DeepSeek V3.2发布:推理比肩GPT-5,首创思考融入工具调用
DeepSeek V3.2开源发布,推理能力比肩GPT-5,首创思考融入工具调用。
DeepSeek V3.2正式开源发布,推理能力在多项Benchmark中达到GPT-5水平,仅次于Gemini 3.0 Pro。其核心突破在于业界首创将深度思考与工具调用深度融合,从根本上解决了大模型"算不对数"的难题。长思考版本V3.2 Specialty斩获IMO 2025金牌,智能体能力达到开源最高水平,标志着开源模型首次真正逼近闭源模型天花板。
DeepSeek V3.2发布:开源社区迎来最强推理模型
DeepSeek V3.2正式发布并开源,这是继V3之后的又一次重大升级。在多项Benchmark测试中,DeepSeek V3.2的推理能力比肩GPT-5,仅次于Gemini 3.0 Pro,跻身全球第一梯队。更值得关注的是,DeepSeek V3.2首创性地将深度思考能力融入工具调用,成为业界首个实现这一突破的模型。
对开发者和普通用户来说,一个免费、开源且性能顶尖的大模型已经触手可及。
DeepSeek V3.2推理能力:兼顾深度思考与实用效率
DeepSeek V3.2的核心设计理念是平衡推理能力与输出长度,让模型更适合日常使用场景。与一些追求极致推理深度但输出冗长的模型不同,V3.2在保持强大推理能力的同时控制了输出篇幅,帮助用户更高效地获取关键信息。
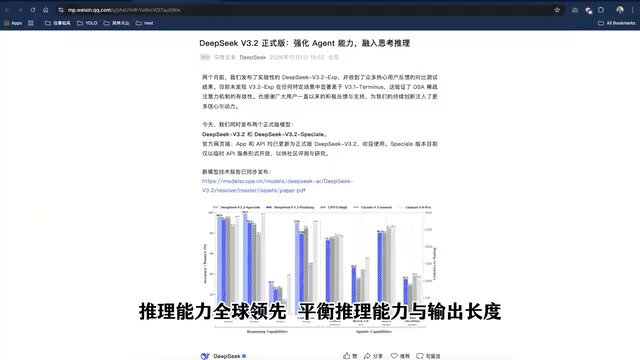
在推理类Benchmark测试中,DeepSeek V3.2的表现相当亮眼——达到了GPT-5的水平,仅次于Google的Gemini 3.0 Pro。Benchmark测试是AI领域用于衡量模型能力的标准化评估体系,常见的推理类Benchmark包括MMLU(大规模多任务语言理解)、GPQA(研究生级别问答)、ARC-Challenge(科学推理)、MATH(数学问题求解)等。这些测试覆盖逻辑推理、数学计算、代码生成、科学知识等多个维度,通过统一的评分标准让不同模型之间具备可比性。DeepSeek V3.2在多项Benchmark中均表现出色,说明其推理能力具备较强的泛化性,而非针对特定测试的过拟合优化。
作为一款完全开源的模型,这一成绩意味着开源社区首次在推理能力上真正逼近了闭源模型的天花板。DeepSeek系列模型采用的是混合专家(Mixture of Experts, MoE)架构,这是一种在保持模型总参数量巨大的同时,每次推理只激活部分参数的高效架构设计。相比传统的Dense(稠密)模型,MoE架构能够在相同计算成本下容纳更多的知识和能力。DeepSeek V3的前身采用了671B总参数、37B激活参数的MoE设计,在训练效率和推理成本上都具有显著优势。这种架构选择使得DeepSeek能够以远低于竞争对手的训练成本,达到接近甚至超越的性能水平,也是其开源策略得以持续推进的技术基础。
DeepSeek V3.2 Specialty:长思考版本斩获IMO 2025金牌
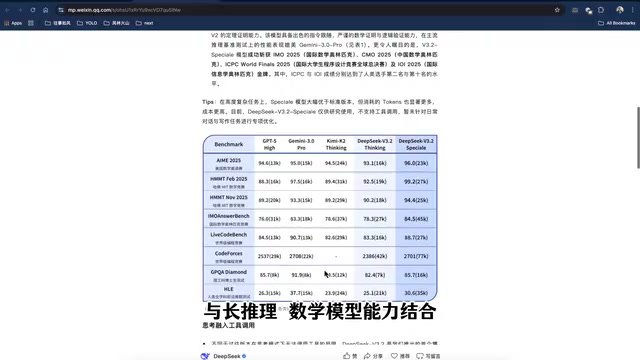
DeepSeek V3.2还推出了一个特殊版本——DeepSeek V3.2 Specialty,这是专门针对长链条推理优化的"长思考版本"。该版本在IMO 2025(国际数学奥林匹克竞赛)中成功斩获金牌,证明了其在复杂数学推理领域的顶尖实力。
国际数学奥林匹克(International Mathematical Olympiad, IMO)创办于1959年,是全球规模最大、水平最高的中学生数学竞赛,每年有超过100个国家和地区参加。IMO题目通常涉及代数、几何、数论和组合数学四大领域,每道题都需要严密的数学证明而非简单的数值计算。AI在IMO上的表现一直被视为衡量数学推理能力的终极标杆之一。2024年,Google DeepMind的AlphaProof和AlphaGeometry 2首次在IMO级别问题上达到银牌水平,引发广泛关注。DeepSeek V3.2 Specialty在IMO 2025中斩获金牌,标志着AI数学推理能力的又一次飞跃,也说明长链条推理(即模型在输出最终答案前进行大量中间推理步骤)对于解决复杂数学问题至关重要。
这也标志着AI在数学推理领域又迈出了关键一步。
核心突破:思考融入工具调用,解决大模型"算不对数"难题
如果说推理能力的提升是量变,那么思考融入工具调用就是DeepSeek V3.2最具革命性的质变。

传统大模型在面对需要精确计算的问题时,经常出现"算不对数"的情况。这背后的根本原因在于大语言模型(LLM)的核心工作原理——基于Transformer架构的自回归文本生成。模型根据已有的上下文,逐个预测下一个最可能出现的token(词元),本质上是在做概率分布上的采样,而非执行确定性的数学运算。当模型遇到"127×389=?"这样的问题时,它并不是在真正执行乘法运算,而是根据训练数据中的模式来"猜测"答案。对于简单计算,模型可能因为训练数据中见过足够多的类似案例而给出正确答案,但面对复杂或罕见的数值计算时,错误率会显著上升。
DeepSeek V3.2通过将深度思考能力与工具调用(如计算器、代码执行器等)深度融合,从根本上解决了这一痛点。工具调用(Tool Use / Function Calling)是指大模型在生成回答的过程中,能够识别出需要借助外部工具完成的子任务,自动生成结构化的函数调用请求,获取工具返回的结果后继续推理。常见的外部工具包括计算器、代码解释器(如Python沙箱)、搜索引擎、数据库查询接口、API服务等。
OpenAI在GPT-3.5时代率先引入了Function Calling功能,但早期实现中,模型的"思考过程"和"工具调用"是相对割裂的——模型先思考,再决定是否调用工具,两者之间缺乏深度交互。DeepSeek V3.2的创新在于将思维链(Chain-of-Thought)推理与工具调用深度融合,模型可以在推理链条的任意环节插入工具调用,并将工具结果作为后续推理的输入,形成"思考-调用-验证-再思考"的闭环。
具体来说,模型在推理过程中能够自主判断何时需要调用外部工具来辅助计算或验证,并将工具返回的结果无缝整合到推理链条中。这带来了三个显著优势:
- 精确处理数值计算:不再依赖概率猜测,通过实际计算获得准确结果
- 攻克复杂多步骤问题:将长推理能力与工具使用结合,解决以往难以处理的复杂任务
- 提升结果可靠性:通过工具验证推理过程中的关键步骤,有效减少幻觉和错误
DeepSeek V3.2是业界首个将思考融入工具使用的模型,这一创新为大模型的实际应用打开了全新的可能性。
智能体能力:达到开源模型最高水平
在智能体(Agent)评测中,DeepSeek V3.2达到了当前开源模型的最高水平。
AI智能体(Agent)是指能够自主感知环境、制定计划、执行行动并根据反馈调整策略的AI系统。与传统的单轮问答不同,智能体需要具备任务分解、多步规划、工具选择与使用、错误恢复、多轮交互等综合能力。目前业界常用的Agent评测基准包括SWE-bench(软件工程任务)、WebArena(网页操作任务)、GAIA(通用AI助手评测)、TAU-bench(工具使用评测)等。这些评测模拟了真实世界中的复杂任务场景,要求模型不仅能理解指令,还能自主规划执行路径并处理过程中的各种异常情况。
DeepSeek V3.2在智能体评测中达到开源最高水平,意味着它在从"对话助手"向"自主执行者"的进化中迈出了重要一步。无论是自动化工作流、数据分析,还是复杂的多步骤任务处理,V3.2都能胜任。
目前DeepSeek官网API已同步更新,开发者可以立即接入使用。
DeepSeek V3.2对AI行业的影响与展望
DeepSeek V3.2的发布对整个AI行业意义深远:
降低高质量AI使用门槛:一个推理能力比肩GPT-5的开源模型,将极大推动开源生态发展。AI大模型领域长期存在开源与闭源两大阵营的竞争。闭源阵营以OpenAI(GPT系列)、Google(Gemini系列)、Anthropic(Claude系列)为代表,通过API付费使用的商业模式运营;开源阵营则以Meta(Llama系列)、DeepSeek、Mistral、阿里(Qwen系列)等为代表,将模型权重公开供社区自由使用和二次开发。开源模型的优势在于透明性、可定制性和低成本部署,但在核心能力上通常落后于同期的顶级闭源模型。DeepSeek V3.2的出现正在改变这一格局——中小企业和个人开发者不再需要依赖昂贵的闭源API,就能获得顶级推理能力。
指明技术发展方向:思考融入工具调用的创新,为大模型发展提供了重要参考——未来的AI不仅要"会想",还要"会用工具",两者的深度融合将释放巨大潜力。
重塑行业竞争格局:当开源模型在核心能力上逼近甚至达到闭源模型的水平时,整个行业的竞争逻辑将发生根本性变化。闭源模型需要在差异化和生态服务上寻找新的护城河。
DeepSeek V3.2的发布再次证明,中国AI团队在大模型领域已经具备全球顶尖的竞争力。随着模型开源和API开放,我们有理由期待更多基于V3.2的创新应用涌现。
核心要点
- DeepSeek V3.2在推理类Benchmark中达到GPT-5水平,仅次于Gemini 3.0 Pro,成为最强开源大模型
- 长思考版本DeepSeek V3.2 Specialty斩获IMO 2025国际数学奥林匹克金牌
- 首创将深度思考融入工具调用,从根本上解决大模型算不对数的问题
- 在智能体评测中达到开源模型最高水平,官网API已同步更新
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。