混淆矩阵详解:Precision、Recall与F1分数计算公式及实战应用
详解混淆矩阵及其衍生指标,指导不同业务场景下的分类评估指标选择。
本文从混淆矩阵的TP/TN/FP/FN四个核心概念出发,系统讲解了精度、查准率、查全率、F1分数及Fβ分数等分类评估指标的计算方式与适用场景。核心观点是:不同业务场景应根据误报与漏报的代价差异选择指标——垃圾邮件检测优先Precision,金融风控和癌症筛查优先Recall,综合场景用F1平衡。
引言
回归模型衡量的是预测值与真实值之间的偏差,分类模型衡量的则是分对了多少。那怎样科学地评价一个分类器的好坏?这就需要用到混淆矩阵(Confusion Matrix),以及由它衍生出的精度(Accuracy)、查准率(Precision)、查全率(Recall)和 F1 分数。
本文从混淆矩阵的基本概念出发,逐步拆解每个指标的计算方式,并结合垃圾邮件检测、金融风控、癌症筛查三个真实场景,帮你搞清楚在不同业务背景下到底该盯住哪个指标。
混淆矩阵:分类评估的基石
TP、TN、FP、FN 四个核心概念
混淆矩阵是一个 M×M 的表格(二分类时为 2×2),行表示样本的真实类别,列表示模型预测的类别。二分类场景下有四个关键术语:
- TP(True Positive,真正例):实际为正类,模型也预测为正类。比如 100 只猫中有 90 只被正确识别为猫,则 TP=90。
- TN(True Negative,真负例):实际为负类,模型也预测为负类。比如 100 只狗被正确识别为"不是猫"。
- FP(False Positive,假正例/误报):实际为负类,但模型错误地预测为正类。
- FN(False Negative,假负例/漏报):实际为正类,但模型错误地预测为负类。
一个简单的记忆技巧:第一个字母 T/F 表示预测是否正确,第二个字母 P/N 表示模型给出的预测结果。True Positive 就是"预测正确 + 预测为正",False Positive 就是"预测错误 + 预测为正"。
混淆矩阵的历史渊源与多分类扩展
混淆矩阵的概念最早可追溯到 1904 年 Karl Pearson 在统计学中对分类误差的研究,后来在信号检测理论(Signal Detection Theory)中被系统化。二战期间,雷达操作员需要区分敌机信号和噪声干扰,TP/FP/TN/FN 的框架正是在这一军事背景下被正式确立的——"真正例"对应正确识别的敌机,"假正例"对应把噪声误判为敌机的虚警。
对于多分类问题(如手写数字识别的 0-9 十个类别),混淆矩阵扩展为 M×M 的方阵。对角线上的每个元素表示某一类被正确分类的数量,非对角线元素则揭示了具体的混淆模式——比如数字"3"经常被误认为"8",数字"1"容易和"7"混淆。这种细粒度的错误分析对模型改进极有价值,开发者可以据此针对性地增加易混淆类别的训练样本或调整特征工程策略。
理想的混淆矩阵长什么样
一个优秀分类器的混淆矩阵,对角线元素(TP 和 TN)应该尽可能大,非对角线元素(FP 和 FN)应该尽可能接近零。分对的越多、分错的越少,模型就越好。
核心评估指标及计算公式
精度(Accuracy):最直观但未必最可靠
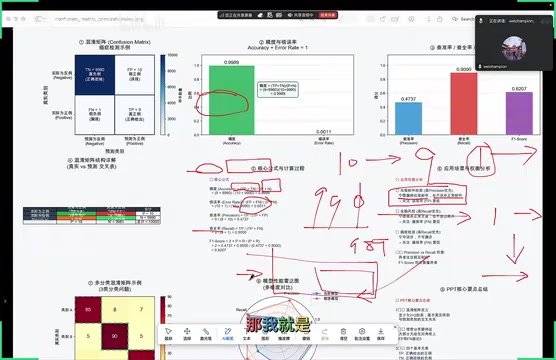
精度的计算公式为:
$$Accuracy = \frac{TP + TN}{P + N}$$
含义很直白:模型预测正确的样本数占总样本数的比例。
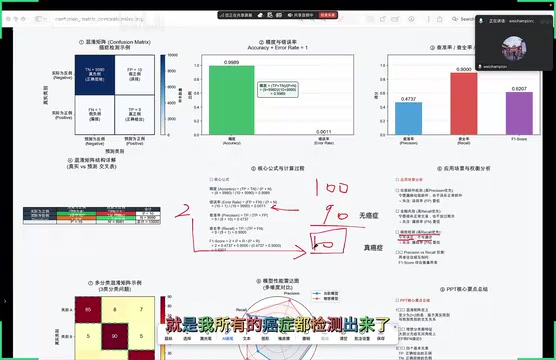
以癌症检测为例,假设有 10000 个案例,其中正确检出和正确排除的加起来为 9989 个,精度就是 9989/10000 = 99.89%。
但精度有一个致命缺陷:在样本严重不均衡时会产生误导。比如癌症筛查中阳性样本极少,模型把所有人都预测为健康,精度照样能达到 99% 以上,可这样的模型没有任何实用价值。
类别不平衡:精度失效的根本原因
类别不平衡(Class Imbalance)是机器学习中最常见的实际挑战之一。在真实数据集中,正负样本比例达到 1:100 甚至 1:10000 并不罕见。例如信用卡欺诈检测中,欺诈交易通常不到总交易量的 0.1%;在网络入侵检测中,恶意流量可能仅占全部流量的万分之一。
面对这种情况,除了选择合适的评估指标外,业界还发展出多种应对策略:过采样技术(如 SMOTE 算法通过在少数类样本之间插值生成合成样本)、欠采样技术(随机减少多数类样本)、代价敏感学习(对不同类型的错误赋予不同的惩罚权重),以及集成方法如 EasyEnsemble 和 BalanceCascade。理解类别不平衡为何让 Accuracy 失效,是掌握分类评估指标的关键前提。
错误率(Error Rate)
错误率与精度互补:
$$Error\ Rate = 1 - Accuracy = \frac{FP + FN}{P + N}$$
即模型预测错误的样本数占总样本数的比例。
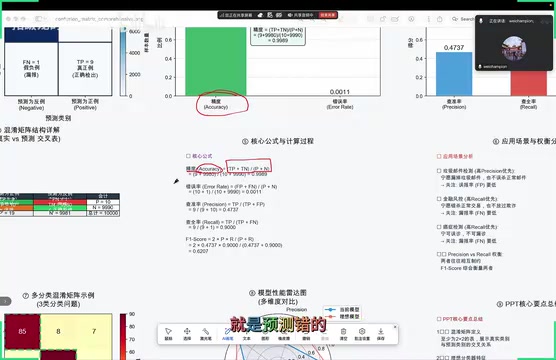
查准率(Precision):衡量误报的关键指标
查准率回答的问题是:模型预测为正类的样本里,有多少是真的正类?
$$Precision = \frac{TP}{TP + FP}$$
举个例子:模型预测了 10 个样本为正类,其中 9 个确实是正类、1 个是误报,查准率就是 9/(9+1) = 90%。查准率越高,说明模型的误报越少。
查全率(Recall):衡量漏报的关键指标
查全率回答的问题是:所有真正的正类样本中,有多少被模型成功找出来了?
$$Recall = \frac{TP}{TP + FN}$$
查全率越高,说明模型的漏报越少。
Precision 和 Recall 的核心区别与权衡关系
查准率和查全率往往存在此消彼长的关系。提高分类阈值,模型会更"谨慎",只在非常有把握时才预测为正类,查准率上升但查全率下降;降低阈值则相反,模型更"激进",查全率上升但查准率下降。
理解这种权衡关系,是选择正确评估指标的前提。
用 PR 曲线和 ROC 曲线可视化权衡关系
查准率和查全率的此消彼长可以通过 PR 曲线(Precision-Recall Curve)和 ROC 曲线(Receiver Operating Characteristic Curve)来直观展示。大多数分类模型输出的并非直接的类别标签,而是一个属于正类的概率值(如逻辑回归输出 0 到 1 之间的概率)。分类阈值(threshold)决定了概率高于多少时判定为正类,默认通常为 0.5,但在实际业务中往往需要根据场景调整。
ROC 曲线以 FPR(假正例率)为横轴、TPR(真正例率,即 Recall)为纵轴,曲线下面积 AUC(Area Under Curve)是一个不受阈值选择影响的综合评估指标——AUC=1 表示完美分类器,AUC=0.5 等同于随机猜测。在类别严重不平衡时,PR 曲线比 ROC 曲线更能反映模型的真实性能,因为 ROC 曲线中的 FPR 会被大量的真负例"稀释",导致模型看起来比实际表现更好。
F1 分数:查准率与查全率的调和平均
F1 分数用于在查准率和查全率之间取得平衡:
$$F1 = \frac{2 \ imes Precision \ imes Recall}{Precision + Recall}$$
只有当查准率和查全率都比较高时,F1 分数才会高。如果其中一个指标极低,F1 分数也会被大幅拉低。它特别适合需要同时兼顾误报和漏报的场景。
Fβ 分数:灵活调节 Precision 与 Recall 的权重
F1 分数实际上是 Fβ 分数在 β=1 时的特例。Fβ 分数的通用公式为:
$$F_\beta = \frac{(1+\beta^2) \ imes Precision \ imes Recall}{\beta^2 \ imes Precision + Recall}$$
当 β>1 时,Recall 的权重更大,适用于漏报代价高的场景;当 β<1 时,Precision 的权重更大,适用于误报代价高的场景。例如在金融风控中,可以使用 F2 分数(β=2)来更强调查全率;在垃圾邮件过滤中,可以使用 F0.5 分数(β=0.5)来更强调查准率。
此外,在多分类场景中,F1 分数还有两种常见的聚合方式:Macro-F1(对每个类别分别计算 F1 后取算术平均,对每个类别一视同仁)和 Micro-F1(先汇总所有类别的 TP/FP/FN 再统一计算 F1,受样本量大的类别主导)。在类别分布不均匀时,两者的差异可能非常显著,选择哪种聚合方式同样需要结合业务需求来判断。
实战场景:不同业务该优先关注哪个指标
理解了公式之后,真正的难点在于:实际业务中到底该优先看哪个指标? 核心判断依据只有一个——误报和漏报,哪个代价更大。
用决策成本矩阵量化业务代价
在实际业务中,选择评估指标的本质是在进行成本收益分析。决策成本矩阵(Cost Matrix)将每种预测结果与具体的经济或社会成本关联起来。以金融风控为例,一笔漏检的欺诈交易可能造成数万元损失,而一次误报仅导致用户多花 30 秒进行身份验证。假设漏报成本为 50000 元,误报成本为 10 元,那么漏报的代价是误报的 5000 倍——这就从定量角度解释了为何必须优先保证高 Recall。
在工业实践中,数据科学家通常会与业务方共同量化这些成本,然后通过最小化期望总成本来确定最优的分类阈值和模型选择策略,而非简单地追求某个单一指标的最大化。这种基于成本的决策框架,让模型评估从"技术指标比较"上升到了"业务价值优化"的层面。
垃圾邮件检测:高 Precision 优先
垃圾邮件过滤的原则是宁可漏报,不可误报。
假设有 990 封正常邮件和 10 封垃圾邮件。漏掉 1 封垃圾邮件,用户最多多看一封无关内容,影响有限。但如果把 1 封正常邮件误判为垃圾邮件丢进垃圾箱,用户可能因此错过重要的业务邮件,后果严重得多。
所以垃圾邮件检测需要高 Precision,确保被标记为垃圾的邮件确实是垃圾。
金融风控:高 Recall 优先
金融风控的策略正好相反:宁可错杀一千,不可放过一个。
假设 1000 笔交易中有 100 笔欺诈和 900 笔正常交易。把几笔正常交易误判为欺诈,最多让用户多做一次身份验证,体验略有下降。但漏掉哪怕一笔真正的欺诈交易,就可能造成巨大的经济损失。
所以金融风控需要高 Recall,把漏报率压到最低。
癌症筛查:宁可误诊不可漏诊
癌症筛查和金融风控类似,同样是高 Recall 优先的典型场景。
假设 100 个病人中有 90 个健康、10 个真正患癌。即使从 90 个健康人中多"误诊"了 2 个疑似病例,后续还可以通过进一步检查排除。但如果 10 个癌症患者中有 4 个被漏诊,这些患者将错过最佳治疗时机,后果不堪设想。
指标选择速查表
| 场景 | 优先指标 | 核心原则 | 推荐 Fβ 参数 |
|---|---|---|---|
| 垃圾邮件检测 | Precision(查准率) | 宁可漏报,不可误报 | F0.5(β=0.5) |
| 金融风控 | Recall(查全率) | 宁可误报,不可漏报 | F2(β=2) |
| 癌症筛查 | Recall(查全率) | 宁可误诊,不可漏诊 | F2(β=2) |
| 综合平衡场景 | F1 Score | 兼顾查准率和查全率 | F1(β=1) |
一条简单的记忆法则:凡是涉及"钱"和"命"的场景,漏报的代价远大于误报,必须优先保证高 Recall。
总结:如何选择正确的分类评估指标
混淆矩阵是分类模型评估的底层工具,由它衍生出的精度、查准率、查全率和 F1 分数各有侧重:
- 精度(Accuracy) 适合样本均衡的常规场景,但在类别不平衡时容易产生误导。
- 查准率(Precision) 关注误报,适合误报代价高的场景,如垃圾邮件过滤。
- 查全率(Recall) 关注漏报,适合漏报代价高的场景,如金融风控、医疗诊断。
- F1 分数在查准率和查全率之间取平衡,适合两者都不能太差的场景。
- Fβ 分数提供了更灵活的权重调节能力,可根据业务中误报与漏报的相对代价选择合适的 β 值。
- AUC-ROC 和 PR 曲线则从全局视角评估模型在不同阈值下的综合表现,是模型选型阶段的重要参考。
没有哪个指标是万能的。选对评估指标,才能在模型调优时做出正确的权衡——这才是分类模型评估的核心价值。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。