Cursor模型选择、Context与Token机制完全指南
前言
Cursor作为当前最热门的AI编程工具之一,其内部的模型选择、上下文管理和Token计费机制是每个用户都需要理解的核心概念。本文将系统梳理Cursor的模型下拉选项、Context面板的各项指标含义,以及Token的查看与管理方法,帮助你更高效地使用这款工具。
Cursor模型下拉选项详解
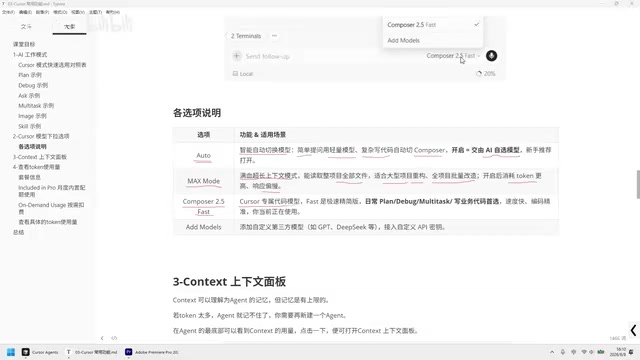
在Cursor的对话界面中,默认模型选项为Auto,点击后可以看到多个可选模型。每种模型适用于不同的使用场景,选对模型能显著提升开发效率。
Auto模式:新手首选的智能切换
Auto模式是一种智能自动切换机制。当你提出的问题比较简单时,系统会自动选择轻量级模型快速响应;当问题较为复杂时,则会自动切换到更强大的模型(如Compose)来处理。
Auto模式背后是一种**模型路由(Model Routing)**技术,这在现代AI应用架构中越来越常见。系统会先对用户输入进行意图分类和复杂度评估——比如判断是简单的语法问题还是涉及多文件的架构设计——然后根据预设规则将请求分发到最合适的模型。这种设计的核心价值在于成本优化:简单问题用小模型处理既快又省Token,复杂问题才调用大模型,实现了性能与成本的最佳平衡。类似的路由思想在OpenAI的API和各大云服务商的AI网关中也有广泛应用。
对于新手用户,建议直接使用Auto模式即可。它本质上是让AI来帮你选择最合适的模型,省去了手动判断的麻烦。
Max Mode:满血模式处理复杂任务
Max Mode适合处理复杂场景,可以理解为一种"满血超强上下文模式"。它的核心能力在于能够读取整个项目的全部文件,特别适合以下场景:
- 大型项目的架构设计
- 全项目的批量改造
- 需要跨文件理解的复杂任务
不过需要注意的是,Max Mode开启后会大量消耗Token,而且响应速度会明显偏慢。这是因为将整个项目的代码文件作为上下文输入时,Token数量可能达到数万甚至数十万级别,模型需要在更长的序列上进行注意力计算,处理时间自然会显著增加。建议仅在确实需要全局理解的场景下使用。
Compose 2.5 Fast:日常编码利器
Compose 2.5 Fast是Compose专属的代码模型,其中"Fast"代表极速经典版。对于日常的Plan、Debug、Matic Test以及业务代码编写,建议首选这个模型。
它的核心优点是:
- 速度快:响应迅速,不会让你等待太久
- 编码精准:针对代码场景优化,输出质量稳定
代码专用模型与通用模型的区别在于训练数据和微调策略的不同。代码模型通常在大量高质量代码库(如GitHub开源项目)上进行了专门训练,对编程语言的语法结构、设计模式和最佳实践有更深入的理解,因此在代码生成任务上往往比同等规模的通用模型表现更好。
Add Models:接入第三方模型
如果你有特殊需求,还可以通过Add Models选项自定义接入第三方模型,比如GPT、DeepSeek等。不过接入时需要配置自定义的API Key,适合有特定模型偏好的进阶用户。
这种开放式的模型接入设计体现了当前AI工具的一个重要趋势——模型无关性(Model Agnostic)。用户不必被绑定在单一模型供应商上,可以根据任务特点灵活选择:比如用DeepSeek处理中文相关的代码注释,用Claude处理复杂推理任务,用GPT-4o处理多模态需求等。
Context上下文机制解析
什么是Context(上下文)
Context可以理解为Agent的"记忆"。既然是记忆,就存在容量上限。当Token积累过多时,Agent就会"记不住"之前的内容,这时你需要创建一个新的Agent来开始新的对话。
从技术角度来看,上下文窗口(Context Window)是Transformer架构的核心限制之一。由于自注意力(Self-Attention)机制的计算复杂度与序列长度呈二次方关系(O(n²)),模型能同时处理的Token数量存在物理上限。早期GPT-3.5的上下文窗口仅为4K Token,而当前主流模型已扩展到128K甚至200K Token。尽管窗口在不断扩大,但当对话累积的Token接近窗口上限时,模型对早期信息的"注意力"会显著下降——这就是著名的"Lost in the Middle"现象,即模型对长文本中间部分的信息检索能力明显弱于首尾部分。这也是为什么Cursor建议用户在Context接近上限时创建新Agent的根本技术原因。
创建新Agent的方法很简单:直接点击对话列表后面的加号即可。
Context面板各项指标解读
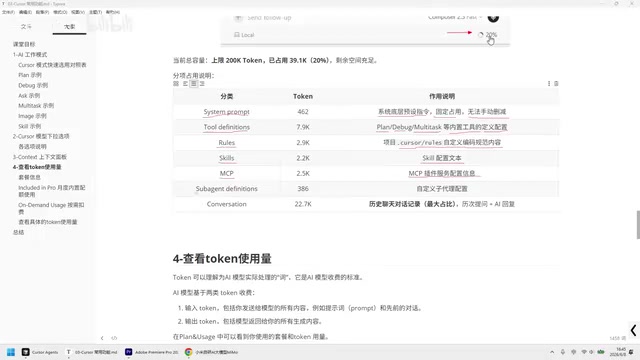
在对话界面下方,有一个百分比显示(如22%),点击后可以打开Context面板。这个面板详细展示了Token的分配情况,各项指标含义如下:
System Prompt(系统提示词):系统底层预设指令的使用量,这是固定占用的,无法手动删减。System Prompt是大语言模型对话系统中的一个特殊角色消息,它在每次对话开始前被注入,用于定义模型的行为边界、输出格式和专业领域。在Cursor中,System Prompt包含了代码生成规范、安全约束、工具调用指令等关键配置。虽然用户看不到这些内容,但它们在每次交互中都会被发送给模型,因此会持续占用一定的Token配额——这也解释了为什么即使是空对话,Context也不会显示为0%。
Tool Definitions(工具定义):Plan、Debug、Multi-file Test等内置工具的定义配置所占用的Token量。这些定义本质上是以结构化文本(通常是JSON Schema格式)告诉模型有哪些工具可用、每个工具的参数格式和调用方式。这是Function Calling机制的基础,让模型知道何时以及如何调用外部工具来完成任务。
Rules(规则):Cursor Rules资料页中编码规则的内容占用。关于Rules的具体使用方法,是一个值得深入学习的话题。Rules允许用户定义项目级别的编码规范、技术栈偏好和输出格式要求,相当于为AI设定了一套"项目手册"。
Secure Rules:对应Secure配置文件的Token使用量。这部分通常包含安全相关的约束,比如禁止生成包含敏感信息的代码、限制对特定文件的访问权限等。
MCP:MCP插件服务配置信息所使用的Token量。MCP(Model Context Protocol)是Anthropic于2024年底推出的开放协议,旨在标准化AI模型与外部工具、数据源之间的通信方式。它类似于AI领域的"USB-C接口",让不同的工具和服务能够以统一的方式接入AI应用。在Cursor中,MCP插件允许模型调用外部API、数据库查询、文件系统操作等能力,极大扩展了AI编程助手的功能边界。每接入一个MCP服务,其工具描述和配置信息都会占用一定的Context空间。
Subagent Definitions:定义子代理配置的Token使用量。子代理是一种将复杂任务分解为多个子任务、由不同专门化代理分别处理的架构模式。这种Multi-Agent设计在处理大型工程任务时特别有效,比如一个子代理负责代码生成,另一个负责测试编写,还有一个负责文档更新。
Conversation(对话记录):历史聊天对话记录,这一项的Token使用量往往是最大的。它包含了每次提问加上AI回复所累积的全部Token量。值得注意的是,由于大语言模型本身没有"记忆"能力,每次交互时都需要将完整的对话历史重新发送给模型,这意味着随着对话轮次的增加,每次请求的Token消耗会呈线性增长。这也是为什么长对话后期的响应速度会变慢、费用会增加的根本原因。
Token计费机制与费用管理
Token的基本概念
Token可以理解为AI模型实际处理的最小文本单元。AI模型基于两类Token进行计费:
- 输入Token:你在输入框中输入的内容所包含的Token数量
- 输出Token:模型返回给你的所有内容所包含的Token数量
从技术实现来看,Token是通过分词算法(Tokenization)将文本切分后得到的基本单元。主流模型普遍采用BPE(Byte Pair Encoding,字节对编码)算法进行分词,这种算法通过统计语料中高频出现的字符组合来构建词表,兼顾了词汇覆盖率和计算效率。对于英文,一个Token大约对应4个字符或0.75个单词;对于中文,一个汉字通常占1.5-2个Token。这意味着同样语义的内容,中文消耗的Token通常比英文多30%-50%。
需要特别理解的是,在Cursor的使用场景中,"输入Token"不仅仅是你手动输入的文字,还包括System Prompt、工具定义、Rules、对话历史以及被引用的代码文件等所有发送给模型的内容。这就是为什么一个看似简短的提问,实际消耗的输入Token可能远超你的预期。通常输出Token的单价是输入Token的3-4倍,因为生成文本比理解文本需要更多的计算资源。
如何查看Token使用量
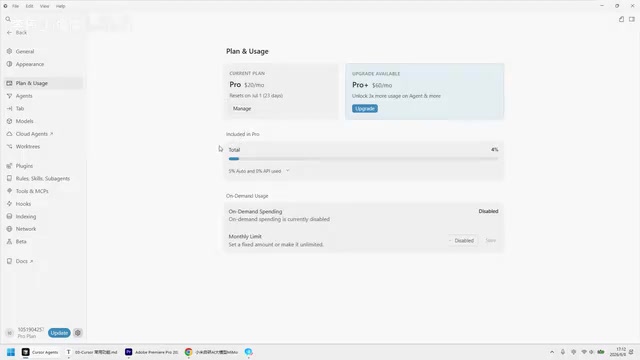
要查看所有Agent的总Token使用量,可以按以下步骤操作:
- 点击右下角的设置图标
- 选择"Plan and Usage"
- 在面板中查看当前套餐信息和本月Token使用量
Token超额处理策略
在Plan and Usage页面中,有一个"On Demand Usage"选项,用于设置Token超额后的处理方式:
- 默认关闭(推荐):Token超额后不会额外扣费,但AI模型的运行速度会变慢。系统不会禁止你使用,只是降速处理。这种机制在行业中被称为"速率限制"(Rate Limiting),是API服务商常用的流量管理手段。降速后系统可能会将你的请求排入低优先级队列,或者自动切换到较小的模型来处理。
- 开启按需扣费:超额后继续保持正常速度,但会产生额外费用。
对于个人用户,建议保持默认的不按需扣费设置即可,避免产生意外的额外开支。如果你发现月中就已经接近配额上限,可以考虑以下优化策略:减少不必要的长对话、及时创建新Agent清理上下文、避免频繁使用Max Mode、以及在Rules中精简不必要的规则内容。
总结与使用建议
掌握Cursor的模型选择、Context管理和Token机制,是高效使用这款工具的基础。核心建议如下:
- 新手直接用Auto,让AI帮你选模型
- 日常编码用Compose 2.5 Fast,速度快且精准
- 复杂全局任务用Max Mode,但注意Token消耗
- 定期关注Context百分比,及时创建新Agent避免上下文溢出
- 在Plan and Usage中监控Token用量,合理规划使用节奏
一个实用的经验法则是:当Context百分比超过70%时,就应该考虑是否需要开启新的Agent了。因为随着上下文的膨胀,不仅Token消耗加速增长,模型对早期信息的理解准确度也会下降,可能导致生成的代码与之前的讨论产生不一致。
除了本文介绍的功能外,Cursor还有Cloud Agents、Plugins、Hooks等高级功能,大家可以根据实际需求进一步探索。
相关推荐
企业AI Agent异地互联:智能组网方案全解析
企业多地部署AI Agent面临网络互通难题。本文解析如何通过智能组网方案,低成本实现异地Agent统一接入总部知识库、OA系统等内部资源,保障Agent稳定高效运行。
AI大模型原理详解:Transformer架构与测试实战指南
深入解析AI大模型核心原理,从Transformer架构到概率推算本质,详解大语言模型在测试领域的应用场景、AI应用测试挑战及应对策略,帮助测试人员快速掌握AI工具与AI测试方法论。

Codex超级Agent完全指南:从安装到多任务并行实战
全面拆解OpenAI Codex桌面端应用的安装配置、Plugin外挂、Skill技能系统、Agent.md设置及多任务并行实战,帮助零编程基础用户快速上手这款超级AI Agent工具。