DeepSeek-V3.2发布:编程与数学能力跻身全球第一梯队
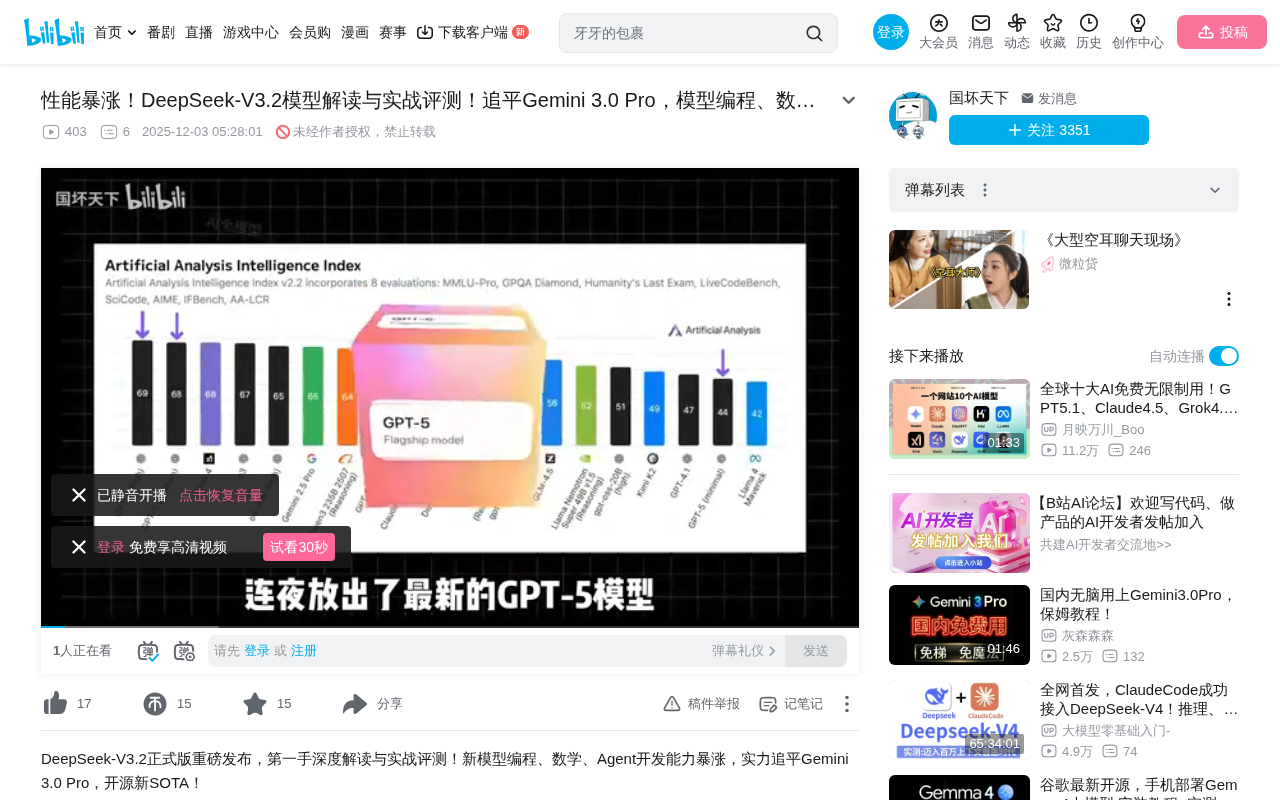
DeepSeek-V3.2追平Gemini 3.0 Pro,编程数学Agent能力刷新开源模型SOTA
DeepSeek发布V3.2版本,在编程、数学推理和Agent开发三大核心能力上追平Gemini 3.0 Pro,刷新开源模型SOTA记录。该模型基于MoE架构,总参数约6710亿但每次推理仅激活370亿,实现高效推理。此次突破证明开源模型在技术上不存在不可逾越的天花板,对降低AI使用门槛和推动行业竞争具有重要意义。
概述
DeepSeek近期发布了V3.2版本模型,在多项基准测试中追平Gemini 3.0 Pro,编程、数学和Agent开发能力跻身全球第一梯队,刷新了开源模型的SOTA记录。这一更新再次证明了国产开源大模型在全球AI竞争中的强劲实力。
DeepSeek-V3.2技术架构背景
DeepSeek系列模型采用了混合专家(Mixture of Experts, MoE)架构,这是一种通过条件计算实现高效扩展的技术路线。MoE架构的核心思想是将模型参数分散到多个"专家"子网络中,每次推理时只激活其中一部分专家,从而在保持大参数量带来的知识容量的同时,显著降低实际计算开销。DeepSeek-V3系列据报道拥有约6710亿总参数,但每次推理仅激活约370亿参数,这使得其在推理效率上远优于同等参数规模的稠密模型。正是这一架构优势,使得DeepSeek能够在有限的计算资源下持续迭代模型能力,最终在V3.2版本中实现了质的飞跃。
DeepSeek-V3.2性能提升亮点
编程能力大幅跃升
DeepSeek-V3.2在代码生成和编程任务上取得了显著进步。DeepSeek系列一直在编程领域保持着开源模型的领先地位,而V3.2版本进一步缩小了与闭源顶级模型之间的差距。
在实际编程场景中,模型能够更好地理解复杂的代码逻辑,生成更准确的代码片段,并在多轮对话中保持代码上下文的一致性。这对于开发者日常使用AI辅助编程具有重要的实用价值。值得注意的是,编程能力的评估通常涉及多个维度的基准测试,包括HumanEval(函数级代码生成)、MBPP(基础编程问题)、SWE-bench(真实软件工程任务)以及LiveCodeBench(竞赛编程)等。DeepSeek-V3.2在这些测试中的综合表现表明,其代码理解和生成能力已经从"能写代码"进化到"能解决真实工程问题"的阶段。
数学推理能力增强
数学推理是衡量大语言模型智能水平的核心指标之一。DeepSeek-V3.2在数学基准测试中的表现已追平Gemini 3.0 Pro,意味着开源模型在逻辑推理和数学问题求解方面达到了新的高度。
数学推理能力的提升通常与模型的链式思维(Chain-of-Thought, CoT)推理机制密切相关。现代大模型通过在训练过程中学习逐步分解问题、验证中间步骤的能力,显著提升了在复杂数学问题上的表现。常用的数学评测基准包括MATH(高中竞赛数学)、GSM8K(小学数学应用题)、AIME(美国数学邀请赛题目)等。DeepSeek-V3.2在这些测试中追平Gemini 3.0 Pro,意味着其在符号推理、数值计算和形式化证明等方面都达到了顶级水平。
Agent开发能力提升
Agent(智能体)开发是当前AI应用的热门方向。DeepSeek-V3.2在工具调用、多步推理和任务规划等Agent核心能力上的提升,使其成为构建AI Agent应用的有力选择。对于希望基于开源模型搭建自动化工作流的开发者而言,这是一个重要的利好消息。
AI Agent是指能够自主感知环境、制定计划并执行多步操作来完成复杂任务的AI系统。与传统的单轮问答不同,Agent需要具备工具调用(Tool Use)、任务分解(Task Decomposition)、记忆管理(Memory Management)和自我反思(Self-Reflection)等核心能力。当前主流的Agent框架包括LangChain、AutoGPT、CrewAI等,它们依赖底层大模型的函数调用和多步推理能力。模型在Agent基准测试(如BFCL、τ-bench等)上的表现直接决定了其作为Agent"大脑"的可靠程度。DeepSeek-V3.2在这些能力上的突破,意味着开发者可以基于开源模型构建出媲美GPT-4o驱动的Agent系统。
开源生态的意义
开源新SOTA的价值
DeepSeek-V3.2作为开源模型达到这一水平,其意义不仅在于性能数字本身,更在于:
- 降低使用门槛:开发者和企业可以自由部署和微调模型,无需依赖闭源API
- 推动行业竞争:开源模型的进步倒逼闭源模型持续创新
- 数据安全保障:本地部署方案为对数据隐私有要求的场景提供了可行选择
这里的SOTA(State-of-the-Art)指的是某一领域在特定时间点上的最佳技术水平。在AI研究中,刷新SOTA意味着在公认的基准测试上超越此前所有已发表模型的最高分数。需要区分的是,开源模型的SOTA与整体SOTA是两个不同概念——前者仅统计权重公开可下载的模型,后者则包含所有闭源商业模型。DeepSeek-V3.2刷新开源SOTA并追平部分闭源模型的表现,标志着这两条线正在加速收敛。
全球AI模型竞争格局
当前全球AI模型竞争异常激烈。OpenAI的GPT系列、Google的Gemini、Anthropic的Claude以及xAI的Grok都在快速迭代。DeepSeek-V3.2能够在这样的竞争环境中跻身第一梯队,展现了中国AI研究团队的技术实力。
AI大模型领域的开源与闭源之争是当前行业最核心的结构性议题之一。闭源阵营以OpenAI(GPT-4o/o3)、Anthropic(Claude 4)、Google(Gemini)为代表,通过API付费模式商业化;开源阵营则以Meta(Llama系列)、DeepSeek、Mistral、阿里(Qwen)等为代表,通过开放模型权重推动社区生态。开源模型的优势在于可本地部署、可定制微调、无供应商锁定,但此前在绝对性能上通常落后闭源模型一到两个代际。DeepSeek-V3.2的突破正在改写这一叙事,证明了开源路线在技术上并不存在不可逾越的天花板。
Gemini是Google DeepMind推出的多模态大模型系列,3.0 Pro是其最新一代中面向开发者和高性能应用的版本,定位介于轻量级的Flash版本和旗舰级的Ultra版本之间。Gemini 3.0 Pro在推理能力、长上下文处理和工具调用方面表现突出,被广泛视为当前闭源模型中的第一梯队产品。DeepSeek-V3.2能够追平这一水平,意味着开源社区首次在综合能力上触及了顶级闭源模型的天花板。
实际使用建议
适用场景
基于DeepSeek-V3.2的能力提升,以下场景值得重点关注:
- 代码开发辅助:复杂项目的代码生成、调试和重构
- 数学与科研:数学证明、数据分析、科学计算
- Agent应用开发:自动化工作流、智能助手搭建
- 通用对话:日常问答、内容创作、知识检索
部署方式
用户可以通过DeepSeek官方API、开源社区部署或第三方平台来体验V3.2模型。对于个人开发者,推荐先通过官方平台进行体验评估,再根据实际需求决定是否进行本地部署。
本地部署方面,由于DeepSeek-V3.2采用MoE架构且总参数量庞大,完整部署对硬件要求较高,通常需要多张高端GPU(如NVIDIA A100/H100)组成的集群。不过,社区已经开发了多种量化方案(如GPTQ、AWQ、GGUF等格式),可以在一定精度损失下大幅降低显存需求。对于资源有限的开发者,也可以考虑使用vLLM、SGLang等高效推理框架来优化部署效率,或通过Ollama等工具在消费级硬件上运行量化版本进行初步体验。
总结
DeepSeek-V3.2的发布标志着开源大模型在核心能力上又迈进了一大步。在编程、数学和Agent开发三个关键维度上追平甚至超越部分闭源模型,这对整个AI行业的发展都具有积极的推动作用。随着开源模型与闭源模型之间的差距持续缩小,开发者将拥有更多优质选择,AI应用的创新空间也将进一步扩大。
从更宏观的视角来看,DeepSeek-V3.2的成功也验证了一条重要的技术路径:通过精巧的架构设计(MoE)、高效的训练策略和持续的工程优化,即使在算力资源相对受限的条件下,也能训练出世界一流的大语言模型。这对于全球AI研究社区,尤其是面临算力约束的团队,提供了极具参考价值的范例。
核心要点
- DeepSeek-V3.2在编程、数学和Agent开发能力上跻身全球第一梯队
- 模型性能据称追平Gemini 3.0 Pro,刷新开源模型SOTA记录
- 开源模型达到顶级水平对降低AI使用门槛和推动行业竞争具有重要意义
- 适用于代码开发辅助、数学科研和Agent应用开发等多种场景
- MoE架构使得模型在保持大参数量的同时实现高效推理,是DeepSeek技术路线的核心优势
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。