单Agent vs 多Agent:三步决策框架帮你选对架构
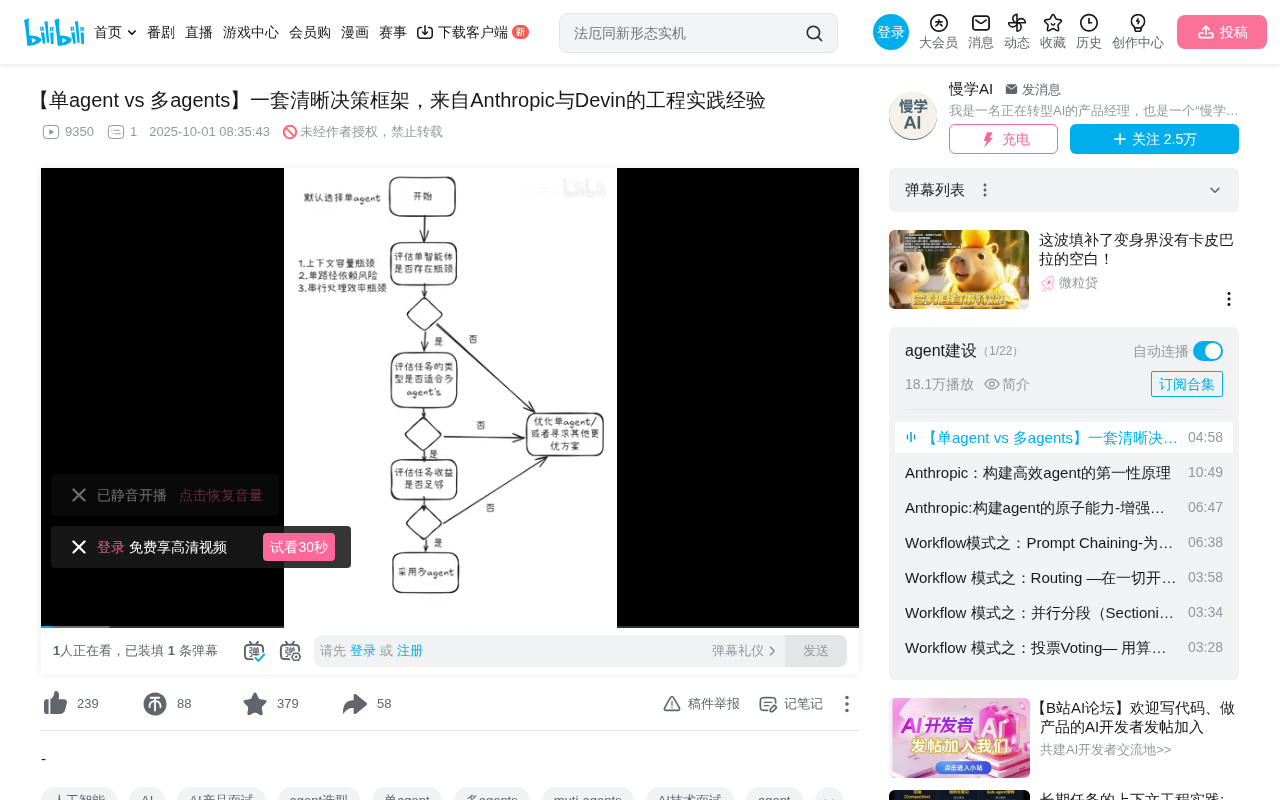
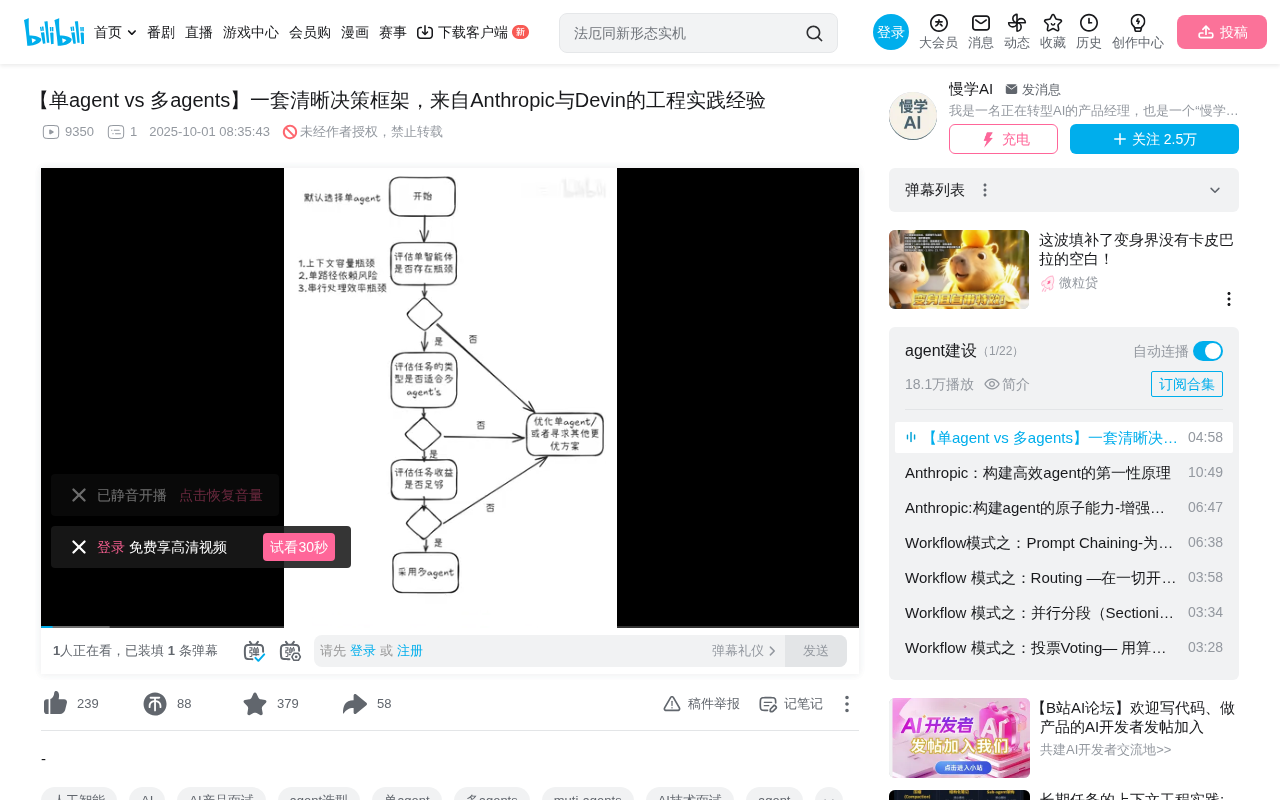
基于三步决策框架判断AI项目应选单Agent还是多Agent架构
本文提出一套系统化的单Agent vs 多Agent架构决策框架:默认从单Agent出发(简单优先原则),依次经过三步过滤——识别上下文溢出、路径依赖、串行效率等硬性瓶颈;验证任务是否可并行拆分(高耦合任务不适合);确认商业价值能否覆盖多Agent高达15倍的Token成本。三个条件全部满足才推荐采用多Agent架构,否则应通过RAG等方式优化单Agent方案。
在AI工程实践中,"单Agent还是多Agent"是一个高频出现的架构决策问题。很多人习惯性地罗列两者的优缺点,然后做一个模糊的权衡。但真正有深度的回答,需要一套系统化的决策框架。本文基于Anthropic与Devin等顶尖机构的工程实践经验,梳理出一个清晰的三步决策流程,帮助你在实际项目中做出有据可依的架构选择。
什么是Agent架构? Agent(智能体)在AI工程中指的是能够自主感知环境、制定计划并执行一系列动作以完成目标的AI系统。单Agent系统由一个大语言模型(LLM)驱动,配合工具调用(Tool Use)能力完成任务;多Agent系统则由多个协作的AI实体组成,通过消息传递或共享状态进行协调。这一架构范式的兴起与LLM的工具调用能力成熟密切相关——当模型能够可靠地调用外部API、执行代码、搜索网页时,将多个这样的能力单元组合起来完成复杂任务就成为可能。
决策原点:单Agent优先原则
在开始任何架构讨论之前,先确立一个核心思考原点:默认从单Agent架构开始。
这个理念源于Anthropic反复强调的"简单优先"原则——只有当引入复杂性能够显著改善结果时,才应该考虑它。单Agent架构是基准方案,而不是与多Agent并列的"二选一"选项。
这一点非常关键,因为它从根本上改变了思考方式。我们不是在问"该选哪个",而是在问"有没有充分的理由离开单Agent"。这种思维方式能有效避免过度工程化——在实际项目中,很多团队因为追求"看起来更高级"的架构而引入了不必要的复杂性,最终导致系统难以维护、成本飙升。
第一步:识别单Agent的硬性瓶颈
什么时候才有理由考虑升级到多Agent?答案是:当单Agent遇到了无法通过简单优化解决的硬性瓶颈时。这些瓶颈可以归纳为三类:
瓶颈一:上下文容量溢出
单Agent只有一个上下文窗口,它的"短期记忆"是有限的。对于需要处理海量信息的研究类任务——比如要同时分析几十个网页的内容——单Agent的上下文窗口很快就会被撑爆,导致信息丢失或处理质量严重下降。
上下文窗口与注意力衰减的深层机制: 上下文窗口(Context Window)是大语言模型在单次推理中能够处理的最大Token数量,决定了模型的"工作记忆"上限。早期GPT-3的上下文窗口仅有4K Token,而当前主流模型已扩展至128K甚至百万级别。然而,窗口扩大并不意味着信息利用效率等比提升。斯坦福大学2023年的研究论文《Lost in the Middle》揭示了一个关键现象:当关键信息位于超长上下文的中间位置时,模型的检索和利用效率会显著下降,而对开头和结尾的信息保持较高敏感度。这一"注意力衰减"问题意味着,即便技术上能塞入更多信息,实际的推理质量也可能因信息位置而产生不均匀的损耗。
即便当前大模型的上下文窗口已经扩展到128K甚至更长,但在实际工程中,过长的上下文往往伴随着注意力衰减问题("Lost in the Middle"),模型对中间部分信息的利用效率会显著降低。
瓶颈二:单一路径依赖的高失败风险
单Agent就像一个侦探,只能沿着一条线索追查下去。如果这条路走错了,整个任务就可能失败。
举个具体例子:研究标普500所有公司的董事会成员信息。单Agent可能采用某种单一路径去查找,一旦遇到某个网站结构变化或信息缺失,它就可能卡住。而多Agent架构则可以派出多个"侦探",各自采用不同路径和策略去独立调查,大大降低了单点失败的风险。
瓶颈三:串行处理的效率瓶颈
同样是上面那个任务,如果用单Agent一家一家公司地处理,可能需要数小时甚至更长时间。如果业务要求在短时间内完成,这种串行处理的效率就成了无法接受的瓶颈。此时,多个Agent并行处理就成为提升效率的必要手段。
关键判断:只有当单Agent确实遇到了这三类瓶颈中的至少一个,才有充分的理由去启动对多Agent方案的评估。但请注意,启动评估不等于直接采用——接下来还需要通过两个现实的过滤器。
第二步:技术可行性过滤
确认存在瓶颈后,第一个需要回答的问题是:这个任务在技术上是否适合用多Agent来解决?
核心判断标准只有一个:任务能否被拆分成多个独立的、可并行的子任务。
适合多Agent的任务特征
以生成一份市场分析报告为例,这个大任务可以清晰地拆解为:
- 子Agent A:研究主要竞争对手的产品和战略
- 子Agent B:分析宏观市场趋势和政策环境
- 子Agent C:抓取和分析用户评论与反馈数据
三个Agent各自独立工作,互不干扰,最后由一个协调者将结果汇总整合。这就是一个理想的可并行任务——子任务之间的依赖性低,接口清晰。
不适合多Agent的任务特征
反过来,有些任务天然不适合拆分。典型的例子是复杂代码编写。代码项目往往需要一个强共享的上下文,各个模块之间依赖性很高。让多个Agent同时修改一个复杂的代码库,极容易产生冲突和不一致。
Devin的工程实践印证了这一判断: Devin是由Cognition AI于2024年发布的AI软件工程师,被认为是自主Agent在软件开发领域的标志性产品。Devin能够独立完成从需求理解、代码编写、调试到部署的完整软件开发流程,其架构采用了单Agent为主、工具调用为辅的设计思路——通过赋予Agent访问终端、浏览器、代码编辑器等工具的能力,而非拆分为多个协作Agent。这一设计选择恰好印证了核心论点:对于代码编写这类高度耦合、需要强共享上下文的任务,单Agent配合丰富工具集往往优于多Agent协作。
在这种场景下,强行引入多Agent反而会增加协调成本,降低整体效率。
可以用一个工程类比来理解这个过滤器:它就像在检查手头的工程图纸,看这个项目到底能不能分包给不同的施工队独立施工,还是必须由一个团队统一完成。
第三步:商业价值过滤
技术上可行之后,还需要算一笔经济账:这个任务创造的价值,能否支撑多Agent架构的高昂成本?
根据Anthropic的官方经验数据,多Agent架构消耗的Token量可能是普通单Agent对话的15倍。这是一个非常显著的成本放大器。
为什么多Agent的Token消耗会暴增? Token是大语言模型处理文本的基本计量单位,大致对应英文中的3/4个单词或中文的1-2个汉字。主流商业API(如OpenAI、Anthropic Claude)均按Token数量计费。多Agent架构的Token消耗之所以可能达到单Agent的15倍,原因是多层次的:首先,每个子Agent的调用都需要携带完整的系统提示(System Prompt)和任务上下文;其次,Agent间的通信本身会产生大量的中间消息Token;最后,协调者Agent(Orchestrator)需要处理所有子Agent的输出并进行整合推理,这一步骤的Token消耗往往被低估。以Claude Sonnet为例,若单次对话消耗约10K Token,多Agent任务可能轻松突破150K Token,直接成本差异在量级上对商业可行性产生决定性影响。
除了直接的API调用成本,多Agent系统还带来额外的工程复杂性:
- 开发成本:需要设计Agent间的通信协议、任务分配策略、结果聚合逻辑
- 运维成本:系统的不稳定性增加,调试和监控的难度上升
- 延迟风险:Agent间的协调可能引入额外的等待时间
如果一个任务的商业价值不足以覆盖这些成本,那么即使技术上完全可行,也必须回到原点,寻找更简单、更低成本的变通方案。比如,通过优化Prompt、引入RAG检索增强、或者采用分批串行处理等方式,在单Agent框架内尽可能逼近目标。
RAG:单Agent的重要增强方案: RAG(Retrieval-Augmented Generation,检索增强生成)是一种在不增加模型参数的前提下扩展LLM知识边界的技术架构。其核心思路是:将外部知识库(文档、数据库、网页等)预先向量化存储,在推理时根据用户查询动态检索最相关的片段,再将其注入上下文供模型参考生成答案。RAG有效缓解了单Agent上下文容量的压力——通过精准检索,只将最相关的信息片段送入上下文,而非将全量数据一次性塞入。当多Agent的成本收益不合算时,结合RAG的单Agent往往能以更低成本逼近多Agent的信息处理能力,是工程实践中的高性价比降级方案。
完整决策框架总结
将以上三步串联起来,我们得到一个完整的决策流程:
- 基准设定:默认采用单Agent架构(简单优先原则)
- 瓶颈评估:检查是否存在上下文容量、路径依赖、效率这三类硬性瓶颈
- 技术过滤:验证任务是否具备并行拆分的可行性
- 价值过滤:确认商业价值能否支撑多Agent的高成本
只有当三个条件全部满足时,才推荐采用多Agent架构。
这个框架的价值在于,它不是一个简单的对比清单,而是一个有层次的决策流程。它体现了三个维度的思考:对前沿技术思想的理解(简单优先原则)、对工程实现的务实判断(技术可行性)、以及对商业价值的清醒认知(成本收益分析)。在实际项目决策或技术面试中,这种系统化的思维方式远比罗列优缺点更有说服力。
核心要点
- 决策原点是"单Agent优先",遵循Anthropic的简单优先原则,只有在引入复杂性能显著改善结果时才考虑多Agent
- 单Agent存在三类硬性瓶颈:上下文容量溢出(受"Lost in the Middle"注意力衰减影响)、单一路径依赖的高失败风险、串行处理的效率瓶颈
- 技术可行性过滤:核心判断标准是任务能否被拆分为独立的、可并行的子任务,高耦合任务(如复杂编码,参见Devin的单Agent设计)不适合多Agent
- 商业价值过滤:多Agent架构Token消耗可达单Agent的15倍(因系统提示复制、Agent间通信、协调者整合等多重因素叠加),必须确认任务价值能覆盖开发、运维和API调用的综合成本
- 完整决策流程为:基准设定→瓶颈评估→技术过滤→价值过滤,三个条件全部满足才推荐采用多Agent架构;不满足时可考虑RAG等单Agent增强方案作为替代
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。