Gemini 3.1 Pro vs Claude Opus 4.6:五项实测谁更强
Gemini 3.1 Pro实测与Claude Opus 4.6大致持平,推理进步显著但创意任务略逊。
通过SVG生成、交互组件、网站构建和复杂推理等五项实测,Gemini 3.1 Pro在推理能力上实现质的飞跃,达到与Claude Opus 4.6同等水平,但在创意类任务中仍略逊一筹。考虑到其价格不到Opus一半且拥有百万Token上下文窗口,建议采用"模型路由"分层策略:日常任务用Gemini,复杂场景用Opus,兼顾质量与成本。
文章正文
Google 刚刚发布了 Gemini 3.1 Pro,官方声称在大多数基准测试中大幅超越 Claude,且价格仅为后者的一半。但基准测试和实际表现往往是两回事。
值得注意的是,AI基准测试(Benchmark)本身存在固有局限——常见的MMLU、HumanEval、MATH等标准测试集,可能因为"基准污染"(Benchmark Contamination)问题而导致成绩虚高,即模型在训练阶段已间接接触过测试数据。更重要的是,基准测试针对特定能力设计,无法全面反映模型在真实工作流中的综合表现,这也是为什么本文的实测对比比官方数据更具参考价值。
本文基于一位海外博主的详细实测,从 SVG 图形生成、交互组件、网站构建到复杂推理等五个真实场景,对 Gemini 3.1 Pro 和 Claude Opus 4.6 进行正面对比,看看谁才是当前最强的大模型。
Gemini 3.1 Pro 核心升级了什么
相比前代 Gemini 3 Pro,3.1 版本在几个关键维度实现了显著提升。最核心的变化在于深度推理和复杂问题解决能力的大幅增强,Google 将其描述为"更智能更强大的底层决策能力"。
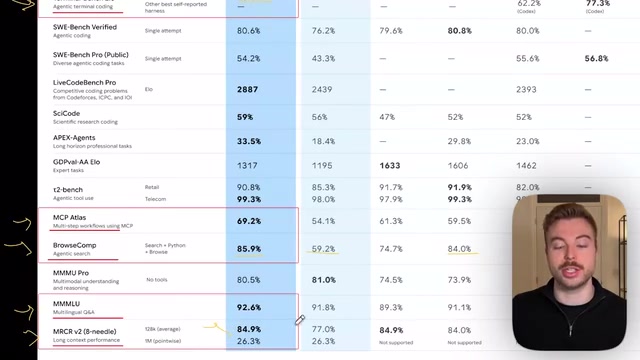
从官方公布的基准数据来看:
- 高级推理:Gemini 3.1 Pro 达到 77%,而 Opus 4.6 为 68%
- 科学知识:Gemini 3.1 Pro 升至 94 分,Opus 4.6 为 91 分
- 代理编码:Gemini 68 分 vs Opus 65 分
- 代理搜索:从 Gemini 3 的 59.2% 飙升至 85%,与 Opus 4.6 基本持平
- 长上下文推理:达到 Opus 4.6 同等水平,且拥有独家的百万 Token 上下文窗口
另一个值得关注的更新是思考级别功能的细化。思考级别本质上是对模型"链式思维"(Chain-of-Thought)深度的动态控制——在推理时,模型会生成中间思考步骤,这些步骤消耗大量Token和计算资源。Gemini 3 只有低和高两档,而 3.1 Pro 新增了中档选项,用户可以根据任务复杂度灵活调节推理深度:简单任务用低档节省成本,复杂推理用高档保证准确性。这种设计理念与 Anthropic 的"Extended Thinking"模式异曲同工,代表了大模型在推理效率上的重要演进方向。
此外,Gemini 3.1 Pro 的定价不到 Opus 的一半,这对企业用户来说是一个非常有吸引力的成本优势。大模型 API 通常按 Token 计费,以每月处理 1 亿 Token 为例,两者的价格差异可能高达数万美元,这也是为什么"分层使用策略"在企业场景中越来越受到重视。
实测一:动态 SVG 图形生成
第一项测试要求模型生成一个复杂的动态 SVG 场景:一个孤独的身影在黄昏时走过荒原,包含雾气效果、远处起伏的山丘、地平线上阴森的庄园、灯笼摇曳的光芒、柔和的云层移动等多个细节元素。
SVG(可缩放矢量图形)是一种基于 XML 的图形格式,通过数学描述而非像素来定义图形。让大模型生成复杂 SVG 的难点在于:模型需要将自然语言描述转化为精确的坐标、路径、动画参数等代码,同时还要在"脑海中"预见最终渲染效果。这要求模型具备空间推理、代码生成和创意理解三重能力的协同,是测试模型综合能力的绝佳场景。
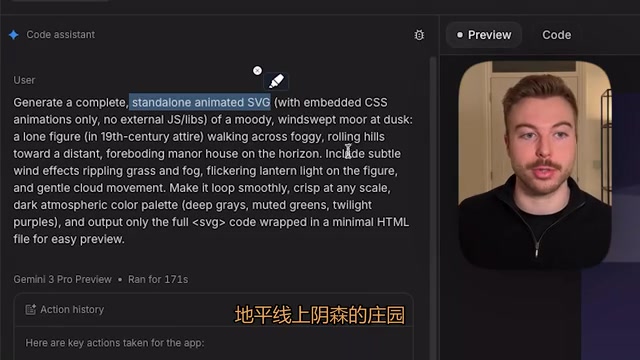
Gemini 3 的表现相当简陋——包含了大部分信息但没有放入人物,房子还奇怪地漂浮着,评测者给出大约五分的评价。Gemini 3.1 Pro 的质量与前代差不多,灯笼有闪耀效果但整体未达预期。
而 Claude Opus 4.6 的表现明显更优:背景有月亮和星星,人物出现在画面中,雾气效果更明显,庄园更像庄园且看起来坐落在山上,草地有动态效果。虽然排版仍有瑕疵,但整体完成度远超两个 Gemini 版本。
这项测试的关键在于需要模型真正理解大量描述信息,分解各部分含义并整合呈现——Opus 4.6 在这种"理解+创作"的综合任务中展现了更强的能力。
实测二:交互式开关组件
第二项测试要求模型创建一个可切换的动态 SVG 开关,以极简 UI 风格流畅展示明暗模式切换。
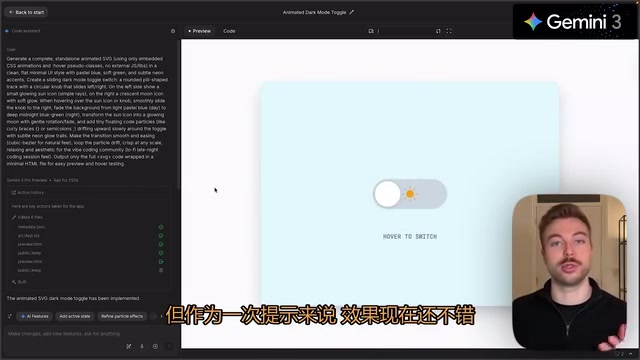
Gemini 3 的开关功能正常,亮色模式位置合理,代码元素都能显示,但在处理亮色模式时略显吃力。Gemini 3.1 Pro 则出现了一个尴尬的状况——可能因为大量用户同时测试,模型尝试运行了 30 分钟都没给出预览,最终评测者只能手动复制代码到 CodePen 测试。切换效果确实比前代更好,但月亮没有居中,仍有改进空间。
Opus 4.6 在白天效果上反而是三者中最差的,需要关闭开关才能看到太阳。但评测者特别喜欢它生成的小星星元素和编程界面元素,整体评价略优于 Gemini 3.1 Pro 但不如 Gemini 3。
这项测试暴露了 Gemini 3.1 Pro 在刚上线时的响应速度问题,这在实际工作流中是一个不可忽视的体验短板。新模型上线初期因服务器承压导致响应延迟,是大模型行业的常见现象,通常会随着基础设施扩容而逐步改善。
实测三:网站页面构建
第三项测试使用同一提示词生成一个 F1 车手的职业高光网站页面。
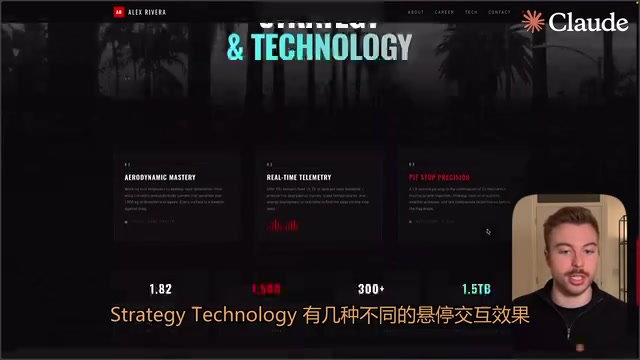
Gemini 3 和 3.1 Pro 的表现非常相似,整体效果不错,展示了相似的图片和要点,评测者没有注意到两者之间有什么重大差异。Gemini 3 在网站生成方面一直表现稳定,新版本在这个维度上没有带来明显突破。
Opus 4.6 则被评为三者中最好的——它使用了 Pexels 的图片作为背景,文字上有光晕效果营造高级感,页面中包含汽车背景、Strategy/Technology 等模块,还有多种悬停交互效果。在网页 UI 设计的审美和细节处理上,Opus 4.6 展现了明显的优势。
实测四:复杂推理能力
最后一项测试直击 Gemini 3.1 Pro 最大的卖点——高级推理能力。测试要求模型分析一个 3×3 网格(用 R/B/G/Y 和空格表示不同颜色),推断隐藏的变换规则,逐步解释推理过程,然后应用规则生成正确输出。
这类抽象规则推断任务,本质上考验的是模型的归纳推理(Inductive Reasoning)能力——从有限的样本中提炼出普适规律,再将其应用于新情境。这与传统的知识检索型问答有本质区别,更能反映模型真正的"智能"水平。
这项测试的结果最能体现代际差异:
- Gemini 3:答错了,未能推断出正确的变换规则
- Gemini 3.1 Pro:答对了,成功推理并生成正确输出
- Claude Opus 4.6:同样答对
这是 Gemini 3 到 3.1 Pro 之间最明显的"飞跃"。在高级推理和复杂问题解决方面,3.1 Pro 确实达到了与 Opus 4.6 同等的水平,验证了 Google 在基准测试中展示的进步。
综合评价与分层使用建议
综合五项实测来看,Gemini 3.1 Pro 确实取得了显著进步,但整体表现与 Opus 4.6 大致持平或略逊一筹。具体来说:
| 测试项目 | 胜出者 |
|---|---|
| SVG 图形生成 | Claude Opus 4.6 |
| 交互组件 | Gemini 3(Opus 4.6 次之) |
| 网站构建 | Claude Opus 4.6 |
| 复杂推理 | 平手(Gemini 3.1 Pro ≈ Opus 4.6) |
从实用角度看,评测者给出了一个务实的使用策略:将 Gemini 3.1 Pro 作为性价比更高的后台模型运行日常任务,把 Opus 4.6 留给更复杂的场景。这种"模型路由"(Model Routing)的工程实践正在企业中逐渐普及——根据任务复杂度自动选择不同价位的模型,将高成本模型的调用比例控制在合理范围内,从而在保证质量的同时大幅降低整体 API 支出。考虑到 Gemini 3.1 Pro 不到 Opus 一半的价格,这种分层使用策略在企业场景中非常有意义。
说个细节,Gemini 3.1 Pro 目前仍处于早期推出阶段,响应速度较慢的问题可能会随着服务器扩容而改善。而百万 Token 的上下文窗口是另一个不可忽视的差异化优势——1M Token 约等于 75 万个英文单词,相当于《哈利·波特》全集的篇幅。这意味着可以一次性分析整个代码库、完整的法律合同集或大型研究报告,无需分段处理导致的信息割裂。在 Notebook LM 等研究场景中的应用潜力,是 Claude 目前无法匹敌的独特优势。
大模型的竞争正在进入白热化阶段,接下来 Opus 5 对阵 Gemini 4 的对决将更加精彩。对于用户而言,最重要的不是选边站队,而是根据具体任务特点选择最合适的工具。
核心要点
- Gemini 3.1 Pro 在高级推理(77% vs 68%)、科学知识(94 vs 91)等基准测试中超越 Opus 4.6,且价格不到后者一半
- 在 SVG 图形生成和网站构建等创意任务中,Claude Opus 4.6 仍然表现更优,展现出更强的空间推理与创意整合能力
- 复杂推理测试中 Gemini 3.1 Pro 实现了从 3.0 到 3.1 的质的飞跃,归纳推理能力达到与 Opus 4.6 同等水平
- Gemini 3.1 Pro 新增三档思考级别和百万 Token 上下文窗口(约75万英文单词),在研究分析场景中具有独特优势
- 实际使用建议:采用"模型路由"策略,将 Gemini 3.1 Pro 作为高性价比日常模型,Opus 4.6 留给复杂任务,可在质量与成本间取得最佳平衡
相关推荐
 产品体验
产品体验Qoder vs Cursor实测对比:同样20美金谁更强?
实测对比Qoder和Cursor两款AI IDE,从Agent自主修复能力、人工沟通次数、架构决策等维度评测。Qoder仅需2次沟通完成任务,Cursor需8次。详细分析两者差异,帮你选择最适合的AI编程工具。
 产品体验
产品体验Cursor云Agent演示:打通软件开发全链路瓶颈
深度解析Cursor云Agent最新Demo,展示如何通过云端虚拟机、自动测试产物和全链路控制平面,系统性消除软件开发生命周期中的人类瓶颈,让Agent自主运行、人按需介入。
 产品体验
产品体验Cursor 3.0深度解析:多Agent并行、Design Mode与Best-of-N模型对比
Cursor 3.0正式发布,从AI辅助编程工具进化为Agent舰队指挥中心。本文详解多智能体并行、Design Mode可视化编辑、Best-of-N多模型择优等核心功能,解读AI编程新范式。