Duel Agents:多AI代理竞赛机制,自动选出最省钱的编码方案
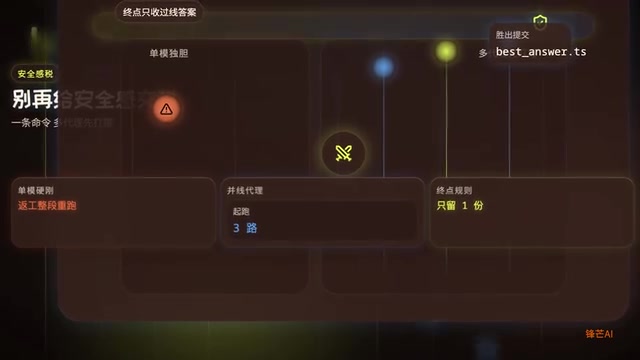
核心思路:不选最强,选最值
如果你还在用一个旗舰模型硬扛所有编码任务,那你可能不是在买效率,而是在为安全感交税。
Duel Agents 提出了一个很直接的思路:同一条命令,同时丢给多个 AI 代理,谁先过线、谁的答案够好就用谁的。这不是在追求单模型最强,而是在追求整体性价比最优。
AI 编程智能体领域真正的痛点,已经不是"AI 能不能写代码",而是每次都开旗舰模型太贵。很多任务其实小模型就能胜任,但开发者不敢赌——因为一旦翻车,返工的成本比省下来的钱更高。Duel Agents 试图用系统化的方式解决这个信任问题。
要理解这个痛点的严重程度,需要看一下当前的成本结构:以Claude Code为例,使用Claude 4 Opus处理一个中等复杂度的编码任务,单次调用成本可能在0.5-2美元之间;而如果使用Claude Haiku,同等token量的成本仅为前者的十分之一左右。OpenAI的GPT-4o与GPT-4o-mini之间也存在类似的价格梯度。对于日均发出数十甚至上百条编码指令的开发团队来说,模型选择直接决定了月度AI开支是数百美元还是数千美元。这就是为什么"智能路由"成为一个真实的工程需求,而非纯粹的学术探讨。

架构设计:路由层 + 质检层 + 递归拆解
不造新 IDE,做"前置路由"
Duel Agents 最聪明的地方在于它的定位:不重新造一个 IDE,而是直接插在 Claude Code、Codex 这类现有工具前面,充当路由层。
具体流程是这样的:
- 用户发出一条编码指令
- Duel Agents 将这条指令同时分发给多个不同级别的 AI 模型
- 多个模型并行执行,各自返回结果
- 质检层对结果进行评估,挑出既便宜又过关的那个答案
这种"竞赛式"的架构,本质上是用并行冗余换取成本优化的确定性。你不需要自己判断"这个任务该用 GPT-4o 还是用 Claude Haiku",系统帮你试完再选。
这一机制在分布式系统领域有一个经典的理论基础——"对冲请求"(Hedged Requests)。Google在其著名的论文《The Tail at Scale》中首次系统性地阐述了这一策略:当你不确定哪条路径最优时,同时发起多条请求,取最先返回的有效结果。这种策略在延迟敏感的系统中被广泛使用,代价是额外的计算资源消耗,收益是更稳定的响应质量和更可预测的完成时间。Duel Agents将这一思路从延迟优化扩展到了成本优化——不只是取最快的,而是取"够好且最便宜"的。
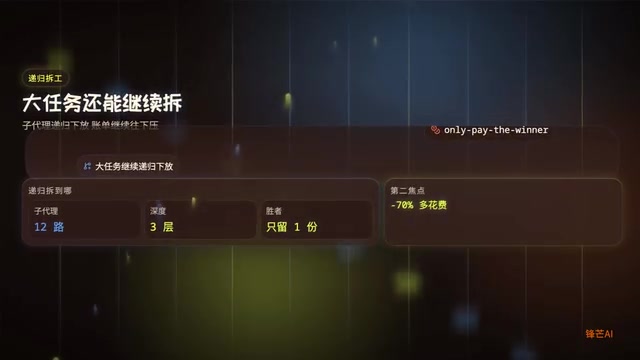
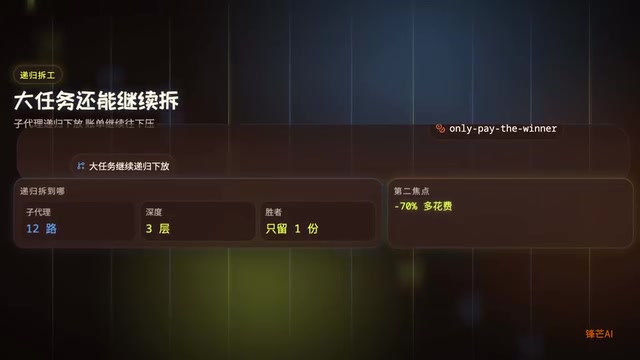
递归式任务拆解
官方还加了一层递归拆解机制:大任务可以被拆成多个子代理任务,子代理再把子任务下放给更便宜的小模型。这形成了一个分层代理编排的架构:
- 顶层:复杂的架构决策、核心逻辑 → 旗舰模型处理
- 中层:模块化的功能实现 → 中等模型处理
- 底层:格式化、简单重构、测试生成 → 廉价小模型处理
这种思路和软件工程中的"关注点分离"异曲同工——不是所有代码都值得用最贵的模型来写。
递归式任务拆解的思路并非Duel Agents首创,它源自多智能体系统(Multi-Agent Systems)领域的经典范式。微软的AutoGen、CrewAI、LangGraph等框架都在探索类似的分层代理架构。核心挑战在于"任务分解的粒度控制"——拆得太粗,小模型依然无法胜任;拆得太细,子任务之间的上下文依赖会导致信息丢失,最终拼装出的代码缺乏一致性。业界目前的共识是,函数级别的拆解通常是一个较好的平衡点:每个子任务对应一个独立函数的实现,输入输出接口明确,上下文依赖可控。
官方数据与冷思考
成本节省的承诺
官网首页直接打出了一个很有冲击力的数字:同等任务,比旗舰模型直跑省下约七成花费。如果这个数据可靠,对于高频使用 AI 编程工具的团队来说,这是一个非常可观的成本优化。
需要保持理性
但必须泼一盆冷水:Duel Agents 目前还处于首批开放申请阶段,产品成熟度需要等真实用户口碑来验证。几个关键问题值得关注:
- 延迟问题:多模型并行竞赛,响应时间是否会显著增加?
- 质检准确性:自动质检层能否可靠地判断代码质量?如果质检本身不靠谱,省下的钱可能会在后续调试中加倍还回来
- 任务拆解的边界:递归拆解在什么粒度下效果最好?过度拆解是否会引入上下文丢失的问题?
关于质检层,这是整个架构中最关键也最脆弱的环节。目前业界主要有三种实现路径:第一种是基于静态分析和测试用例的确定性验证,通过运行预定义的单元测试来判断代码正确性;第二种是使用另一个LLM作为"评审者"(LLM-as-Judge),让模型对生成的代码进行质量评分;第三种是混合方案,结合代码执行结果、类型检查、lint规则和LLM评审。每种方案都有明显的局限性——测试用例无法覆盖所有边界情况,LLM评审本身也可能产生幻觉。Duel Agents的质检层具体采用哪种方案,将直接决定其"省钱不翻车"承诺的可信度。
行业趋势:从"单模型军备竞赛"到"代理编排竞争"
这个项目代表的方向非常值得关注。
过去一年,AI 编程领域的竞争逻辑是参数更大、能力更强、上下文更长。但随着模型能力逐渐趋同,竞争的焦点正在发生转移:不是谁的单个模型最猛,而是谁更会编排一群代理协同工作。
这一趋势的加速有几个关键推动因素。首先是模型能力的"商品化"——当GPT-4o、Claude Sonnet 4、Gemini 2.5 Pro在大多数编码基准测试上的表现差距缩小到个位数百分比时,单纯追求模型性能的边际收益急剧递减。其次是开源小模型的崛起,Qwen、DeepSeek、Llama等开源模型在特定任务上已经能达到闭源旗舰模型80-90%的水平,但成本仅为其十分之一。第三是MCP(Model Context Protocol)等标准化协议的出现,使得不同模型之间的切换和编排变得更加工程化。这三个因素叠加,使得"编排层"从一个可选的优化手段,变成了一个必要的基础设施层。
这和云计算的演进路径很像——早期大家比的是单台服务器的性能,后来比的是分布式调度和资源编排的效率。AI 代理领域可能也会走上类似的道路:
- 模型层继续卷性能
- 编排层负责把合适的任务分配给合适的模型
- 质检层确保输出质量不打折
Duel Agents 虽然还很早期,但它指向的这个方向——让一群代理先打完擂台,再把最值的答案交给你——很可能是 AI 编程工具下一阶段的核心竞争力所在。
对于开发者而言,现在不必急着上车,但值得持续关注这类"代理编排"工具的发展。当产品成熟后,它可能会从根本上改变我们使用 AI 编程助手的方式:从"选一个最贵的模型祈祷它好用",变成"让系统自动帮你找到性价比最优解"。
核心要点
相关推荐
Coze工作流实战:AI一键生成产品宣传视频完整教程
详解Coze工作流搭建产品宣传视频的全流程,整合HappyHours视频模型与即梦生图,12个节点实现从产品图到宣传视频的自动化生成,含九宫格分镜设计、循环查询等核心技巧。

Claude Code入门指南:与传统AI对话的五大核心差异
深度解析Claude Code与ChatGPT等传统AI对话工具的五大核心差异,涵盖交互方式、上下文理解、代码执行力、记忆能力和工具调用,帮助开发者快速了解Claude Code的实际优势与使用场景。

退休金被迫买入AI泡沫股票:纳斯达克规则修改背后的真相
纳斯达克快速入场规则修改后,你的401K和退休基金可能被迫买入SpaceX、OpenAI等AI公司股票。深度解析4万亿美元估值泡沫、AI收益循环的会计游戏,以及普通投资者如何应对集中度风险。