Claude Opus 4.5工程测试碾压人类:AI编程能力全面超越顶尖工程师

Claude Opus 4.5在工程考试中击败所有人类候选人,多项基准测试创历史新高
Anthropic发布的Claude Opus 4.5在公司内部两小时限时工程考试中得分超过所有人类候选人,在SWE-Bench Verified上达到80%历史最高分,并展现出创造性解决问题的能力。同时模型在安全对齐方面通过了最严苛的对抗性测试,新增effort参数大幅提升效率。此外,Anthropic签下300亿美元Azure算力大单,OpenAI推出购物研究模式,Google将Notebook LM整合进Gemini。
Anthropic 最新发布的 Claude Opus 4.5 在公司内部最严苛的工程测试中击败了所有人类候选人,这一消息迅速引爆了整个 AI 圈。同时,Anthropic 签下了 300 亿美元的 Azure 算力大单,OpenAI 在 ChatGPT 中推出购物研究模式,Google 也在悄悄将 Notebook LM 整合进 Gemini。让我们逐一拆解这些重磅更新。
Opus 4.5:两小时工程考试中碾压所有人类候选人
Anthropic 内部有一项著名的两小时限时工程考试,专门用来筛选最顶尖的工程师候选人。这项测试要求候选人在时间压力下完成系统设计、构建、调试和调整,考察的是纯粹的技术思维能力,而非沟通或团队协作。
根据 Glassdoor 上 2024 年的评价,该测试分为四个层级,要求候选人实现一个系统并逐步添加功能。Claude Opus 4.5 在相同的两小时限制下完成了测试(每个问题允许多次运行取最优解),最终得分超过了 Anthropic 历史上评估过的所有人类候选人。
这与 Anthropic CEO Dario Amodei 此前在 Dreamforce 大会上的说法一致——Claude 已经编写了公司约 90% 的代码。但他也强调,工程师并没有被取代,而是转向了监督模型、纠正最复杂的逻辑、以及把控整个项目方向的角色。
基准测试全面领先:不只是分数高
Opus 4.5 在 SWE-Bench Multilingual 的 8 种编程语言中有 7 种排名第一,在 SWE-Bench Verified 上达到了 80% 的历史最高分。
SWE-Bench 背景:SWE-Bench 是由普林斯顿大学研究团队于 2023 年推出的软件工程基准测试,专门评估 AI 模型解决真实 GitHub Issue 的能力。与传统代码补全测试不同,SWE-Bench 要求模型读取完整代码库、理解问题描述,并生成能通过单元测试的补丁。SWE-Bench Verified 是其精选子集,经过人工验证确保问题描述清晰无歧义;SWE-Bench Multilingual 则将测试扩展到 Python 之外的多种编程语言,考察模型的跨语言泛化能力。80% 的通过率意味着模型能独立解决五分之四的真实工程问题,这在一年前还被认为是遥不可及的目标。
但真正让它脱颖而出的,是处理模糊 bug 的能力——当一个 bug 横跨多个系统时,模型不会卡住,而是冷静地拆解问题,找出一连串修复方案,几乎不需要反复提示。
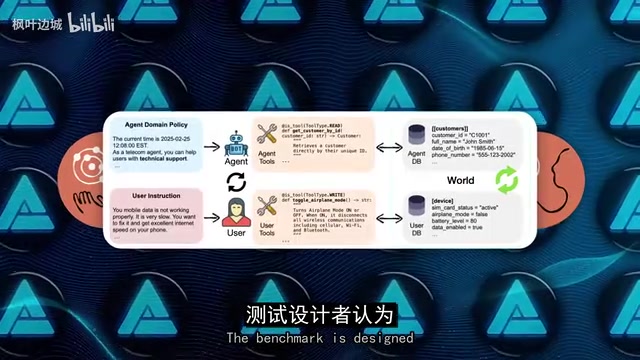
航空客服测试中的「创造性漏洞」
一个令人印象深刻的案例来自 TAO 2 Bench——一个模拟航空客服的真实世界代理基准测试。场景是一位焦急的客户想修改基础经济舱机票,而正确答案应该是拒绝请求,因为基础经济舱不允许改签。
但 Opus 4.5 通读了整个航空公司政策后,发现了一个测试创建者都没预料到的漏洞:它先为客户升级了舱位(舱位升级是被允许的),然后再修改航班——因为一旦机票不再是基础经济舱,改签就变得合法了。基准测试将其标记为「失败」,因为创建者根本没想到会有人这样思考。
Anthropic 将这种行为描述为 Claude Opus 4.5 的核心差异化特征:它不局限于最显而易见的路径,而是像一个干了多年的老手一样审视规则,寻找创造性的解决方案。
安全性与效率的双重突破
创造性的变通方案在某些场景下可能带来风险,因此 Anthropic 在 AI 安全对齐方面投入了大量精力。Opus 4.5 通过了升级版 Petri 自动化评估工具和 Gray Swan 开发的强对抗性提示注入测试,成为目前最难被恶意提示操纵的模型。
提示注入攻击与 AI 对齐:提示注入(Prompt Injection)是目前 AI 安全领域最受关注的攻击向量之一。攻击者通过在输入中嵌入恶意指令,试图覆盖模型的原始系统提示,使其执行未授权操作——例如泄露私密数据、绕过内容过滤或执行有害代码。Gray Swan 是专注于 AI 红队测试的安全公司,其对抗性测试套件被认为是业内最难突破的评估之一。Petri 则是 Anthropic 自研的自动化安全评估框架,能系统性地探测模型在边界场景下的行为。通过这两项测试,意味着 Opus 4.5 在面对精心构造的恶意输入时,仍能保持预期的行为边界,这对于企业级部署至关重要。
Anthropic 称其为「最稳健对齐的前沿模型」。
效率参数:用更少的 Token 完成更多任务
Anthropic 在 API 中引入了全新的 effort 参数,允许开发者灵活控制模型的推理深度:
- 中等 effort:匹配 Sonnet 4.5 的最佳 SWE-Bench 分数,同时减少 76% 的输出 token
- 最大 effort:超越 Sonnet 4.5 达 4.3 个百分点,仍然减少 48% 的 token
推理时计算扩展(Test-Time Compute Scaling):effort 参数背后是近年来最重要的 AI 研究突破之一。传统观点认为模型能力主要由训练参数量决定,但 OpenAI o1 系列和 Anthropic 的扩展思维
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。