Vibe Coding实战:不懂就问,和AI沟通的正确姿势

引言:不懂就问,不丢人
在Vibe Coding的实践中,很多人会遇到一个尴尬的处境:AI提出了一套技术方案,列出了一堆变量名、文件路径和英文术语,但你看不懂。怎么办?答案很简单——问。
Vibe Coding是2025年由前特斯拉AI总监Andrej Karpathy提出的编程范式,核心理念是"完全沉浸在氛围中,拥抱指数级的东西,忘记代码的存在"。开发者不再逐行编写代码,而是通过自然语言向AI描述需求,由AI生成代码实现。这种方式大幅降低了编程门槛,使非专业开发者也能构建软件产品,但同时对需求表达能力和方案审查能力提出了更高要求。
正如UP主Paul所说:"毕竟AI就是AI,问他什么咱也不丢人。"这期内容展示了一个完整的案例:如何通过反复追问,把AI模糊的技术方案变成自己能理解、能把控的实施计划。
需求背景:实现台词的逐句修改
这次的需求场景是一个AI配音/剧本工具。当前的问题是:台词经过剧本分析定型后,就无法再修改了——不能改单句,不能改几个字,完全锁死。Paul希望实现一个"可以变更单句台词"的能力,同时还要处理后续的音频合成和字幕同步问题。
要理解这个需求的复杂性,需要了解AI配音工具的典型技术链路:首先是剧本解析(将完整剧本拆分为角色台词),然后是语音指导生成(通过大语言模型分析台词的情感、语速、重音等表演参数),接着是TTS语音合成(Text-to-Speech,将文本转化为带有情感的语音),最后是音轨拼接与字幕同步。这些环节环环相扣,修改其中任何一个节点都可能引发连锁反应——这正是Paul这次需求复杂性的根源。
他给AI的指令遵循了固定的格式:
- 扫描全局代码,收集相关信息
- 明确当前限制(台词不可变更)
- 说明目标功能(逐句修改+音频重新合成)
- 要求先调研再出方案

AI完成调研后,给出了一个涉及7个文件修改的方案。但问题来了——Paul看不懂。各种链路、变量、文件名,完全想象不出实际的用户体验是什么样的。
第一轮追问:让AI用人话解释
Paul直接说:"我没看太懂,我现在想象不出来这个台词在哪改,改了之后会发生什么。"
AI随即切换到了用户视角的描述:
- 双击台词卡片 → 变成可编辑状态
- 保存修改 → 合成按钮亮起
- 点击合成 → 利用现有接口重新生成音频
- 后端自动处理 → 完成音轨拼接
这样一解释,整个流程就清晰了。这里有个关键技巧:当你看不懂技术方案时,让AI从用户操作流程的角度重新描述,比盯着代码逻辑有效得多。
第二轮追问:发现方案漏洞
理解了基本流程后,Paul立刻发现了一个严重问题:台词修改后,声音指导和表演指导去哪了?
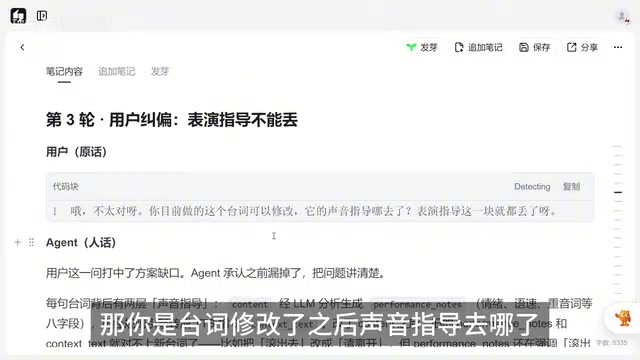
这是一个非常关键的质疑。在现代AI语音合成系统中,单纯的文本输入只能生成机械式的朗读效果。为了让合成语音具有表现力,系统需要额外的"指导信息"(Guidance/Direction),包括情绪标签(如惊喜、愤怒、悲伤)、语速控制、重音标注、停顿位置等参数。这些信息通常由大语言模型根据上下文语境自动生成,相当于给AI配音演员一份"导演指令"。如果台词内容发生变化但指导信息未同步更新,就会出现"文不对情"的问题——比如用欢快的语气读一句悲伤的台词,合成出来的就是干巴巴的朗读,方案效果大打折扣。
AI承认之前没考虑到这一点,随后给出了两个路径:
- 路径A:修改台词后,通过大语言模型重新生成指导信息
- 路径B:只改台词文本,其他标注不动,用户自己手动调整
Paul果断选A——"像我这么懒的人,让我手动处理绝对不行。"
第三轮追问:确认技术实现方式
方案确定后,还有一个关键的实现细节需要对齐。AI说要新增一个"轻量级的tool类(工具类)",但Paul的理解是应该新增一个agent。
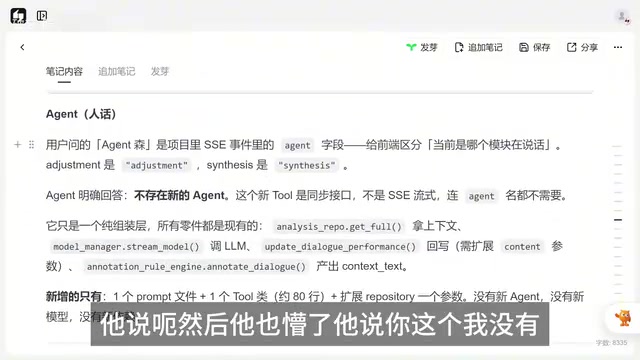
在AI应用开发中,Agent(智能体)和Tool(工具)是两个容易混淆但本质不同的概念。Tool通常是一个执行特定功能的代码模块,比如调用API、处理数据格式转换,它本身不具备决策能力。而Agent则是一个拥有独立prompt(提示词)的智能决策单元,它能理解上下文、做出判断并调用多个Tool来完成任务。在Paul的项目架构中,每个Agent对应prompts目录下的一个独立prompt文件,具有特定的角色定位和能力边界。新增一个Agent意味着引入一个新的"AI角色",而新增一个Tool只是给现有角色多一个"工具"——两者的架构影响完全不同。
两人说的"agent"完全不是一回事。Paul赶紧澄清:"我说的agent是在prompts目录里面的,一个prompt对应一个agent,目前是三个,你应该新增第四个。"
AI这才对上号:"是是是,会增加第四个。"
这个例子特别典型——同一个术语,你和AI的理解可能完全不同。如果不追问清楚,AI按照它理解的"工具类"去实现,和你期望的"新增一个prompt agent"可能差了十万八千里。
实用技巧总结
语音输入的容错性
Paul提到一个有趣的细节:用语音输入和AI对话时,很多专业术语(如LLM)可能被识别成奇怪的文字。但如果你用的是DeepSeek,它对错别字的容错能力很强,基本都能理解你的意图。这背后的原理与模型的训练数据和tokenizer设计有关——DeepSeek在中文语料上的训练更为充分,对拼音近似、形近字替换等常见语音识别错误建立了更强的语义映射能力。相比之下,GPT和其他一些模型在这方面表现较弱,可能因为一个错别字就完全误解用户意图。
三个核心原则
- 看不懂就问:不要假装理解了就让AI开干,后面返工成本更高
- 从用户视角验证:让AI描述"用户会看到什么、点击什么",而非纯技术逻辑
- 确认术语一致性:同一个词你们可能说的不是同一件事,用具体的文件路径、目录结构来对齐
Token成本不值得纠结
很多人担心反复追问会浪费token。Paul算了一笔账:这些对话能浪费几个token?几分钱甚至不到一分钱。Token是大语言模型计费的基本单位,大约每个中文字对应1.5-2个token。以DeepSeek为例,其API价格约为每百万输入token 1元人民币(缓存命中时更低至0.1元),输出token约为每百万2元。一轮包含几百字的追问对话,总token消耗通常在1000-3000之间,成本不到一分钱。相比之下,如果因为沟通不清导致AI生成了错误的代码方案,开发者可能需要花费数小时排查问题、回滚代码,时间成本远超几分钱的token费用。这也是为什么"问清楚再动手"的ROI远高于"省token"。
结语
这个案例完美展示了Vibe Coding中"人"的价值所在:你不需要看懂每一行代码,但你需要能从业务逻辑层面判断方案是否合理、是否有遗漏。Paul不懂具体的代码实现,但他知道"台词改了,指导信息不能丢"——这就是领域知识的力量。
和AI协作的本质,不是你懂技术,而是你懂需求、懂逻辑、敢追问。聊清楚了,心里有数了,AI干起活来才靠谱。
核心要点
相关推荐
CosyVoice v3.5实战:解决AI配音中的表演指导难题
深度测试阿里CosyVoice v3.5的指令控制与发音纠正能力,对比豆包TTS的稳定性痛点,分享声音设计流程、语音指令控制技巧及大模型调试方法论,为AI多角色配音提供更稳定的技术方案。
Gordon Ramsay美国荒野美食探险:沼泽、烟山与德州的味觉之旅
Gordon Ramsay在国家地理《Uncharted》中深入路易斯安那沼泽、北卡烟山和德克萨斯荒野,猎捕海狸鼠、徒手抓响尾蛇、品尝越南卡津小龙虾,探索美国多元饮食文化的根源与灵魂。

AI工程化编程实战:Claude Code构建企业级项目的正确方法
深入解析Harness AI工程化编程方法论,探讨如何用Claude Code结合规范驱动开发(SDD)构建企业级项目,解决AI编程中死循环Bug、代码质量失控、幻觉风险等常见痛点,实现真正可维护的人机协作开发。