CosyVoice v3.5实战:解决AI配音中的表演指导难题
引言:AI配音的「翻车」困境
在AI多角色配音的实际生产中,稳定性往往比效果更重要。B站UP主「破旺」在长期使用豆包TTS进行视频配音的过程中,遇到了一个令人头疼的问题——AI会把表演指导文本直接念出来。这个看似荒谬的Bug,却真实地困扰着每一位AI配音的深度用户。
本期视频中,他转向测试阿里的CosyVoice v3.5,发现了一条可能更稳定的技术路线。
豆包TTS的稳定性痛点
表演指导被「念出来」
在使用豆包进行AI配音时,用户通常会在文本中附带表演指导信息,例如标注某句话应该用「喜悦的、兴奋的」语气来朗读。正常情况下,豆包有90%以上的概率能正确理解这些指令,合成出符合情感要求的语音。
然而,大约每100句中就会出现1句「翻车」——AI不是按照指令调整语气,而是把「喜悦的、兴奋的」这些指导文字直接朗读出来。对于一个10分钟、约100句台词的视频来说,几乎每期都会中招。
这个问题的根源在于现代TTS系统的架构设计。TTS(Text-to-Speech,文本转语音)技术经历了从拼接合成、参数合成到如今基于深度学习的神经网络合成三个阶段。现代TTS系统通常采用端到端的神经网络架构,能够直接从文本生成高质量的语音波形。所谓「表演指导」,是指在输入文本中附加情感、语气、语速等控制信息,让合成引擎在生成语音时参考这些元数据来调整韵律和表现力。这种机制的技术难点在于,模型需要准确区分「需要朗读的文本」和「用于控制合成行为的元信息」,这本质上是一个指令跟随(Instruction Following)问题。当模型的指令理解能力出现偏差时,就会出现将控制信息当作正文朗读的情况。
排查成本极高
更棘手的是,这种错误完全随机出现,无法预测是哪一句会出问题。创作者不得不逐句听完所有合成音频,逐一排查。找到问题后,重新合成一次通常就能修复,但这种「薛定谔的Bug」让整个工作流变得极其低效。
此外,豆包在语速控制上也存在「过度响应」的问题。当表演指导中同时标注了「慢一点」的语速和重音要求时,合成结果可能会变得异常缓慢,调整幅度远超预期。这种不可控性,正是促使创作者寻找替代方案的核心原因。
CosyVoice v3.5:阿里的指令控制方案
版本差异:v3 vs v3.5
阿里的CosyVoice系列有多个版本,它们之间的能力差异值得关注:
- CosyVoice v3:支持系统预设音色,开箱即用,但表演控制能力有限,只能从预设的情感标签(喜悦、悲伤、沮丧等)中选择,语音表现较为僵硬。
- CosyVoice v3.5 Plus:支持自由的语音指令控制,表演灵活度大幅提升,但不支持系统预设音色,需要用户自行进行声音设计。
CosyVoice是阿里通义实验室推出的大规模语音合成模型,其技术路线基于大语言模型(LLM)与扩散模型的结合。与传统TTS系统不同,CosyVoice采用了「语音Token化」的思路——先将语音信号编码为离散的语音Token,再利用大语言模型的序列生成能力来预测这些Token,最后通过声码器(Vocoder)将Token还原为连续的语音波形。这种架构使得模型天然具备理解自然语言指令的能力,因为其核心推理引擎本身就是一个语言模型。v3.5版本在此基础上进一步强化了指令控制能力,支持用户通过自然语言描述来精细调控语音的情感、语速、音色等维度,而非依赖预定义的离散标签。
之前创作者一直没有深入使用v3.5的原因,正是因为它需要额外的声音设计步骤。但经过详细研究后发现,这个过程其实并不复杂。
声音设计:比想象中简单
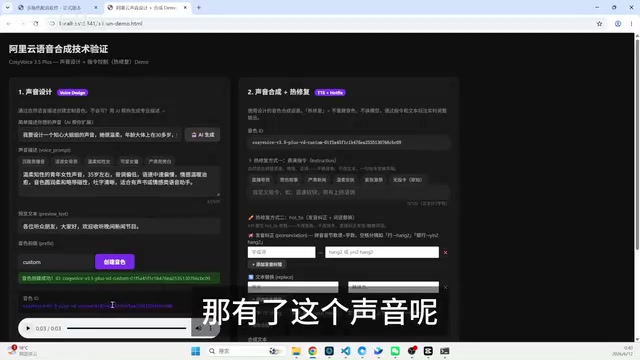
声音设计的流程可以通过自然语言描述来完成。例如,向系统描述「一个知性大姐姐的声音,温柔、30多岁、金领气质、御姐风格」,系统就会据此生成对应的声音参数。
声音设计(Voice Design)是相对于声音克隆(Voice Cloning)的另一种音色获取方式。声音克隆需要提供目标说话人的参考音频,模型通过提取说话人嵌入向量(Speaker Embedding)来复现其音色特征。而声音设计则完全基于文本描述生成全新的音色,用户无需提供任何参考音频。这背后依赖的是模型在大规模语音数据上学习到的「语义-音色映射关系」——模型理解了「温柔」「御姐」「30多岁」等描述词与声学特征之间的对应关系,从而能够根据描述合成出符合预期的音色。这种方式的优势在于灵活性极高,且不涉及真人声音的版权问题,特别适合需要大量虚构角色的内容创作场景。
实测中,系统根据描述生成了一个「温柔自信的女性声音,35岁」的音色方案,合成效果自然流畅。生成的声音ID可以直接嵌入到配音工作流中使用。
指令控制与发音纠正
CosyVoice v3.5的两大实用能力让人眼前一亮:
语音指令控制:可以通过自然语言描述来控制语气和情感。例如设置「温柔安抚的」或「紧张的」等指令,同一段文本在不同指令下会呈现明显不同的表演风格。实测中,「今天天气真好,我们一起去银行排队吧」这句话在「温柔安抚」和「紧张」两种指令下,语气差异显著且自然。
发音纠正(HotFix):这是创作者挖掘出的一个实用功能。当遇到多音字或特殊发音需求时,可以直接指定读音。例如将「行」指定为二声(xíng),或者将「天天」替换为「dayday」的发音。这种精细化控制在豆包中很难实现。
中文TTS系统面临的一个经典难题是多音字消歧(Polyphone Disambiguation)。中文中存在大量多音字,如「行」可读háng或xíng,「缝」可读féng或fèng,正确的发音取决于上下文语义。传统方案依赖前端文本分析模块中的词性标注和语言模型来自动判断读音,但在复杂语境或生僻用法中仍然容易出错。HotFix机制提供了一种「人工兜底」的解决方案,允许用户在API层面直接指定某个字或词的读音,绕过模型的自动判断。这种设计思路体现了「AI+人工」协作的工程哲学——让AI处理大部分常规情况,同时为人类保留精细干预的接口,在自动化效率和可控性之间取得平衡。
创作者特别提到,之前在使用豆包时遇到的一个经典案例——「裂缝」这个词的发音问题,无论怎么调整都无法达到理想效果(系统总是读成「缝还在」而非预期发音)。而CosyVoice v3.5的发音纠正参数可以直接解决这类问题。
大模型调试方法论:先Demo再集成
视频中还分享了一个值得借鉴的工程实践思路:
- 先读资料:详细了解API文档和各参数的能力边界
- 做Demo验证:针对每个特色参数单独编写测试脚本,快速验证效果
- 集成到项目:Demo验证通过后,再整合到完整的配音工作流中
- 反馈与修复:在实际使用中遇到问题,及时记录并迭代
这种「小步快跑」的调试策略,避免了在完整项目中排查大模型诡异问题的高昂成本。尤其是TTS这类参数众多、行为不完全可预测的AI服务,Demo驱动的开发方式能显著提升效率。这一方法论与软件工程中的「原型验证」(Prototyping)理念一脉相承——在投入大量集成工作之前,先用最小成本验证核心假设。对于AI服务而言,由于模型行为具有一定的随机性和不透明性,这种渐进式验证策略尤为重要,它能帮助开发者快速建立对模型能力边界的直觉认知,避免在集成阶段遭遇难以定位的系统性问题。
总结与展望
从实际体验来看,CosyVoice v3.5在指令控制的精确性和可预测性上,展现出了相对豆包的优势。虽然需要额外的声音设计步骤,但换来的是更稳定的表演控制和更精细的发音纠正能力。
对于AI配音的深度用户而言,「双引擎」策略可能是当前最务实的选择——利用不同TTS服务的各自优势,在稳定性和效果之间找到最佳平衡点。当前中文AI语音合成赛道竞争激烈,主要玩家包括字节跳动(豆包/火山引擎TTS)、阿里(CosyVoice/通义语音)、讯飞(星火语音合成)、百度(文心语音)以及一批创业公司如Fish Audio、ChatTTS等开源项目。各家的技术路线和产品定位各有侧重:豆包TTS以丰富的预设音色和易用性见长,CosyVoice则在指令控制和开源生态上发力,ChatTTS等开源方案则为开发者提供了更高的定制自由度。对于内容创作者而言,不同TTS服务在音色自然度、情感表现力、稳定性、延迟和成本等维度上各有优劣,采用多引擎组合策略已成为行业内的普遍实践。
随着CosyVoice v3.5的持续迭代,阿里在AI语音合成赛道上的竞争力正在快速提升。
核心要点
相关推荐
Gordon Ramsay美国荒野美食探险:沼泽、烟山与德州的味觉之旅
Gordon Ramsay在国家地理《Uncharted》中深入路易斯安那沼泽、北卡烟山和德克萨斯荒野,猎捕海狸鼠、徒手抓响尾蛇、品尝越南卡津小龙虾,探索美国多元饮食文化的根源与灵魂。

Vibe Coding实战:不懂就问,和AI沟通的正确姿势
通过真实案例演示Vibe Coding中与AI高效沟通的技巧:看不懂技术方案怎么办?如何追问发现方案漏洞?怎样确认术语一致性?掌握三个核心原则,让AI协作编程更靠谱。

AI工程化编程实战:Claude Code构建企业级项目的正确方法
深入解析Harness AI工程化编程方法论,探讨如何用Claude Code结合规范驱动开发(SDD)构建企业级项目,解决AI编程中死循环Bug、代码质量失控、幻觉风险等常见痛点,实现真正可维护的人机协作开发。