#大模型评测
共 14 篇相关文章
 产品体验
产品体验·8 分钟
WhichLLM:一键检测你的电脑最适合跑哪个本地大模型
WhichLLM 是一款开源工具,能自动检测电脑硬件配置,结合权威评测数据推荐最适合本地运行的大语言模型。支持模拟任意显卡配置、过滤虚假评测、一键下载开聊,帮你告别选模型的纠结。
阅读全文 →
 产品体验
产品体验·5 分钟
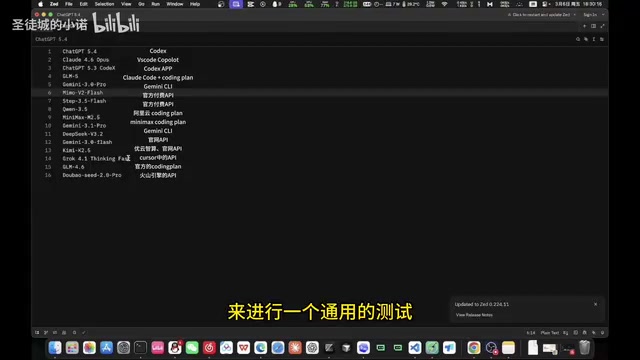
实测15款大模型开发B站首页:GPT登顶,国产模型差距明显
用同一套提示词让15款主流大模型一次性开发B站视频平台应用,实测ChatGPT、Claude、Gemini及国产模型的真实编程能力。详细对比前后端表现、指令遵循度与架构设计,附分层使用策略推荐。
阅读全文 →
 产品体验
产品体验·8 分钟
Cursor 2.0深度解析:自研模型、多Agent并行等五大新功能实测
深度解析Cursor 2.0五大重磅更新:自研Composer模型极速响应、Git Worktrees多Agent并行开发、Agent View模式、内置浏览器等,从实测角度评估这款AI编程IDE的真实实力与局限。
阅读全文 →
 产品体验
产品体验·9 分钟
Cursor 2.0 深度解析:自研模型Composer与五大核心功能全面升级
深度解析Cursor 2.0五大新功能:自研模型Composer速度大幅提升、Git Worktree多Agent并行开发、Agent View模式、内置浏览器等,附实测对比与客观评价。
阅读全文 →
 前沿研究
前沿研究·7 分钟
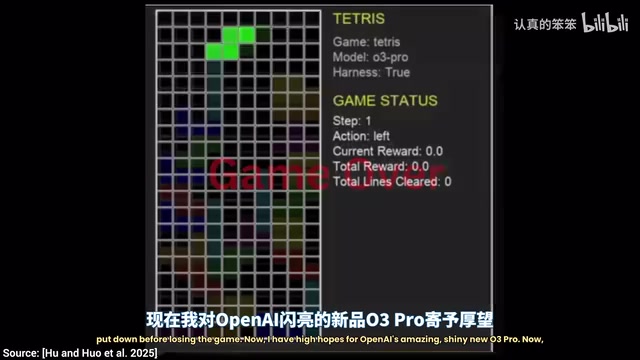
AI玩游戏实力大比拼:O3 Pro展现惊人规划能力
研究者用俄罗斯方块、超级马里奥、推箱子等经典游戏测试各大AI模型,O3 Pro展现出前所未有的规划能力,成为唯一通关全部关卡的模型。游戏测试揭示AI正从模式匹配向真正的战略思维演进。
阅读全文 →
 科技前沿
科技前沿·7 分钟
千问上线400+新功能,文心5.0与多款大模型集中发布
阿里千问APP一次性上线超400项新功能并接入支付宝淘宝等生态,百度文心ERNIE 5.0发布新版本,美团推出深度思考模型,阶跃星辰语音模型登顶全球第一,Anthropic市场份额逼近谷歌。
阅读全文 →
 科技前沿
科技前沿·5 分钟
Gemini 3.1 Pro深度横评:ARC-AGI-2得分77.1%,真的最强吗?
Google Gemini 3.1 Pro发布,ARC-AGI-2抽象推理得分77.1%断档领先,GPQA Diamond 94.3%、编程ELO 2887多项登顶。本文从推理、编程、搜索等维度横向对比o4和GPT-5.2,揭示其真实实力与短板。
阅读全文 →
 产品体验
产品体验·6 分钟
Gemini 3.5 Flash实测对比Qwen3.6:排行榜高分与真实体验差多远?
深度实测Gemini 3.5 Flash在UI生成、编程、Agent能力等维度的真实表现,与Qwen3.6-27B横向对比,揭示大模型排行榜分数与实际体验之间的落差,帮你理性选择AI模型。
阅读全文 →
 产品体验
产品体验·6 分钟
GPT-4 Thinking深度评测:编程、Agent与写作能力实测对比
深度评测GPT-4 Thinking模型在编程修Bug、AI Agent行业研究、学术论文写作等场景的实际表现,对比Gemini和Claude,解析其深度推理与结构化输出能力的核心优势。
阅读全文 →
 科技前沿
科技前沿·5 分钟
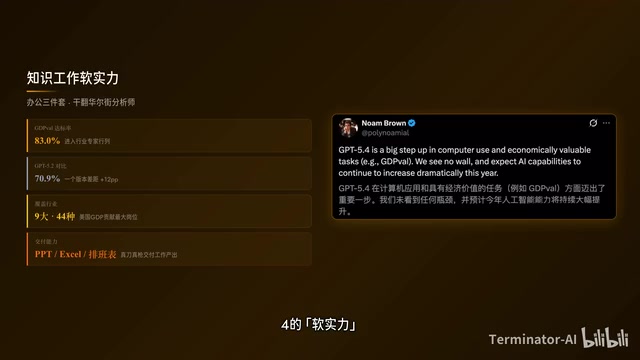
GPT-5.4深度评测:原生计算机使用、推理编程合体,OpenAI重回王座
GPT-5.4全面评测:OSWorld超越Claude Opus 4.6,原生计算机使用能力炸裂,推理编程合体Token效率提升50%,幻觉率暴降33%,搜索能力刷新纪录。OpenAI首个全能通用模型深度解析。
阅读全文 →
 科技前沿
科技前沿·4 分钟
Claude Opus 4.5工程测试碾压人类:AI编程能力全面超越顶尖工程师
Anthropic最新发布的Claude Opus 4.5在内部两小时工程考试中击败所有人类候选人,SWE-Bench得分创历史新高。深度解析Opus 4.5的基准测试表现、创造性问题解决能力、安全对齐突破及企业级应用场景。
阅读全文 →
 产品体验
产品体验·10 分钟
GPT-5.2、Claude 4.5、Gemini 3 Pro实测对比:2025选购指南
2025年实测对比GPT-5.2、Claude Sonnet 4.5、Gemini 3 Pro、Grok 4.1四大AI模型,覆盖图像生成、深度研究、写作推理等核心场景,附各模型优劣势总结与低成本体验方案。
阅读全文 →
 产品体验
产品体验·8 分钟
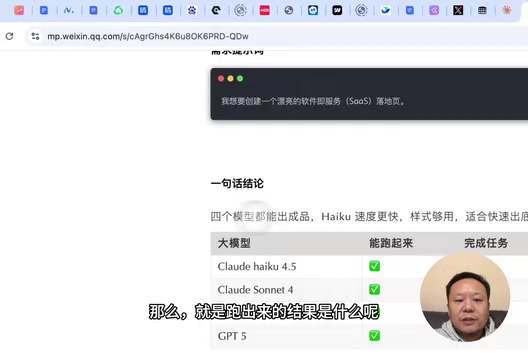
Claude Haiku 4.5前端实测:三分之一价格吊打GPT-5?
实测对比Claude Haiku 4.5、Sonnet 4.0、Gemini 2.5 Pro和GPT-5在SaaS落地页、3D魔方、天气动效三个前端场景的表现。Haiku 4.5仅三分之一价格,多数场景接近甚至超越旗舰模型。
阅读全文 →
 产品体验
产品体验·9 分钟
GPT 5.5 vs DeepSeek V4 实测对比:逻辑推理、前端生成、3D场景谁更强?
通过逻辑推理、前端页面生成、3D场景动画三项实战任务,深度对比GPT 5.5与DeepSeek V4的真实表现。涵盖生成速度、代码质量、视觉效果及性价比分析,帮你选出最适合的AI编程模型。
阅读全文 →