Qwen3.5深度解析:混合注意力架构实现19倍长上下文加速

阿里开源Qwen3.5,混合注意力架构实现长上下文推理大幅加速并在多模态视觉上反超Gemini和GPT。
阿里开源的Qwen3.5(397B参数/17B激活)采用混合注意力架构,将Gated Delta Net线性注意力与常规门控注意力结合,在256K上下文下推理速度比上一代快19倍。评测方面,其指令遵循和多轮对话超越GPT-5.2,多模态视觉推理首次反超Gemini 3 Pro和GPT-5.2,但在博士级STEM推理上仍有5-6个百分点差距。
阿里近日开源了Qwen3.5,这款397B参数(仅激活17B)的混合专家模型,凭借混合注意力架构在长上下文推理上实现了惊人的加速——32K上下文比上一代快8.6倍,256K上下文快19倍。更值得关注的是,它在多模态视觉推理上首次实打实地反超了Gemini 3 Pro和GPT-5.2。本文从架构创新、评测表现和工程实践三个维度,深入拆解Qwen3.5的核心亮点。
混合注意力架构:长上下文推理的关键突破
Qwen3.5的旗舰模型全称为Qwen3.5-397B-A17B,其中A17B表示每次前向传播仅激活17B参数,激活率仅4.3%。作为对比,DeepSeek V3的671B模型激活率为5.5%,Qwen3.5的稀疏度更为激进。
混合专家模型(MoE)背景:MoE是一种将大型神经网络拆分为多个"专家"子网络的架构范式。每次前向传播时,门控网络(Router)只激活其中少数几个专家处理当前输入,而非全量参数。这种稀疏激活机制使得模型可以拥有极大的总参数量(提升容量和知识存储),同时保持较低的单次推理计算量(降低延迟和成本)。MoE架构最早由Jacobs等人于1991年提出,近年来被Google(Switch Transformer、Gemini)、Meta(Mixtral)、DeepSeek等顶级实验室大规模应用于LLM。其核心挑战在于负载均衡——如何避免所有token都路由到同一批专家,以及如何在分布式训练中高效调度专家间的通信开销。
但稀疏MoE并非新鲜事,这一代真正的架构创新在于混合注意力机制。具体来说,Qwen3.5将两套注意力机制混合使用:
- Gated Delta Net:一种线性注意力变体,状态空间复杂度从标准注意力的O(N²)降到O(N)量级,对超长上下文推理极为友好
- Gated Attention:常规注意力机制,保留对高质量短上下文任务的精度
线性注意力与Gated Delta Net技术原理:标准Transformer的自注意力机制计算复杂度为O(N²),其中N为序列长度,这意味着处理256K token时计算量是32K的64倍,KV Cache显存占用也随序列长度线性爆炸。线性注意力(Linear Attention)通过核函数近似将注意力矩阵分解,把复杂度降至O(N),代价是牺牲部分精度。Gated Delta Net是线性注意力的一种改进变体,引入门控机制动态调节状态更新幅度,并借鉴Delta Rule(增量学习规则)实现更精准的记忆写入与遗忘,在长序列任务上比早期线性注意力(如Performer、RWKV)有更好的表达能力。其状态可以理解为一个固定大小的"压缩记忆矩阵",不随序列增长而膨胀,这正是长上下文推理速度大幅提升的根本原因。
两套机制协同工作的逻辑很清晰:长上下文时主要走线性路径,避免KV Cache显存爆炸;短上下文时混合输出保精度。这个架构选择直接体现在推理速度上。
在32K上下文下,Qwen3.5比上一代Qwen3 Max快8.6倍,比同为MoE架构的Qwen3.2快3.5倍。到了256K上下文,差距扩大到19倍和7.2倍。上下文越长,混合注意力架构的优势越明显。
不过需要理性看待:19倍是256K的极端场景,日常工作负载通常在8K到32K区间,8.6倍这个数字更具参考意义。
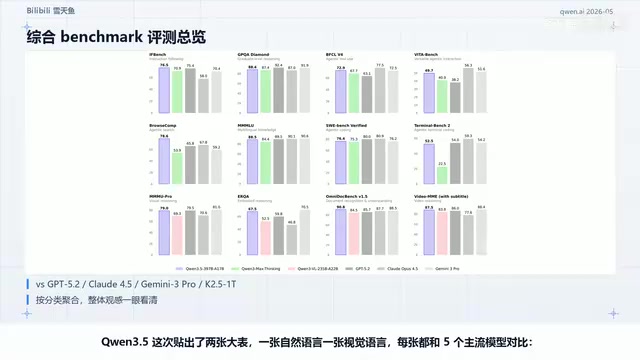
评测表现:多模态视觉首次反超Gemini 3 Pro
自然语言能力:指令遵循和多语言场景表现突出
Qwen3.5在自然语言评测中与Kimi K2.5(万亿参数级别)基本持平,部分指标反超GPT-5.2和Claude:
- 指令遵循 IFBench:76.5,超过GPT-5.2的75.4,远超Claude 4.5 Opus的58
- 多轮对话 Multi-Challenge:67.6,比GPT-5.2高出10个百分点
- 多语言数学推理:同样表现突出
但硬核STEM推理仍有差距。HLE博士级综合题Qwen3.5拿28.7,GPT-5.2为35.5;AIME 2026数学竞赛Qwen3.5得91.3,GPT-5.2为96.7,差距约5-6个百分点。开源模型在最难的推理任务上追赶闭源仍非易事。
HLE与AIME评测基准说明:HLE(Humanity's Last Exam)是由Scale AI和Center for AI Safety联合发布的超高难度综合评测集,题目由全球顶尖学者贡献,覆盖数学、物理、化学、生物、法律、历史等数十个领域的博士级难题,设计初衷是找到当前AI模型的真实能力上限。AIME(American Invitational Mathematics Examination)则是美国高中数学邀请赛,题目以代数、数论、组合数学为主,需要多步严密推理,是衡量数学竞赛级推理能力的标准基准。两者都属于"反刷榜
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。