GPT-5.4深度评测:原生计算机使用、推理编程合体,OpenAI重回王座
OpenAI发布GPT-5.4,首个具备原生计算机使用能力的全能通用模型
OpenAI发布GPT-5.4,这是其首个集推理、编程、视觉、计算机操作等能力于一身的通用模型。在计算机使用能力上以75.0%超越Claude Opus 4.6,在知识工作评测GDPVL中以83.0%追平专业人士水平,编程能力继承并超越GPT-5.3-Codex,同时幻觉率降低33%,标志着AI从提效工具升级为可独立交付的工作单元。
首个全能通用模型降临
OpenAI深夜放出重磅炸弹——GPT-5.4正式发布。这不是一次简单的版本迭代,而是OpenAI对Gemini 3.1 Pro和Claude Opus 4.6的全面反击。GPT-5.4是OpenAI首个具备原生计算机使用能力的通用模型,集推理、编程、视觉、工具使用、计算机操作、网络搜索和知识工作于一身,每一项能力都拉到了当前的顶尖水平。
原生计算机使用:直接超越Claude Opus 4.6
GPT-5.4最令人兴奋的能力是原生计算机使用(Computer Use)。它既能通过Playwright等库编写代码来控制计算机,也能直接读取屏幕截图、操作鼠标和键盘——发邮件、排日程、填表格、跑流程,这些以前需要手动操作的工作,GPT-5.4现在可以独立完成。
技术背景:计算机使用(Computer Use)是指AI模型直接感知屏幕画面并操控鼠标、键盘的能力,本质上是让AI像人类一样"看着屏幕干活"。这一能力的技术路径分为两类:一是通过代码间接控制(如调用Playwright、Selenium等自动化库),二是直接视觉感知+动作输出(截图→理解→点击/输入)。前者依赖结构化DOM,后者更接近人类操作方式但对视觉理解要求极高。OSWorld和WebArena是该领域最权威的评测基准,前者模拟真实桌面操作系统任务,后者聚焦网页交互场景,两者都要求模型完成端到端的多步骤任务,而非单一指令响应。
在核心基准测试中,GPT-5.4的表现相当亮眼:
- OSWorld Verified:75.0%成功率,超越Claude Opus 4.6的72.7%,领先2.3个百分点
- WebArena Verified(DOM+截图驱动):67.3%成功率,领先GPT-5.2的65.4%
- Online Mind2Web:仅靠截图观察力拿下92.8%,而ChatGPT Atlas智能体模式只有70.9%,差距明显
就在一个月前,Claude Opus 4.6才刚登顶计算机使用能力榜单,GPT-5.4一出手就完成了反超。
视觉感知与文档解析:全保真度输入
强大的执行能力离不开更强的通用视觉感知。在MMMU Pro基准上,GPT-5.4不使用工具的成功率达到81.2%,明显优于GPT-5.2的79.5%。在OmniDoc Bench上,GPT-5.4未开启推理强度的平均误差为0.109,GPT-5.2则为0.140。
更值得关注的是,GPT-5.4首次引入"Original"和"High"两种图像输入细节级别:
- Original模式:支持最高1024万总像素或最大单边6000像素的全保真度感知
- High模式:支持最高256万总像素或最大单边2048像素
在API早期测试中,GPT-5.4在定位能力、图像理解和点击准确性上均有明显提升。
精通办公三件套:比华尔街分析师还强
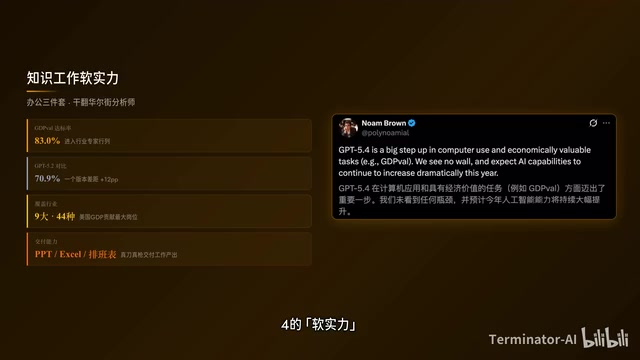
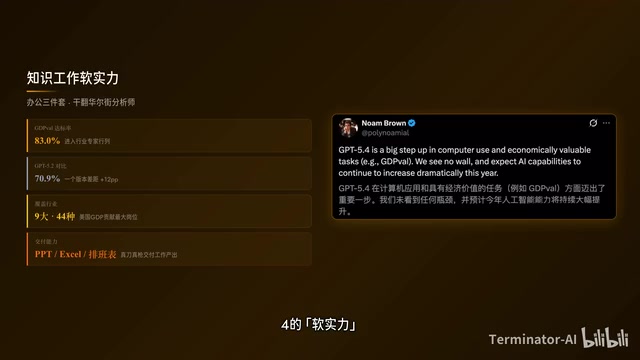
计算机使用是硬功夫,知识工作则是GPT-5.4的软实力。在GDPVL基准测试中,GPT-5.4以83.0%的成绩追平甚至超越了行业内的专业人士,而上一代GPT-5.2仅有70.9%——一个版本直接拉开了12个百分点的差距。
技术背景:GDPVL(GDP-Verified Labor)是一个以美国GDP贡献为权重设计的知识工作评测基准,其核心理念是让AI评测与真实经济价值挂钩,而非仅测试学术题目。基准覆盖美国GDP贡献最大的9个行业和44种职业,要求模型交付可直接使用的工作产出——如可运行的Excel财务模型、可演示的PowerPoint、符合排版规范的医疗表格等。这种"交付物导向"的评测方式比传统选择题或代码题更能反映AI在真实职场中的替代潜力。GPT-5.4以83.0%追平专业人士水平,意味着在初级白领工作场景中,AI辅助已从"提效工具"升级为"可独立交付"的工作单元。
GDPVL测试横跨美国GDP贡献最大的9个行业、44种职业,涵盖销售演示文稿、会计电子表格、急诊排版表、制造图表、短视频等场景,全部要求AI交付真实的工作产出。GPT-5.4已经能做PPT、做Excel、排版表,而且完成质量超过了大多数专业人士。
在一项模拟初级投资银行分析师的内部电子表格建模测试中,GPT-5.4平均得分87.3%,GPT-5.2只有68.4%。人类在68.0%的情况下更偏好GPT-5.4生成的PPT,原因是美感更强、视觉更丰富、图像使用更高效。
幻觉率降低33%
GPT-5.4是OpenAI迄今为止最注重事实准确性的模型。在一组去标识化的、包含用户标记事实错误的提示词集中,相对于GPT-5.2:
- 单独声明出错的概率降低了33%
- 整个回复包含任何错误的概率降低了18%
对于依赖AI生成内容的专业场景来说,这一改进意义重大。
推理+代码合体:Token效率最高的推理模型

GPT-5.4完整继承了GPT-5.3-Codex的编程能力,用户不再需要在"聪明的模型"和"能写代码的模型"之间来回切换,一个模型就能全部搞定。
在SWE-Bench Pro测试中,GPT-5.4拿下57.7%准确率,甚至超越了GPT-5.3-Codex的56.8%。
技术背景:SWE-Bench(Software Engineering Benchmark)是由普林斯顿大学提出的代码能力评测基准,要求模型基于真实GitHub Issue修复实际代码库中的Bug,是目前最接近工程实战的编程评测。SWE-Bench Pro是其升级版,引入了更复杂的多文件修改、跨模块依赖等场景,难度显著高于原版。Token效率在此语境下尤为关键——推理模型在解题时往往需要大量"思考Token
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。