#万亿参数
共 36 篇相关文章
Trae+Claude Code+DeepSeek:低成本AI编程组合方案详解
·9 分钟
Trae+Claude Code+DeepSeek:低成本AI编程组合方案详解
详解Trae、Claude Code与DeepSeek三合一AI辅助编程方案,一周API费用仅20元。涵盖配置步骤、实际使用经验、网络拥堵应对策略及分层协作技巧,帮助开发者低成本实现高效AI编程。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。
阅读全文 →
 行业洞察
行业洞察·8 分钟
AI编程浪潮下,传统程序员的生存危机与转型之路
2025年以来AI驱动的科技裁员潮愈演愈烈,75%的编程工作可被AI覆盖。本文深度分析程序员面临的结构性淘汰危机,解读DeepSeek百万Token模型的降维打击,并探讨从代码工人转型AI架构师的具体路径。
阅读全文 →
 科技前沿
科技前沿·8 分钟
Gemini 3.5 Pro泄露解析:编程追平GPT 5.5,Spark Agent引发隐私争议
Gemini 3.5 Pro内部泄露信息解析:编程能力正面追平GPT 5.5,轻量版Flash达到92%性能却便宜20倍。Gemini Spark作为24小时AI Agent引发权限与隐私争议,深度分析谷歌在AI三巨头格局中的生态飞轮战略。
阅读全文 →
 行业洞察
行业洞察·6 分钟
AI行业一周巨变:算力竞赛、模型降价与机器人突破
本周AI领域重磅事件汇总:Anthropic联手SpaceX争夺算力,OpenAI发布GPT 5.5 Instant减少幻觉,DeepSeek V4以极低成本挑战闭源巨头,谷歌秘密测试AI代理Rimi,中国人形机器人展现惊人实力。深度解析AI产业正在经历的深层变革。
阅读全文 →
 科技前沿
科技前沿·5 分钟
AI日报:Claude自主任务超16小时,GPT5.5证明数学定理
阅读全文 →
 深度解读
深度解读·9 分钟
AI智能体入门:核心概念、技术架构与工作原理全解析
从零开始理解AI智能体(AI Agent)的核心概念,详解感知、决策、执行三大能力,对比传统程序与智能体的本质区别,深入剖析LLM、工具调用、记忆系统和RAG四大技术组件及完整工作流程。
阅读全文 →
 深度解读
深度解读·10 分钟
Transformer架构核心原理:自注意力机制与工程优化深度解析
深度解析Transformer架构核心原理,涵盖自注意力机制QKV本质、Encoder-Decoder结构、Flash Attention显存优化、RoPE位置编码、GQA推理加速等工程落地方案,助你从面试到实战全面掌握大模型底层架构。
阅读全文 →
 产品体验
产品体验·7 分钟
Kimi K2.6开源实测:300个Agent协同的调度能力到底多强
深度解析月之暗面开源模型Kimi K2.6的Agent调度能力,300个子Agent协同执行4000步任务,编程实战超越GPT-5.4,2张4090即可LoRA微调,附部署方案与性能对比。
阅读全文 →
 教程攻略
教程攻略·7 分钟
零基础入门大模型应用开发:学习路线与职业方向全解析
零基础如何入门大模型应用开发?本文详解大模型应用开发三大方向(API调用、RAG知识库、智能体Agent),梳理从Python基础到项目实战的完整学习路线,帮你快速掌握LangChain等核心框架,顺利转型AI应用开发工程师。
阅读全文 →
 前沿研究
前沿研究·7 分钟
Cursor Composer 2训练揭秘:分布式强化学习架构全解析
深度解析Cursor如何在Fireworks上训练Composer 2模型,涵盖异步流水线架构、MoE模型数值精度挑战、Router Replay技术、全球分布式GPU集群协同等核心技术方案,揭示AI编程工具从应用公司迈向基础模型公司的关键路径。
阅读全文 →
 前沿研究
前沿研究·5 分钟
Cursor Composer 2分布式RL训练技术解析
深度解析Cursor如何通过分布式强化学习训练Composer 2模型,涵盖异步流水线设计、MoE数值对齐、全球权重同步、在线离线RL协同等核心技术细节,揭示AI编程工具从应用到基础模型的转型路径。
阅读全文 →
 教程攻略
教程攻略·6 分钟
Claude Code接入DeepSeek V4:省99%成本的完整配置教程
详细教程:通过CC Switch工具将Claude Code接入DeepSeek V4,实现1%成本的AI编程方案。包含安装配置步骤、多模型协作实操演示、模型选择框架及OpenRouter免费方案。
阅读全文 →
 产品体验
产品体验·5 分钟
DeepSeek V4 Pro深度评测:对比8款旗舰模型谁更值得用
DeepSeek V4 Pro全方位横评,对比GPT 5.5、Claude Opus 4.7、GLM 5.1等8款旗舰模型,覆盖价格、编程、推理、Agent、角色扮演等维度,附场景化选购建议。
阅读全文 →
 产品体验
产品体验·6 分钟
DeepSeek V4编码实测:榜单第一Kimi翻车,Claude稳居最强
用同一个全栈小游戏任务实测DeepSeek V4、Claude Opus、GPT和Kimi K2.6四大AI编程模型。榜单排名第一的Kimi K2.6全部失败,Claude Opus一次通过。深度解读DeepSeek V4论文核心技术创新与真实编码选型建议。
阅读全文 →
 产品体验
产品体验·4 分钟
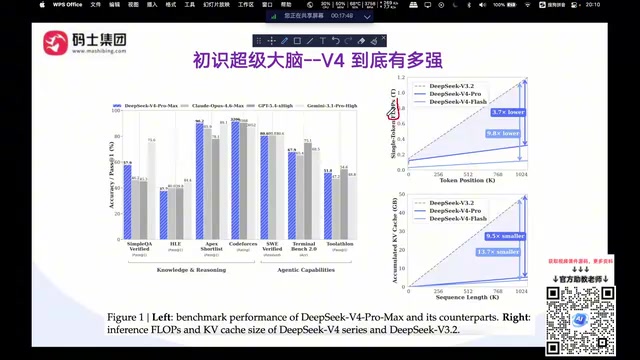
DeepSeek V4深度解析:万亿参数开源模型碾压闭源对手
深度解析DeepSeek V4万亿参数开源模型,从性能Benchmark、百万级上下文技术架构、API成本对比到MIT开源协议,全面拆解V4如何在编程、推理等维度超越GPT和Claude等闭源模型。
阅读全文 →
 教程攻略
教程攻略·5 分钟
Qwen3-0.6B微调入门:大模型基础概念与微调方法论详解
从大模型三大核心特征讲起,系统梳理Qwen3-0.6B微调所需的基础知识,包括大模型与应用软件的区别、国内外主流模型对比、微调价值分析,以及从原理到实操的完整学习路径。
阅读全文 →
 科技前沿
科技前沿·4 分钟
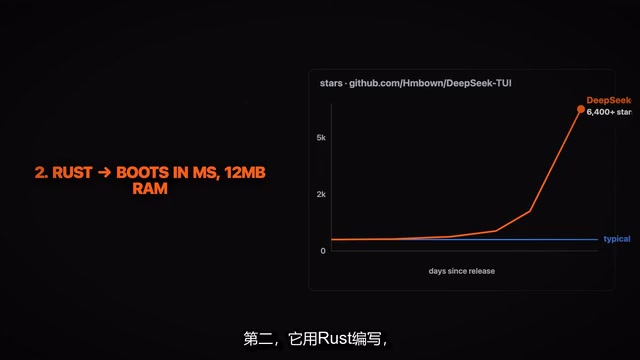
DeepSeek-TUI:免费Claude Code替代品,成本低20倍登顶GitHub
DeepSeek-TUI是用Rust编写的免费终端AI编程智能体,功能媲美Claude Code但成本低20倍。本文详解其核心功能、性能对比、适用场景,帮你判断是否值得从Claude Code迁移。
阅读全文 →
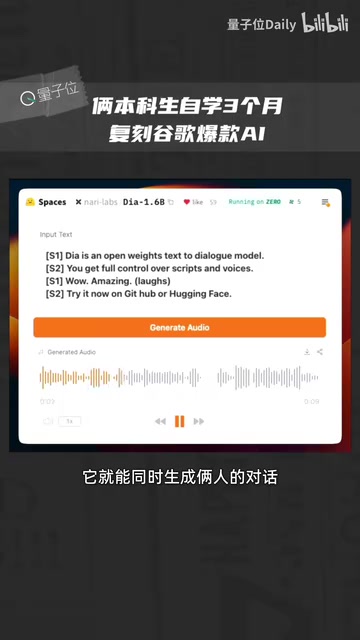 科技前沿
科技前沿·5 分钟
Dia开源项目一天5000星:两本科生3个月复刻NotebookLM播客功能
开源AI语音生成项目Dia上线一天GitHub星标破5000,由两名本科生自学3个月打造。1.6B参数实现近乎实时的双人对话生成,效果媲美谷歌NotebookLM,支持笑声、咳嗽等非语言细节模拟。
阅读全文 →
 深度解读
深度解读·4 分钟
Qwen3.5深度解析:混合注意力架构实现19倍长上下文加速
深入解析阿里开源Qwen3.5模型的混合注意力架构创新,详解Gated Delta Net如何实现256K上下文19倍加速,多模态视觉反超Gemini 3 Pro和GPT-5.2的评测数据,以及RL后训练策略与实际应用Demo。
阅读全文 →