Gemini 3.1 Pro深度横评:ARC-AGI-2得分77.1%,真的最强吗?

Gemini 3.1 Pro在推理和抽象测试中登顶,但并非全面碾压对手
Google发布的Gemini 3.1 Pro在多项核心基准测试中表现亮眼:ARC-AGI-2抽象推理77.1%断档领先,GPQA Diamond推理94.3%超越OpenAI模型,编程ELO达2887,搜索能力BrowseComp 85.9%同样领先。但在SWE-Bench Pro工程级编程任务上略逊于GPT-5.2,专家任务评估也低于Claude,且仍处Preview阶段,尚非全维度最强。
Google 最新发布的 Gemini 3.1 Pro 在 AI 圈掀起了不小的波澜——ARC-AGI-2 抽象推理测试拿下 77.1%,编程 ELO 飙到 2887,多项核心指标直接登顶。这是不是意味着当前最强大语言模型已经换人了?别急下结论,本文从推理、编程、搜索等多个维度做了一轮横向对比,帮你看清全貌。
三大核心升级:推理、编程、上下文
Gemini 3.1 Pro 相较前代在三个方向上有了明显进步:
推理能力大幅跃进。 GPQA Diamond 是公认的高难度推理基准测试——题目来自生物学、化学、物理学等领域的博士级别知识,且经过刻意设计以抵抗搜索引擎检索,即便是领域专家平均正确率也仅在 65% 左右。Diamond 子集更是其中难度最高的题目集合,代表了学术界对模型深度推理能力的顶级考验。Gemini 3.1 Pro 在这项测试中拿到了 94.3%,直接超过了 OpenAI 的 o4(OPAS 4.6)和 GPT-5.2,意味着其在多步推理、跨领域知识整合上已显著超越人类专家平均水平。这个分数相当能打。

编程能力全面提升。 SWE-Bench 得分 80.6%,TerminalBench 达到 68.5%,编程 ELO 评分 2887,在主流编程基准测试中均处于第一梯队。
百万级 Token 上下文 + 全模态输入。 支持超长上下文窗口和多模态输入,处理大型代码库、长文档分析这类实际场景时,实用性有了质的提升。
ARC-AGI-2 抽象推理:断档式领先
ARC-AGI-2(Abstraction and Reasoning Corpus for Artificial General Intelligence)由 AI 安全研究员 François Chollet 主导设计,是 ARC 系列测试的第二代版本。其核心设计理念是:真正的智能不应依赖记忆或统计模式,而应具备从少量样本中归纳抽象规则的能力。测试题目通常呈现为彩色网格图案,要求模型识别隐藏的变换规律并推断输出结果——这类任务对人类来说直觉上并不困难,但对依赖大规模预训练数据的语言模型却极具挑战性。ARC-AGI-2 相比第一代难度大幅提升,加入了更复杂的空间推理和多步逻辑链,被研究界视为衡量模型"真实推理能力"而非"记忆检索能力"的重要风向标。
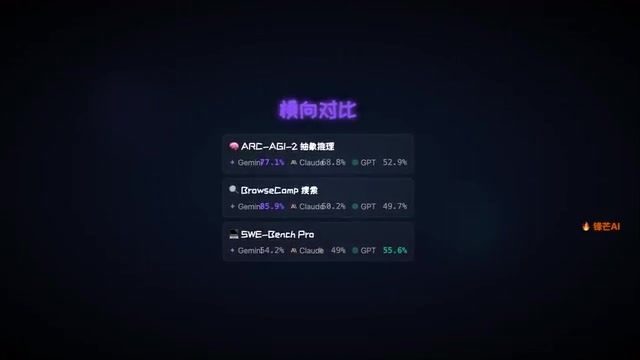
在这项测试中,各家模型的差距一目了然:
| 模型 | ARC-AGI-2 得分 |
|---|---|
| Gemini 3.1 Pro | 77.1% |
| OpenAI o4 | 68.8% |
| GPT-5.2 | 52.9% |

Gemini 3.1 Pro 以 77.1% 大幅领先,比 o4 高出超过 8 个百分点,比 GPT-5.2 更是拉开了 24 个百分点的差距。在模式识别和抽象逻辑推理这个维度上,Google 的新模型确实实现了质的突破。
另一个值得关注的亮点是搜索能力。BrowseComp 是 OpenAI 发布的网页浏览与信息检索能力基准,测试模型在开放网络环境中执行多跳搜索、信息整合和事实核查的综合能力,考察的不仅是单次检索准确性,更包括跨页面推理和信息去噪能力。Gemini 3.1 Pro 在此项测试中拿下 85.9%,同样是断档式领先。这背后离不开 Google 超过 25 年的网页索引、PageRank 算法迭代以及实时搜索基础设施经验——这些工程能力被系统性地融入了 Gemini 的训练数据质量和检索增强架构中,形成了其他厂商短期内难以复制的竞争壁垒。
并非全面碾压:短板同样存在
不过,如果就此给 Gemini 3.1 Pro 贴上"全维度最强"的标签,那就言过其实了。
SWE-Bench Pro 上略逊一筹。 值得注意的是,SWE-Bench 与 SWE-Bench Pro 并非同一难度层级:标准版 SWE-Bench 考察的是相对独立的单文件修复任务,而 Pro 版引入了更复杂的多文件修改、更长的代码依赖链以及更严格的测试验证标准,更贴近真实工程师日常面对的复杂任务。在难度更高的 SWE-Bench Pro 测试中,Gemini 3.1 Pro 得分 54.2%,而 GPT-5.2 拿到了 55.6%。差距虽然不大,但说明面对复杂工程级编程任务时,OpenAI 的模型依然有一定优势,也揭示了 Gemini 3.1 Pro 在"简单编程任务"与"工程级复杂任务"之间存在的能力断层。
Preview 状态带来的不确定性。 Gemini 3.1 Pro 目前仍处于 Preview 阶段,正式版可能还会有调整和优化,当前的跑分数据存在变动空间,不宜过度解读。
专业领域任务仍有差距。 在 GDPo 专家任务评估中,Gemini 3.1 Pro 得分 1317,低于 Anthropic Claude 的同等水平。这意味着在某些需要深度专业知识的垂直场景中,Google 的模型还有提升空间。
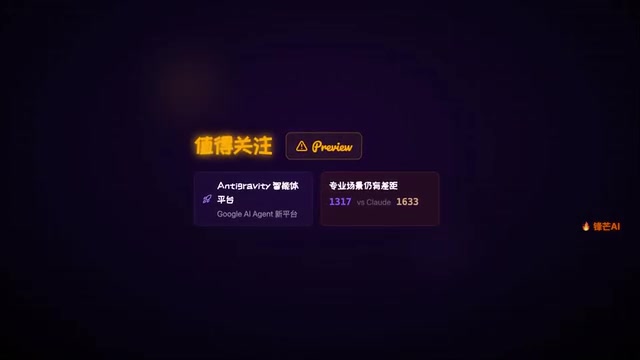
生态布局:Anti-Gravity 智能体平台
除了模型本身的升级,Google 还同步推出了 Anti-Gravity 智能体平台。AI Agent(智能体)是当前大模型落地应用的核心范式之一,指能够自主规划任务、调用工具、执行多步骤操作并根据环境反馈动态调整策略的 AI 系统,与传统"问答式
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。