#长上下文推理
共 24 篇相关文章
Vibe Coding工具全景盘点:从Cursor到CodeBuddy,九大…
·7 分钟
Vibe Coding工具全景盘点:从Cursor到CodeBuddy,九大主流工具怎么选
深度对比Cursor、CodeBuddy、Codex、Trae等九大主流Vibe Coding工具的优劣势、价格与适用人群。零基础小白到专业程序员,帮你找到最适合的AI编程助手。
阅读全文 →
 产品体验
产品体验·5 分钟
Codex vs Claude Code vs Cursor:AI编程三巨头实战对比与选择指南
深度对比Codex、Claude Code和Cursor三大AI编程工具的价格、稳定性、能力侧重点差异。Codex擅长UI表现,Claude Code逻辑能力强,Cursor生态成熟。附前端开发者实战选择路径与建议。
阅读全文 →
 深度解读
深度解读·9 分钟
DeepSeek V4技术深度拆解:百万Token与极致性价比
深入解析DeepSeek V4核心技术架构,包括混合压缩注意力机制、流形约束超链接和MUON优化器三大创新,详解其如何将推理成本降低10倍,实现百万Token长上下文处理,以及MIT开源协议带来的生态价值。
阅读全文 →
 教程攻略
教程攻略·10 分钟
OpenClaw进阶实战:模型精选、记忆重构与Gateway自动修复
深度解析OpenClaw进阶使用技巧,涵盖Claude Opus 4.6与GPT-5.2模型选择策略、记忆系统按主题拆分与LanceDB向量化重构、Codex深度搜索集成,以及基于systemd和Claude Code的Gateway崩溃自动修复方案。
阅读全文 →
 行业洞察
行业洞察·7 分钟
AMD MI355X击败B200:DeepSeek-R1推理TCO低5%的全栈优化解析
AMD Instinct MI355X通过SGLang+MoRI全栈优化,在DeepSeek-R1分离式推理中实现TCO比NVIDIA B200低5%,每GPU吞吐量高1.25倍。深度解析MoRI量化通信、KV Cache优化及推测解码等核心技术突破。
阅读全文 →
 产品体验
产品体验·6 分钟
Claude Opus 4.8深度解析:判断力、诚实度与性价比全面评测
深入解析Claude Opus 4.8的核心升级:判断能力提升、诚实反馈机制优化、Fast Mode成本降至三分之一。对比DeepSeek、GPT-5.5等竞品,分析Opus 4.8在AI编程和长上下文推理场景中的实际价值。
阅读全文 →
 教程攻略
教程攻略·8 分钟
Claude Code Sub-Agent:多智能体协作提升开发效率实战指南
深入解析 Claude Code Sub-Agent 子智能体机制,通过博客写作+Git提交实战案例,展示如何用多智能体分工协作解决指令丢失、上下文膨胀等问题,附创建方法与未来并行模式展望。
阅读全文 →
 教程攻略
教程攻略·7 分钟
Claude Code零基础入门:安装部署、省钱方案与源码架构解析
Claude Code零基础入门教程,涵盖安装部署步骤、新手常见问题、国内低成本替代方案,以及51万行泄露源码揭示的8大Agent设计模式深度解析。
阅读全文 →
 产品体验
产品体验·8 分钟
Gemini 3.1 Pro vs Claude Opus 4.6:五项实测谁更强
通过SVG图形生成、交互组件、网站构建、复杂推理等五个真实场景,实测对比Gemini 3.1 Pro与Claude Opus 4.6的实际表现,附综合评价与分层使用建议。
阅读全文 →
 产品体验
产品体验·7 分钟
4×3080Ti本地部署千问3.6 27B跑OpenCode编程实测
使用4张3080Ti 16G魔改显卡本地部署千问3.6 27B FP8模型,配合OpenCode完成系统管理工具开发的完整实测。涵盖硬件配置、推理速度、上下文管理经验及开发效率对比。
阅读全文 →
 行业洞察
行业洞察·2 分钟
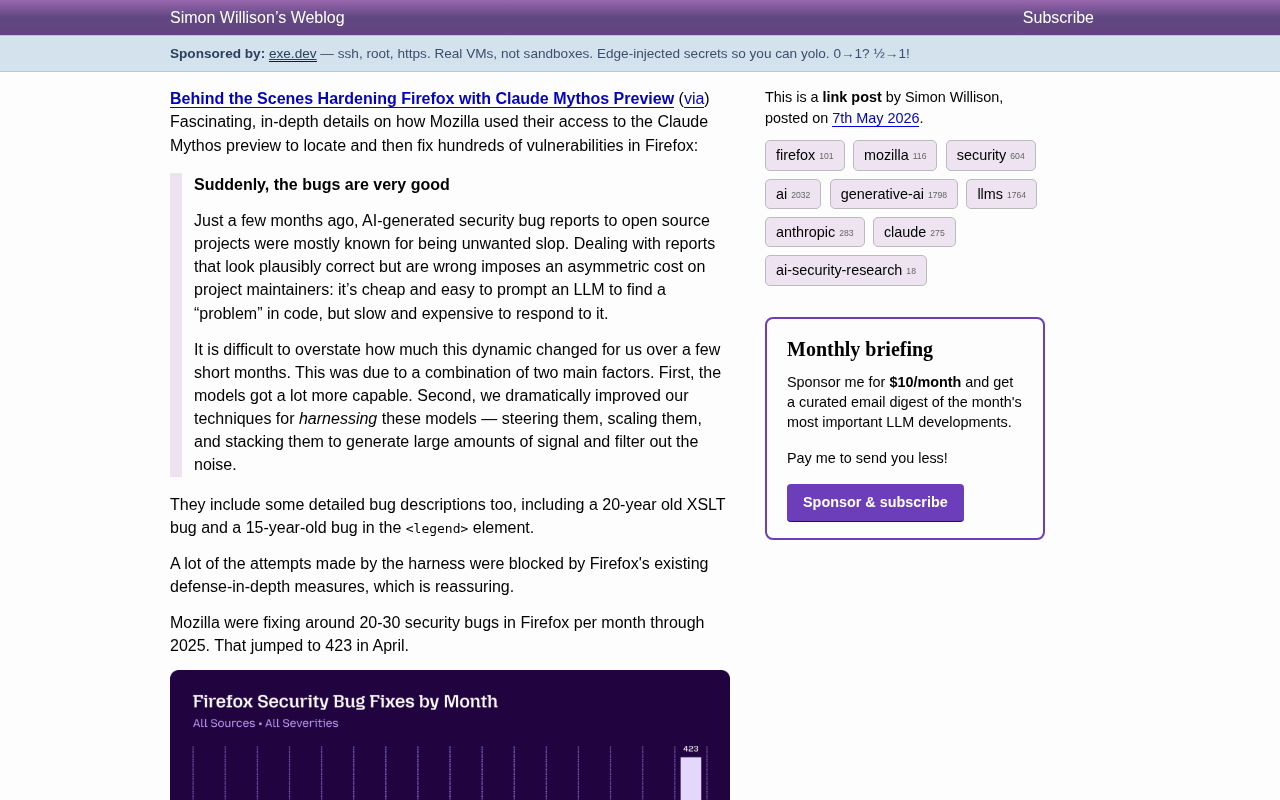
Mozilla用Claude Mythos一个月修复423个Firefox安全漏洞
Mozilla利用Anthropic Claude Mythos预览版,在Firefox代码库中一个月修复423个安全漏洞,较此前月均20个实现20倍效率提升,发现了存在20年的XSLT漏洞等深层问题,标志着AI辅助安全研究进入生产力工具阶段。
阅读全文 →
 产品体验
产品体验·3 分钟
Gemini 3.1 Pro编程实测:跑分第一实战第三,与Claude和GPT真实对比
实测对比Gemini 3.1 Pro、Claude Opus 4.6和GPT 5.3 Codex的真实编程能力。通过跨项目迁移和CLI转Web UI两道实战题,揭示Benchmark第一的Gemini在复杂任务中翻车的真实表现。
阅读全文 →
 观点碰撞
观点碰撞·6 分钟
Token Maxing:YC CEO用AI实现400倍编程效率的方法论
YC CEO Gary Tan停止编码13年后,通过Token Maxing方法论用Claude Code在5天内完成原本需400万美元的项目。详解他15个Agent并行、Plan-Eng-Review技能框架及G-Stack开源工具的实战工作流。
阅读全文 →
 产品体验
产品体验·5 分钟
GLM5.1编程实测:真实代码能力与性价比深度评测
实测GLM5.1 AI编程助手的真实代码能力,覆盖前端开发、小工具编写等场景。分析其中小型任务表现、长上下文稳定性短板及Token消耗问题,帮你判断这款高性价比AI代码助手是否值得入手。
阅读全文 →
 深度解读
深度解读·4 分钟
Qwen3.5深度解析:混合注意力架构实现19倍长上下文加速
深入解析阿里开源Qwen3.5模型的混合注意力架构创新,详解Gated Delta Net如何实现256K上下文19倍加速,多模态视觉反超Gemini 3 Pro和GPT-5.2的评测数据,以及RL后训练策略与实际应用Demo。
阅读全文 →
 产品体验
产品体验·7 分钟
Cursor和Windsurf二合一实测:免费额度叠加续杯真的好用吗
实测Cursor与Windsurf二合一整合工具,体验一键切换两大AI编程IDE、免费额度叠加续杯的真实效果。详细分析免魔法直连、适用人群与账号安全风险,帮你判断这款编程续杯神器是否值得尝试。
阅读全文 →
 教程攻略
教程攻略·9 分钟
Ollama+OpenCode本地部署AI编程:零成本替代Cursor的完整方案
详细教程:通过Ollama本地部署千问3 Coder大模型,配合OpenCode开源编程工具,实现零成本AI编程。涵盖环境搭建、代码生成、自动调试全流程,附硬件配置建议。
阅读全文 →
 产品体验
产品体验·11 分钟
Claude 4.5 Sonnet实测:一条指令构建完整AI视觉应用
实测Anthropic最新Claude Sonnet 4.5编码能力,通过构建YOLO目标检测和Streamlit Web应用,验证其智能体编码实力。附基准测试对比、Claude Code工具链解析及开发者工作流建议。
阅读全文 →
 产品体验
产品体验·9 分钟
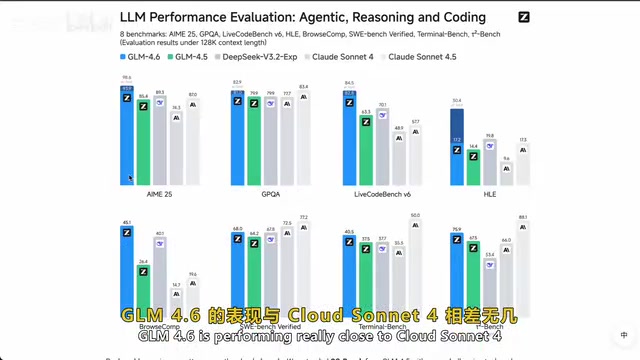
GLM-4.6深度实测:性能、价格与编程能力全面评估
深度实测智谱AI开源模型GLM-4.6,从MoE架构、编程实战、价格对比到适用场景全面解析。输入价格仅$0.06/百万Token,比Claude便宜7-20倍,一次生成代码无需调试,帮你判断是否值得纳入技术栈。
阅读全文 →
 科技前沿
科技前沿·6 分钟
DeepSeek V3.2发布:自研稀疏注意力DSA+API降价50%全解析
DeepSeek发布V3.2-Exp实验版模型,首次引入自研DeepSeek Sparse Attention(DSA)稀疏注意力技术,大幅提升长上下文训练与推理效率,同时API价格下调超50%。本文详解DSA技术原理、模型架构演进及商业策略。
阅读全文 →