AI玩游戏实力大比拼:O3 Pro展现惊人规划能力
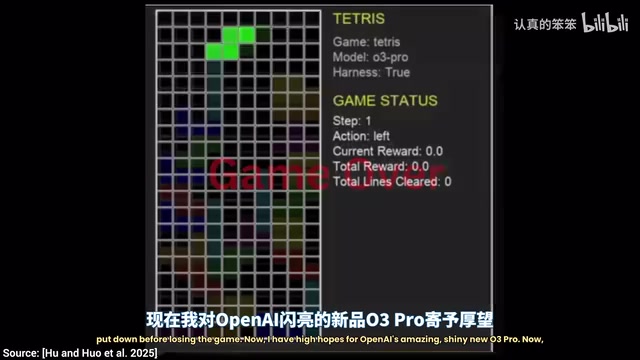
O3 Pro在经典游戏测试中展现出AI前所未有的规划能力
研究者通过文本化游戏框架让各大AI模型玩俄罗斯方块、超级马里奥和推箱子等经典游戏。大多数模型表现挣扎,而OpenAI O3 Pro凭借"测试时计算扩展"架构展现出碾压级的规划能力。研究揭示三大发现:AI正涌现真正的规划思维,游戏比传统基准更能评估AI真实能力,且跨游戏的知识迁移已初现端倪。
当AI遇上经典游戏:一场别开生面的智能测试
我们习惯了用学术基准测试来衡量AI的能力——数学推理、代码生成、文本理解。但如果让这些号称"博士级"的AI去玩俄罗斯方块、超级马里奥或者推箱子,它们的表现会如何?
最近,研究者们搭建了一套文本化的游戏测试框架(harness),将游戏状态转化为文字描述输入给各大AI模型,然后让它们决策下一步操作。这种框架本质上是一种将视觉/交互式游戏状态序列化为结构化文本的中间层技术——由于大语言模型处理的是token序列而非像素,研究者需要将游戏的二维网格、实体位置、当前分数等状态信息编码为自然语言或符号化描述(如用字符矩阵表示俄罗斯方块棋盘),再将模型输出的文字指令解析回游戏引擎可执行的操作。这种方法无需专门训练视觉模型,但也引入了信息损耗——模型只能依赖符号化的状态描述进行推理,而无法感知动画帧率等视觉线索。
结果令人大开眼界:大多数AI在游戏中表现挣扎,但OpenAI的O3 Pro展现出了前所未有的规划能力。
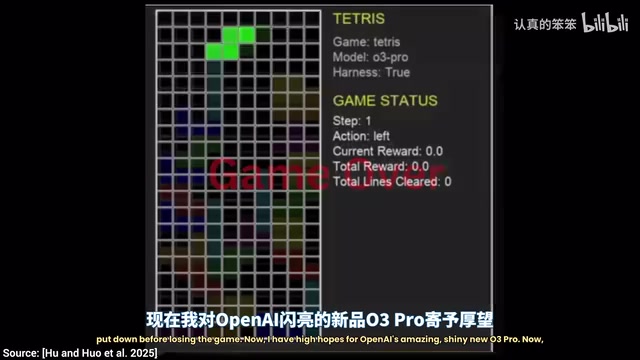
俄罗斯方块:从一片混乱到完美消行
大多数AI的惨淡表现
首先登场的是Llama 4。虽然它在传统基准测试上表现不错,但面对俄罗斯方块却手足无措。之前的模型留下大量空隙,几乎无法形成完整的行,最终迅速崩溃。
OpenAI的O4 Mini稍有改善,坚持的时间更长,但依然没能消除一行。DeepSeek R1开局不错,甚至成功消除了一行,但随后局面迅速失控。Claude 4 Opus的表现也类似——这些AI似乎只是在比赛谁能"晚一点输",而非真正赢得游戏。
值得注意的是,这些模型的失败并非偶然。当前主流AI基准测试如MMLU、HumanEval和GSM8K存在一个共同缺陷:它们本质上是静态的单轮问答,无法评估模型在动态环境中的连续决策能力。更严重的问题是"基准污染"(Benchmark Contamination)——由于测试题目大量出现在互联网上,模型在预训练时可能已经"见过"答案,导致高分并不代表真实的泛化推理能力。俄罗斯方块的实时动态状态恰恰暴露了这一短板。
O3 Pro的惊艳表现
O3 Pro的开局看起来有些奇怪,但如果耐心观看,你会发现它在一行接一行地消除。更关键的是,它似乎是第一个真正在"提前规划"的模型——不是简单地放下当前方块,而是为后续的方块预留空间。
O3 Pro之所以能做到这一点,与其底层架构密切相关。它属于OpenAI的"o系列"推理模型,核心特征是在生成最终答案前会执行大量内部"思维链"(Chain-of-Thought)推理步骤。这种架构被称为测试时计算扩展(Test-Time Compute Scaling),即通过在推理阶段投入更多算力来提升答案质量,类似于人类棋手在落子前的深度思考,而非直觉反应。这也正是O3 Pro决策速度极慢的根本原因——它在每一步操作前都在内部模拟和评估多种可能的未来状态。在整个实验期间,O3 Pro没有失败,这在所有测试模型中独一无二。
超级马里奥:从跳崖到通关的进化之路
GPT-4o在超级马里奥中的表现可以用"灾难"来形容。Claude 3.5看起来稍微聪明一些,甚至找到了隐藏方块,但随后莫名其妙地跳入深渊。
Claude 3.7明显更好:踩扁栗子、勇敢跳过坑洞、发现无敌星并冲向它。它几乎要到达终点线了——然后灾难降临。重试时,它一路顺风即将通关,却在最简单的地方失误。研究者感叹:"这是第一次看AI玩游戏像看人类玩一样——完成了神级操作,却在最简单的事情上翻车。"

最终结果显示,O3系列在超级马里奥、推箱子和糖果粉碎中全面领先,且往往是碾压级的优势。
推箱子(Sokoban):规划能力的终极考验
为什么推箱子是AI规划能力的试金石
推箱子是一个经典的逻辑游戏:将箱子推到指定位置。看似简单,但它在计算复杂性理论中被证明是PSPACE完全问题,意味着其求解难度随关卡规模呈指数级增长,即使对经典算法也极具挑战性。在AI研究领域,推箱子长期被用作测试启发式搜索、约束满足和强化学习算法的标准环境。它的核心挑战在于"不可逆操作"——箱子一旦推入死角便无法取出,要求规划者必须在行动前模拟多步未来状态,这与国际象棋的前瞻搜索类似,但状态空间更加稀疏且陷阱更隐蔽。正因如此,推箱子成为区分"模式匹配"与"真正规划"能力的理想试金石。
Gemini 2.5 Flash成功完成了第一关,但在第二关陷入了经典陷阱:它把第一个箱子推到了错误的位置,导致第二个箱子无法就位。
O3的战略思维
O3在面对同样的第二关时,展现了真正的规划能力:它意识到如果先把箱子推到某个标记上,就无法再把第二个箱子推进去。于是它选择了正确的顺序,关卡几乎自动解开。不过,O3在第四关之后也停滞了。
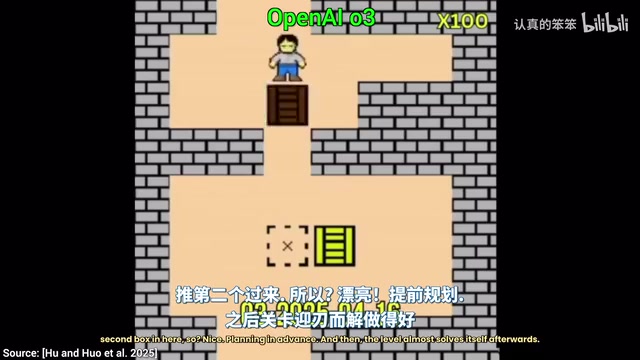
而O3 Pro则更进一步——它成功完成了全部六个关卡。虽然每一步的决策时间极长(视频中的演示是加速播放的),但它展现出的系统性规划能力令人印象深刻。
三个关键发现:AI游戏测试揭示的深层趋势

发现一:真正的规划能力正在涌现
也许是历史上第一次,我们开始在大语言模型中看到真正的规划和战略思维。虽然速度很慢,但这种能力的出现本身就是一个里程碑。AI不再只是模式匹配,而是开始"思考"未来的状态。这背后的技术驱动力正是测试时计算扩展架构——通过允许模型在推理阶段"慢下来思考",换取更高质量的决策输出。
发现二:游戏是更好的AI评测工具
传统基准测试无法告诉我们全部故事。游戏测试框架提供了一个动态、有状态、需要长期规划的评估环境,每一局游戏都是独特的序列,难以通过记忆作弊,因此能更真实地反映模型的推理深度和适应能力。游戏作为一个极其丰富且具有挑战性的测试平台,要求长期规划和动态适应——这是少数其他基准测试能够考察的能力。通过游戏,我们能更深入地理解AI的优势和弱点。
发现三:跨游戏的知识迁移
这是最令人兴奋的发现:在推箱子上训练后的AI,其空间推理能力得到提升,在俄罗斯方块中的表现提高了最多8%。这一现象与机器学习中的迁移学习(Transfer Learning)和领域泛化(Domain Generalization)理论密切相关。推箱子到俄罗斯方块的迁移之所以有效,可能是因为两者都涉及二维空间中的物体位置推理和多步规划。更深层的解释是,大语言模型在预训练阶段已经从海量文本中习得了抽象的空间关系表征,游戏训练只是激活并强化了这些潜在能力。这一发现呼应了"通用智能"(AGI)研究中的核心假设:真正的智能应能将在一个领域习得的抽象规则迁移到结构相似的新领域,而无需从零开始学习。一个在完全不同的游戏中学到的知识,竟然能迁移到另一个游戏中——这或许是某种通用智能的萌芽,从硅基材料中涌现出的智慧。
总结与展望
这项研究揭示了一个重要趋势:AI的能力正在从"记忆和匹配"向"规划和推理"演进。O3 Pro虽然决策速度极慢,但它展现出的前瞻性思维和跨领域迁移能力,暗示着大模型正在发展出某种更深层的认知结构。
当然,目前的AI在游戏中的表现距离人类玩家仍有差距——尤其是在速度和灵活应变方面。但考虑到这些模型并非专门为游戏设计,它们展现出的通用规划能力已经足够令人惊叹。游戏测试或许将成为未来评估AI真实智能水平的重要补充工具。
核心要点
- OpenAI O3 Pro在俄罗斯方块、超级马里奥和推箱子等游戏中展现出碾压其他AI的规划能力
- 游戏测试比传统基准测试更能揭示AI的真实推理和规划能力,有效规避了"基准污染"问题
- AI在推箱子训练后空间推理能力提升,俄罗斯方块表现提高最多8%,展现跨领域知识迁移
- 大多数主流AI(Llama 4、DeepSeek R1、Claude等)在游戏中表现挣扎,仅能比拼谁输得更晚
- 研究者通过文本化游戏框架(harness)让大语言模型能够参与游戏决策
- O3 Pro的慢速决策源于其"测试时计算扩展"架构,通过内部思维链推理换取更高质量的规划输出
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。