DeepSeek V4深度解析:万亿参数开源模型碾压闭源对手
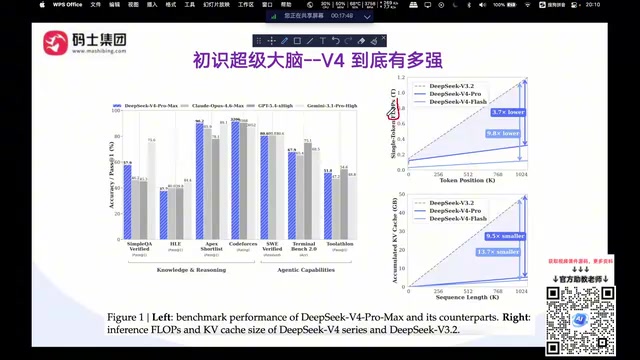
DeepSeek V4以万亿参数开源模型实现对闭源巨头的多维超越
DeepSeek V4是一款万亿参数级开源模型,在编程、百万级长文本处理、Agent能力和数学推理等方面达到或超越GPT、Claude、Gemini等闭源模型。其核心技术突破包括混合压缩注意力机制实现百万Token上下文窗口、MUON优化器提升训练稳定性,以及MoE架构实现极致性价比,为企业级AI应用提供了强大的开源替代方案。
引言:开源模型再次搅动AI格局
DeepSeek V4的发布时间颇为耐人寻味——就在GPT发布新版本后仅一两天,这款万亿参数级别的开源模型便横空出世。这已经不是DeepSeek第一次采用这种"紧跟发布"的策略了,而每一次,它都用实力证明:开源模型不仅能追赶闭源巨头,甚至可以在多个维度上实现超越。
本文将从性能对比、技术架构、成本优势和实际应用价值四个维度,对DeepSeek V4进行全面拆解。
DeepSeek V4性能对标:与GPT、Claude、Gemini的全面较量
根据DeepSeek V4论文中的Benchmark评测数据,该模型在知识(Knowledge)、推理(Reasoning)等七个核心维度上与Claude 4.6、GPT 5.4、Gemini 3.1等顶级闭源模型进行了对比。
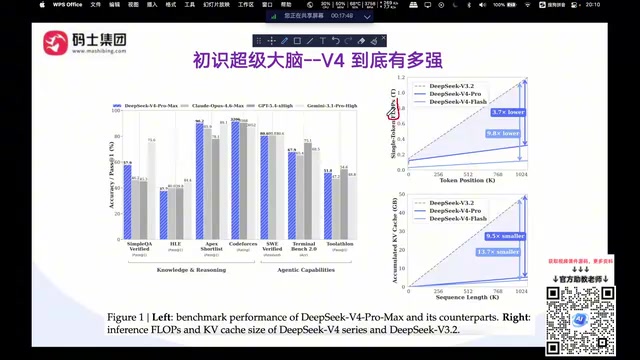
DeepSeek V4领先的核心领域
- 编程能力:DeepSeek V4 Pro在代码生成方面领先于GPT 5.4、Claude 4.6和Gemini 3.1 Pro,对于日常使用AI辅助编程的开发者来说,这是一个非常实用的优势。
- 上下文长度:支持百万级Token的上下文窗口,在长文本处理能力上位居榜首。
- Agent能力:在智能体(Agentic Capabilities)评测中排名前三,这对企业级智能化开发至关重要。
- 数学推理:表现同样不弱,处于第一梯队。
相对短板
在知识推理方面,DeepSeek V4与顶尖闭源模型相比大约落后三到六个月。不过这个差距在实际应用中影响有限——企业通常可以通过垂直领域微调来弥补特定知识的不足。
百万级长文本技术突破:DeepSeek V4的效率革命
DeepSeek V4最令人瞩目的技术突破之一,是将上下文窗口直接拉升到了100万Token(1M)。此前主流模型的上下文长度通常在8K到128K之间,而V4直接实现了数量级的跨越。
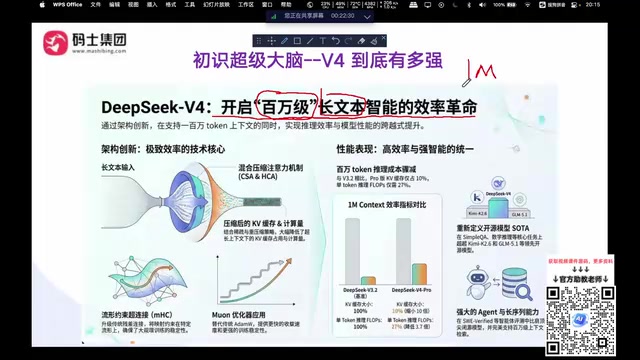
百万Token上下文意味着什么?
举个直观的例子:一份500页的报告,可以一次性完整输入给DeepSeek V4进行分析,无需手动切分成多段。
这一突破背后,涉及AI应用领域一场持续已久的技术路线之争。**RAG(Retrieval-Augmented Generation,检索增强生成)**是目前企业级AI应用中最主流的知识增强方案:通过向量数据库检索相关文档片段,再拼接进提示词供模型参考。然而RAG存在检索召回率不稳定、多跳推理能力弱等固有缺陷。随着上下文窗口的扩大,业界出现了另一种思路——直接将整个知识库塞入上下文(Long Context方案)。DeepSeek V4的百万Token窗口使得这一方案在技术上成为可能:一个中型企业的全部内部文档,理论上可以直接作为上下文输入,彻底绕开检索环节。对于RAG应用开发者来说,拼接出的超长提示词也能被高效处理,这极大地简化了工程实现的复杂度。这两种路线并非非此即彼,但V4的出现无疑大幅提升了Long Context方案的可行性边界。
背后的技术架构支撑
DeepSeek V4在架构层面引入了多项创新:
- 混合压缩注意力机制(HCA):通过CSA和HCA的组合,在保持推理质量的同时大幅降低计算开销。值得一提的是,**KV Cache(键值缓存)**是Transformer架构中用于加速自回归生成的核心机制——推理时模型会将每个Token的Key和Value向量缓存起来避免重复计算,但上下文越长,KV Cache占用的显存就越大。对于百万级Token的上下文,传统架构的KV Cache可能需要数百GB显存,远超单张GPU的容量。DeepSeek V4通过MLA(多头潜在注意力)等压缩技术,将KV Cache的显存占用压缩到前代的10%以下,这才使得百万Token上下文在工程上真正可行。
- MHC(流行约束超链接):这并非V4首创,DeepSeek此前已发表过相关论文,V4将其进一步优化并应用于万亿级参数训练。
- MUON优化器:该优化器最早由月之暗面(Kimi)团队在其k1.5技术报告中公开提出,替代了沿用多年的AdamW。MUON(Momentum + Nesterov + Orthogonalization)通过引入矩阵正交化步骤,使梯度更新方向更加规范,训练曲线更加平滑,解决了AdamW在超大规模训练中容易出现损失突刺(loss spike)甚至发散的问题。DeepSeek将其引入V4训练并进一步验证了其在万亿参数规模下的有效性,体现了中国AI研究机构之间技术成果的相互借鉴与推动。
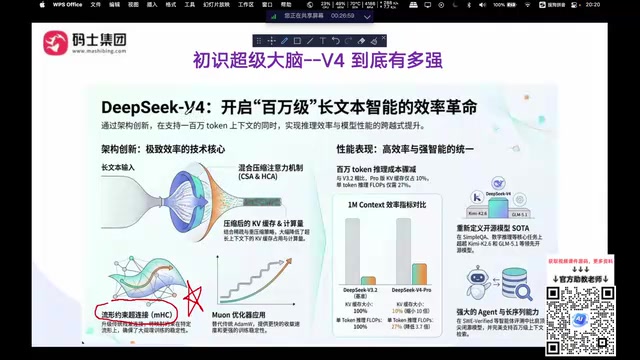
DeepSeek V4成本对比:又强又便宜的极致性价比
DeepSeek系列一直以"成本更低、模型更强"为核心理念,V4将这一点推向了新高度。
万亿参数背后的MoE架构逻辑
理解V4的成本优势,首先需要了解其万亿参数规模背后的架构基础——混合专家模型(Mixture of Experts,MoE)。MoE的核心思想是将模型拆分为多个"专家
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。