Gemini 3.5 Flash登顶Vending Bench性价比前沿
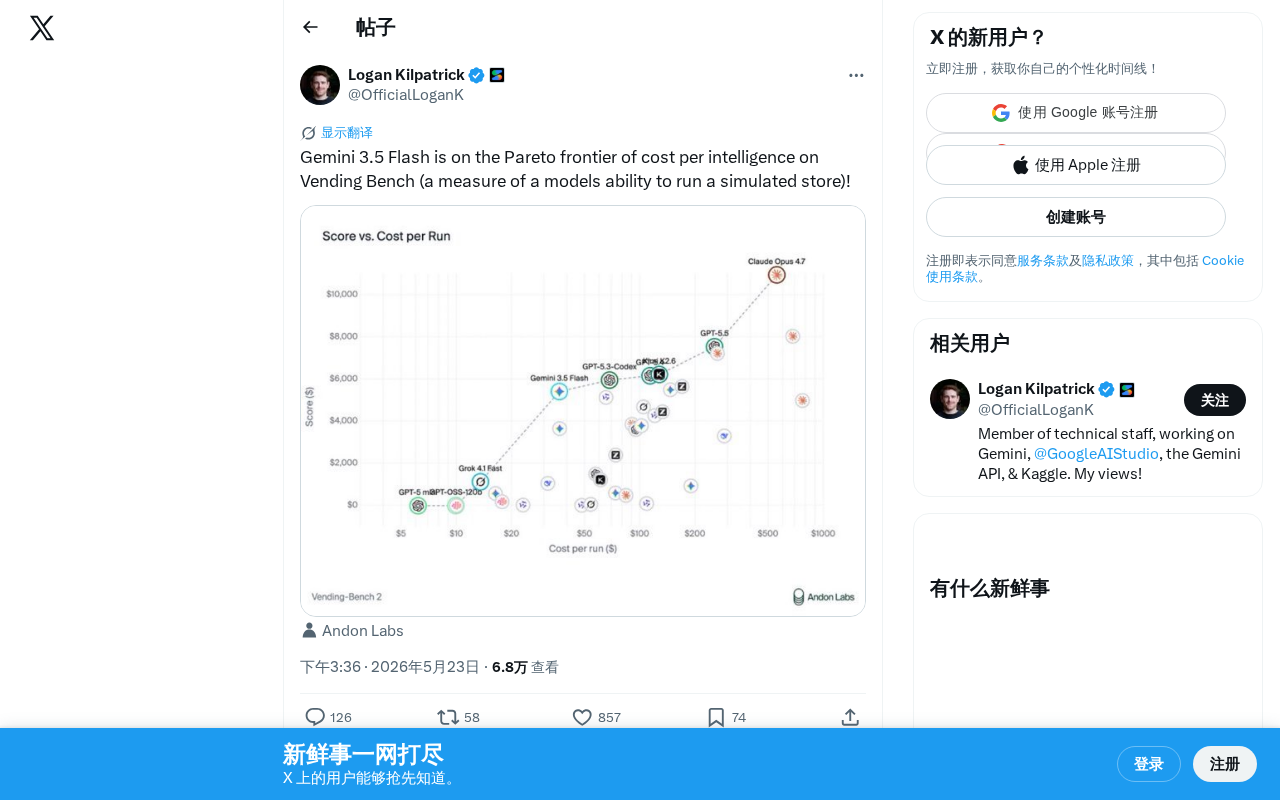
Gemini 3.5 Flash在Vending Bench基准中达到成本-智能帕累托最优
Google发布的Gemini 3.5 Flash模型在模拟商店运营的Vending Bench基准测试中,成功跻身"成本-智能"帕累托前沿,即在同等成本下无其他模型更智能,同等智能下无更便宜选择。这得益于模型蒸馏、稀疏混合专家架构等技术优化,反映了AI行业从纯性能竞争转向性价比竞争的趋势。
Gemini 3.5 Flash在成本效益上达到帕累托最优
Google最新发布的Gemini 3.5 Flash模型在Vending Bench基准测试中表现亮眼,成功跻身"成本-智能"帕累托前沿(Pareto Frontier),展现出极具竞争力的性价比优势。
什么是Vending Bench?
Vending Bench是一个衡量AI模型运营模拟商店能力的基准测试。与传统的学术性基准不同,它模拟了真实世界中的商业运营场景,要求模型具备库存管理、定价策略、客户交互等多维度的综合能力。这类实用性基准越来越受到业界重视,因为它们更能反映模型在实际应用中的表现。
从技术分类上看,Vending Bench属于新一代"Agent Benchmark"(智能体基准测试)的范畴。传统基准如MMLU(大规模多任务语言理解)、HumanEval(代码生成评估)等主要测试模型的知识储备或单一任务能力,而Agent Benchmark则要求模型在一个持续运行的环境中做出连续决策,涉及状态追踪、长期规划和动态响应。Vending Bench模拟的商店运营场景要求模型处理供应链波动、季节性需求变化、竞争对手定价等复杂变量,这与LLM在企业级应用中面临的真实挑战高度一致。这类基准的兴起反映了业界对"模型能做什么"而非"模型知道什么"的关注转向。
帕累托前沿的意义
什么是帕累托前沿?
在多目标优化中,帕累托前沿代表了一组"不可被支配"的最优解——即在不牺牲某一指标的情况下,无法进一步改善另一指标。在这个场景中,两个关键维度是:
- 成本:每次调用的API费用
- 智能水平:模型在Vending Bench上的得分
位于帕累托前沿意味着Gemini 3.5 Flash在同等成本下没有其他模型能提供更高的智能表现,或者在同等智能水平下没有更便宜的选择。
帕累托最优(Pareto Optimality)这一概念源自意大利经济学家维尔弗雷多·帕累托的理论,最初用于描述资源分配的效率状态。在计算机科学中,帕累托前沿广泛应用于多目标优化问题,如芯片设计中功耗与性能的权衡、网络架构中延迟与吞吐量的平衡等。在AI模型评估中,帕累托前沿的引入标志着评估方法论的成熟——单一排行榜已无法满足实际决策需求,开发者需要在多维约束空间中找到最适合自身场景的解。一个模型位于帕累托前沿,意味着它是"非支配解"(non-dominated solution),任何试图在某一维度上超越它的方案,必然在另一维度上付出代价。
对开发者的实际意义
这一结果对于构建AI驱动商业应用的开发者来说意义重大。在实际部署中,成本和性能之间的平衡往往是最关键的决策因素。Gemini 3.5 Flash作为Flash系列的轻量级模型,本身定位就是高性价比方案,此次在实用性基准上的优异表现进一步验证了这一定位。
AI模型的API成本通常按token计费,分为输入token和输出token两个维度。以当前市场为例,GPT-4o的定价约为输入$2.5/百万token、输出$10/百万token,而Flash级模型通常便宜5-10倍。但实际部署成本远不止API调用费用——还需考虑prompt工程的token消耗、重试率(模型失败后重新调用的频率)、以及为弥补模型能力不足而增加的系统复杂度。因此,帕累托前沿分析的价值在于它综合考量了"花多少钱"和"得到多少智能",帮助开发者避免陷入"便宜但需要大量补偿性工程"或"强大但成本不可持续"的陷阱。
Flash系列模型的技术优化
Google的Flash系列模型之所以能实现高性价比,背后依赖多种前沿技术手段。核心策略包括:模型蒸馏(Knowledge Distillation),即用大模型的输出作为训练信号来训练小模型,使其继承大模型的推理模式;稀疏混合专家架构(Sparse Mixture of Experts, SMoE),在推理时只激活部分参数,降低计算开销;以及推理时计算优化(inference-time compute optimization),通过更高效的注意力机制和KV缓存策略减少每次推理的实际算力消耗。这些技术使Flash模型能在参数量和计算成本大幅低于Pro级模型的情况下,保持接近甚至在特定任务上匹配Pro级的表现。
行业趋势:从纯性能竞争到性价比竞争
当前AI模型的竞争已经从单纯追求最高性能,转向了更务实的性价比维度。各大厂商纷纷推出不同规格的模型系列:
- Google的Gemini系列(Pro/Flash/Nano)
- OpenAI的GPT系列(GPT-4o/GPT-4o-mini)
- Anthropic的Claude系列(Opus/Sonnet/Haiku)
在这场竞争中,"Flash"级别的中端模型正成为实际应用中的主力。它们在保持足够智能水平的同时,大幅降低了部署成本,使得更多场景下的AI应用变得经济可行。
各大厂商推出多层级产品线的背后,反映了一种"模型路由"(Model Routing)的架构趋势。在生产环境中,企业越来越多地采用级联策略:简单查询由轻量模型处理,复杂任务升级到重量级模型。这种架构可以将整体成本降低60-80%,同时保持用户体验。OpenAI的ChatGPT产品内部就采用了类似的路由机制。在这种背景下,Flash级模型的性价比表现直接决定了它能承接多大比例的流量,进而影响整个系统的经济可行性。
小结
Gemini 3.5 Flash在Vending Bench上的帕累托最优表现,再次证明了Google在模型效率优化方面的技术实力。对于需要在成本约束下部署AI代理的企业而言,这类兼顾性能与经济性的模型将是最务实的选择。随着更多实用性基准的出现,我们将能更全面地评估各模型在真实商业场景中的综合竞争力。
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。