样塞回messages列表。
正确的做法是,在每一轮Agent Loop循环中需要往messages中追加两条记录:
- 模型的完整响应(包含tool_call信息的assistant消息)——告诉模型"你之前决定要调用工具"
- 工具执行的结果(带有对应tool_call_id的tool消息)——告诉模型"工具返回了什么"
如果只塞了工具结果而漏掉了assistant消息,模型就无法建立完整的推理链条,导致它不断重复调用工具或产生错误的推理。这是构建Agent Loop时最常见也最隐蔽的Bug之一。
从大模型的工作原理来看,这个问题的本质在于:大模型是无状态的。每次API调用对模型来说都是一次全新的推理过程,它完全依赖messages列表来"回忆"之前发生了什么。如果messages中缺少了assistant消息,模型看到的上下文就是"用户提了一个问题,然后突然出现了一个工具结果",它无法理解这个工具结果是谁发起的、为什么会出现,自然也就无法在此基础上继续正确推理。这与人类对话中的逻辑类似——如果你只告诉某人一个答案,却不告诉他之前问了什么问题,他很难理解这个答案的意义。
修复后的核心代码
while True:
response = client.chat.completions.create(
model=model,
messages=messages,
tools=tools
)
choice = response.choices[0]
# 关键:将模型的完整响应原样追加到messages
messages.append(choice.message)
if choice.finish_reason == "tool_calls":
for tool_call in choice.message.tool_calls:
result = execute_tool(tool_call.function.name, tool_call.function.arguments)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": result
})
else:
print(choice.message.content)
break
从原型到产品的工程思考
当前原型的局限
我们的Agent Loop实现非常简洁,但也意味着缺少很多生产级特性:
- 上下文管理:仅使用简单的append,没有压缩和摘要策略,长对话会很快超出token限制
- 错误处理:缺乏完善的异常处理和重试机制
- 循环保护:没有设置最大循环次数,理论上可能陷入无限循环
- 工具种类:目前只有read_file一个工具,实际Agent需要更丰富的工具集
在生产环境中,这些问题都需要系统性地解决。例如,Claude Code和Cursor等产品在循环保护方面通常会设置多层防护:最大迭代次数限制、单次任务的token预算上限、以及基于时间的超时机制。错误处理方面则需要考虑API调用失败的指数退避重试、工具执行异常时的优雅降级(比如文件不存在时返回明确的错误信息而非让整个循环崩溃)、以及网络波动时的断点续传能力。这些工程化细节虽然不影响对核心原理的理解,但却是从"能跑的Demo"到"可靠的产品"之间最大的鸿沟。
Agent Loop的核心价值
尽管简单,这个原型已经展示了Agent Loop最核心的四个概念:
- 循环驱动:while循环持续运行直到任务完成
- 上下文累积:每轮对话的输入输出都追加到消息列表
- 工具协作:模型决定何时调用工具,工具结果反馈给模型
- 自然终止:当模型认为任务完成时,返回最终结果并退出循环
有了这个Agent Loop机制和工具调用框架,后续扩展write_file等新工具就变得非常容易——只需要注册新的工具定义和实现对应的执行函数即可。
总结
Agent Loop是所有AI Agent工具的核心引擎。通过本期的实现和踩坑,我们可以提炼出三个关键经验:
- 模型响应必须原样回传,以维护完整的推理链条
- Tool Call ID是工具结果与语义请求的桥梁,不可省略
- 上下文的完整性直接决定了Agent能否正确终止任务
掌握了ReAct架构下Agent Loop的运行机制,你就掌握了构建Claude Code等AI Agent工具的核心能力。下一期我们将实现Write工具,让Agent不仅能读取信息,还能真正"动手"完成任务。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。