大模型训练全流程解析:预训练、SFT微调与偏好对齐通俗详解

大模型训练分为预训练、有监督微调和偏好对齐三个阶段的完整流程详解
文章系统介绍了大模型的三步训练流程:预训练(学习预测下一个词)、有监督微调SFT(学习问答对话能力)、偏好对齐(通过DPO/PPO/GRPO等算法优化回答质量)。普通开发者只需关注后训练阶段,根据数据格式选择SFT或继续预训练(CPT)。同时澄清了LoRA是训练实现算法而非学习范式,并介绍了蒸馏、量化、剪枝三种模型压缩方法。
大模型是怎么来的?三步训练流程详解
我们日常使用的ChatGPT、DeepSeek、Kimi、千问等大模型,看似神通广大,但它们的诞生都要经历三个核心阶段。本文基于B站一位AI讲师的Qwen3部署与微调实战课程,用通俗易懂的方式为大家梳理大模型训练的完整知识体系。
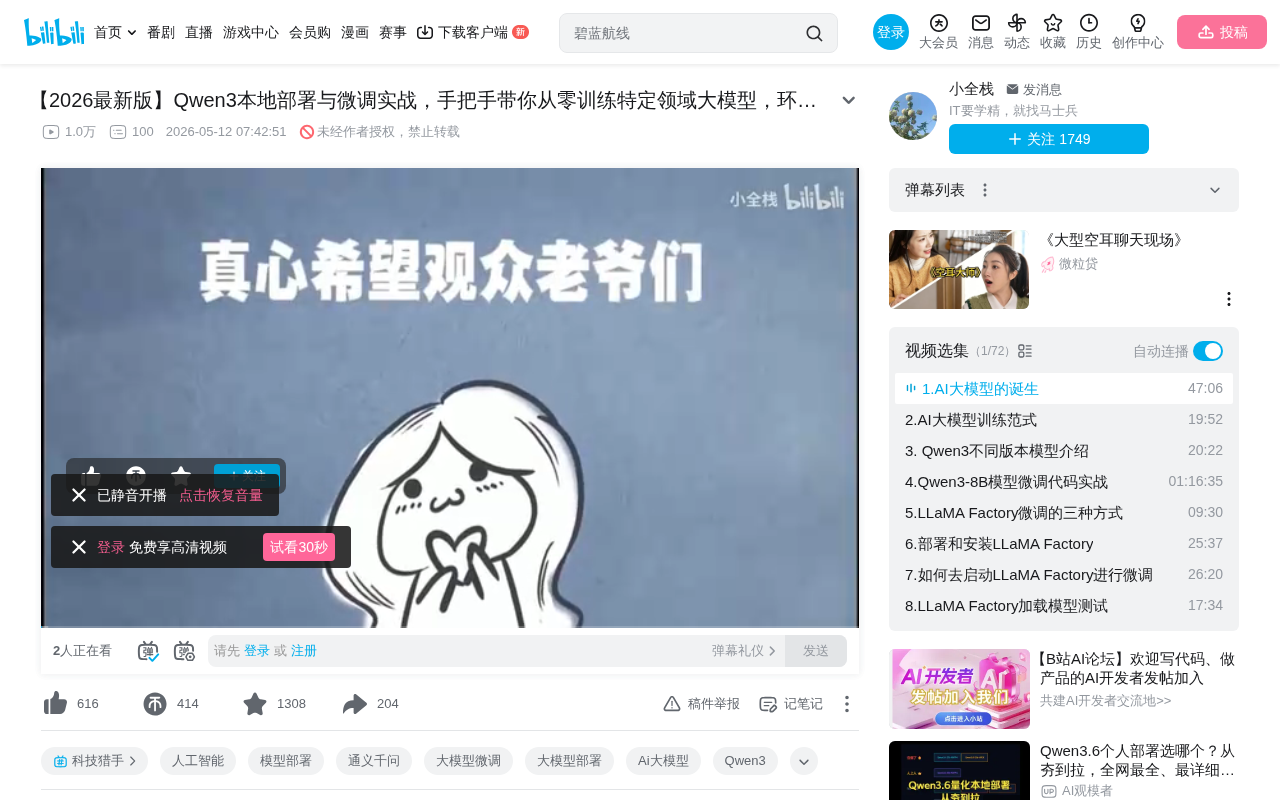
第一步:预训练(Pre-training)—— 盖毛坯房
预训练是大模型诞生的第一步,也是最耗资源的阶段。大厂会从互联网上爬取海量文本数据,经过清洗、去重、过滤违规内容后,用这些数据训练模型。
预训练的核心目标是让模型具备**预测下一个词(Predict Next Token)**的能力。当你输入"天安",模型能预测出下一个字最可能是"门";接着预测"在"、"北"、"京"……这就是生成式大模型(Generative Model)能一个词一个词往外"蹦"的底层原理。
从技术实现角度来看,Next Token Prediction是自回归语言模型的核心训练目标。模型基于Transformer架构中的因果注意力机制(Causal Attention),只能看到当前位置之前的所有token,然后通过softmax层输出词表中每个token的概率分布。训练时使用交叉熵损失函数(Cross-Entropy Loss)来衡量预测分布与真实下一个token之间的差距。这种看似简单的训练目标,在海量数据的驱动下,能让模型涌现出推理、翻译、编程等复杂能力——规模定律(Scaling Law)表明,随着模型参数量、数据量和计算量的增加,模型性能会呈现可预测的幂律提升,这也是各大厂商不断扩大训练规模的理论依据。
这个阶段就像盖毛坯房——需要大量资源(数据、服务器、时间),但产出的只是一个具备基本功能的Base Model。
第二步:有监督微调(SFT)—— 硬装修
预训练完成后,模型虽然能生成文本,但还不具备良好的对话能力。SFT(Supervised Fine-Tuning)阶段会给模型准备大量的Question-Answer问答对,让它学习"面对什么问题,应该如何回答"。
有监督微调的关键在于高质量指令数据的构造。典型的SFT数据格式包含system prompt(系统提示词)、user(用户输入)和assistant(模型回答)三个角色。训练时,模型只在assistant部分计算损失(即只学习如何回答,不学习如何提问),这种技术称为"损失掩码"(Loss Masking)。业界经验表明,数据质量远比数量重要——几千条精心标注的高质量数据,效果往往优于数万条低质量数据。此外,SFT阶段的学习率通常比预训练低1-2个数量级,以避免破坏预训练阶段学到的通用知识。
通过在有正确答案的情况下校正模型参数,模型就具备了Chat(聊天)的能力。这就像毛坯房的硬装修——装修完才能拎包入住。大厂开源的Instruct Model,就是经过这一步处理后的"精装房"。
第三步:偏好对齐(Preference Alignment)—— 软装饰
同一个问题可以有多种正确的回答方式,但哪种方式最符合用户期望?偏好对齐就是解决这个问题的。
根据具体算法的不同,数据准备方式也不同:
- DPO算法:需要准备正例(喜欢的回答)和负例(不喜欢的回答)
- PPO/GRPO算法:只需准备喜欢的回答,让模型自己探索为什么这种回答更好
深入理解这三种算法的区别:PPO(Proximal Policy Optimization)是OpenAI早期用于RLHF的经典算法,需要同时维护策略模型、参考模型、奖励模型和价值模型四个网络,训练复杂度高、显存占用大。DPO(Direct Preference Optimization)是2023年提出的简化方案,它巧妙地将奖励模型隐式地融入策略优化中,只需要策略模型和参考模型,大幅降低了训练门槛。GRPO(Group Relative Policy Optimization)则是DeepSeek提出的创新算法,它去掉了价值模型,通过组内相对排序来估计优势函数,在DeepSeek-R1的训练中展现了强大的推理能力提升效果。三种算法代表了偏好对齐技术从复杂到简洁的演进方向。
这就像软装——根据住户的个人偏好选择装饰画、绿植、家具摆放,完全按照个人喜好来定制。
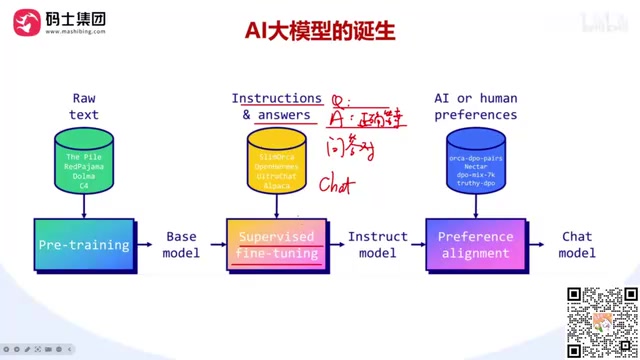
预训练 vs 后训练:普通开发者该关注什么?
在上述三步中,第一步是预训练(Pre-train),后两步统称为后训练(Post-train)。
对于一般企业和开发者来说,我们不需要做预训练。预训练是大厂的事情,需要海量数据和算力。我们要做的是后训练——拿到开源模型后,通过SFT或偏好对齐来优化它,使其适应特定业务场景。
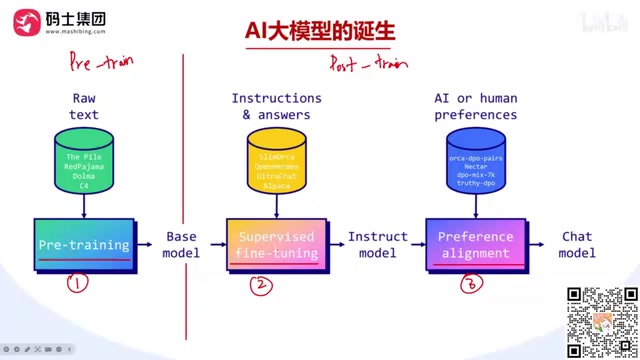
继续预训练(CPT):一种特殊情况
如果你手头的数据不是问答对格式,而是大量的领域文章(比如农业、医疗、法律文档),这时就需要做Continuous Pre-Training(继续预训练)——按照预训练的方式,用领域文章继续训练已有模型。
继续预训练在垂直领域应用中非常常见。例如,将通用大模型适配到医疗领域时,需要用大量医学文献、临床指南、病历数据进行继续预训练,使模型掌握专业术语和领域知识。CPT的数据配比是关键工程决策:除了混入通用数据防止遗忘外,还需要控制不同来源数据的比例。学习率调度通常采用余弦退火(Cosine Annealing),起始学习率设为预训练末期学习率的同一量级。此外,CPT后通常还需要再做一轮SFT,才能恢复模型的对话能力,因为CPT可能会削弱模型在SFT阶段学到的指令遵循能力。
选择哪种训练方式,取决于两点:
- 你的需求是什么——提升对话能力选SFT,增强推理能力选偏好对齐
- 你的数据是什么格式——问答对用SFT,纯文章用CPT
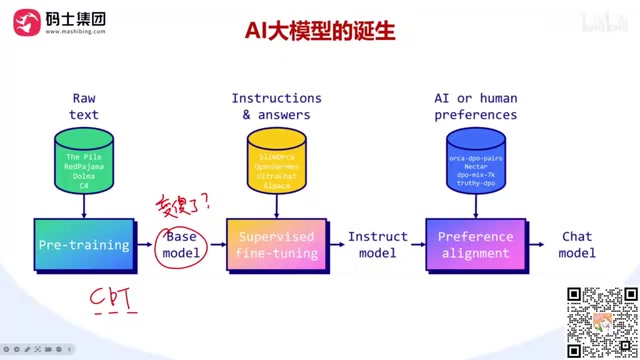
关于"遗忘"问题的解决方案
继续预训练可能导致模型"变傻"——为了记住新知识而遗忘旧知识。这在学术上被称为"灾难性遗忘"(Catastrophic Forgetting),是神经网络持续学习中的经典难题。解决方案很朴素:温故而知新。在训练时,除了新的领域语料,还混入10%-20%的原始预训练数据,让模型"复习"已有知识。
LoRA与训练范式:不是一个层面的概念
很多初学者容易混淆LoRA和SFT的关系。这里需要特别强调:
- SFT、CPT、Preference Alignment 是「学习范式」——即训练的思路和方式
- LoRA 是「具体实现算法」——即如何高效地执行这些训练
LoRA(Low-Rank Adaptation)的核心思想来源于一个重要发现:大模型在微调时,参数的变化量具有低秩特性。具体来说,对于一个d×d的权重矩阵W,LoRA不直接更新W,而是将更新量分解为两个小矩阵的乘积:ΔW = A×B,其中A是d×r矩阵,B是r×d矩阵,r远小于d(通常r=8、16、64)。这样可训练参数量从d²降低到2dr,大幅减少显存占用。推理时,ΔW可以合并回原始权重,不增加任何推理延迟。LoRA的变体如QLoRA(结合4-bit量化)进一步将显存需求压缩,使得消费级显卡(如单张24GB的RTX 4090)也能微调数十亿参数的模型。
不管你选择哪种后训练方式,都可以选择是否使用LoRA。它们是不同维度的概念,一个是"做什么",一个是"怎么做"。
模型瘦身三板斧:蒸馏、量化、剪枝
训练完成后要部署模型,但大模型往往占用大量显存。减小模型体积有三种主流思路:
| 方法 | 比喻 | 原理 |
|---|---|---|
| 蒸馏 | 把大面包的豆沙馅放进小蛋糕 | 用大模型(教师)指导小模型(学生)学习 |
| 量化 | 暴力把面包捏小 | 直接压缩模型参数精度 |
| 剪枝 | 修剪树的多余枝杈 | 去除神经网络中不重要的连接 |
深入了解这三种技术:知识蒸馏(Knowledge Distillation)让小模型不仅学习硬标签(正确答案),还学习大模型输出的软标签(概率分布),因为软标签包含了类别间的相似性信息,能传递更丰富的"暗知识"。量化(Quantization)将模型参数从FP32/FP16精度压缩到INT8、INT4甚至更低位数,常见方案包括GPTQ(逐层量化,适合GPU推理)、AWQ(激活感知量化,保护重要权重)和GGUF(llama.cpp生态的量化格式,支持CPU推理)。剪枝(Pruning)分为非结构化剪枝(去除单个权重,稀疏化)和结构化剪枝(去除整个注意力头或网络层),后者对硬件更友好,能获得实际的推理加速。在实际部署中,这三种方法经常组合使用,例如先蒸馏得到小模型,再对小模型进行量化。
三种方法目的相同——节省部署时的显存资源,但实现思路完全不同。
大模型岗位的技能要求
对于「大模型应用算法工程师」这一岗位:
- 应用能力占70%-80%:基于大模型做应用开发
- 算法能力占20%-30%:会微调、懂数据准备、理解背后原理
- 学历要求:至少本科,专业不限
- 核心技能:Python为主,需要掌握微调实操、参数调优、问题排查
不需要你设计一个全新的模型架构,但需要你理解原理——知道出问题时从哪个角度优化,知道每个参数设置背后的含义。强化学习(RL)相关知识也是必备的,因为偏好对齐中的PPO、GRPO等算法都基于强化学习。强化学习的核心思想是让智能体(Agent)通过与环境交互获得奖励信号来优化策略,在大模型训练中,模型就是智能体,生成的回答就是动作,人类偏好评分就是奖励信号。理解这一框架,对于掌握偏好对齐的各种算法至关重要。
核心要点
- 大模型诞生经历预训练、有监督微调(SFT)、偏好对齐三个阶段,分别对应盖毛坯房、硬装修和软装饰
- 普通开发者只需关注后训练(Post-train),包括SFT、CPT和偏好对齐,选择哪种取决于数据格式和业务需求
- LoRA是具体的训练算法(通过低秩分解减少可训练参数),SFT/CPT是学习范式,两者不在同一层面,不应混淆
- 模型瘦身有蒸馏、量化、剪枝三种方式,目的都是减少部署时的显存占用,实际中常组合使用
- 大模型应用算法工程师岗位以应用为主(70-80%),算法理解为辅,需掌握Python和微调实操能力
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。