Gemini Omni视频生成:文本图片视频混合输入一键合成
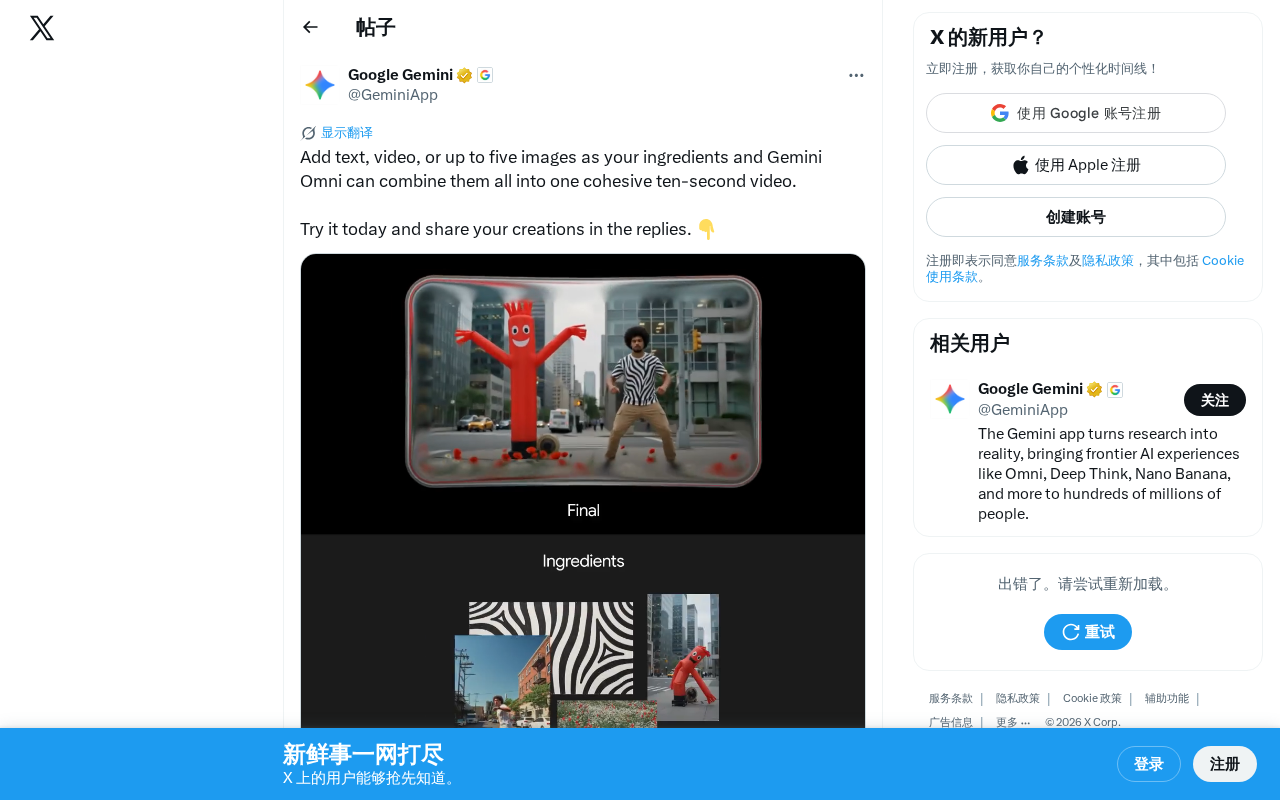
Google Gemini Omni推出多模态混合输入的十秒视频生成功能
Google最新发布的Gemini Omni视频生成功能支持文本、图片(最多五张)和视频的多模态混合输入,一键合成十秒连贯视频。该功能基于原生多模态架构,通过统一Transformer框架实现跨模态语义对齐与内容一致性保持。相比Sora、Runway等竞品,其核心差异在于多模态混合输入的灵活性和平台集成战略,适用于社交媒体创作、商业营销等多种场景。
Google 最新推出的 Gemini Omni 视频生成功能引发广泛关注——用户可以将文本、视频或最多五张图片作为"原料",由 AI 将它们融合为一段连贯的十秒视频。这一功能标志着多模态 AI 视频创作进入了全新阶段。
Gemini Omni功能亮点:多模态输入,一键视频合成
Gemini Omni 视频生成能力最大的亮点在于灵活的多模态输入支持。用户不再局限于单一输入形式,而是可以自由组合以下素材:
- 文本描述:通过自然语言描述想要生成的视频内容
- 图片素材:最多支持五张图片作为视觉参考
- 视频片段:已有的视频素材也可以作为输入
这些不同类型的素材可以混合使用,Gemini Omni 会将它们理解、融合,最终输出一段十秒钟的连贯视频。
多模态大模型的技术演进背景
要理解 Gemini Omni 的意义,首先需要了解多模态大模型(Multimodal Large Language Model,MLLM)的发展脉络。多模态大模型是指能够同时处理文本、图像、音频、视频等多种数据类型的AI系统。早期的AI模型大多是"单模态"的——GPT系列专注于文本,DALL-E专注于图像生成,各自独立运作。2023年前后,随着Transformer架构的进一步泛化和大规模预训练数据集的丰富,研究者开始探索将不同模态统一到同一个模型框架中。
Google的Gemini系列正是这一趋势的代表产物,其设计理念从一开始就是"原生多模态"(natively multimodal),而非将独立模型拼接在一起。这与OpenAI将GPT-4V(视觉理解)和DALL-E(图像生成)分开维护的路线形成了鲜明对比,也是 Gemini Omni 能够实现真正意义上多模态混合输入的根本原因。
技术解析:从单模态到真正的多模态融合
此前主流的 AI 视频生成工具大多只支持"文生视频"或"图生视频"等单一模态输入。Gemini Omni 将多种模态统一到一个生成流程中,这在技术上要求模型具备两项关键能力。
跨模态理解能力
模型必须同时理解文本语义、图像内容和视频时序信息,并在这些不同表征之间建立关联。这正是 Google 在多模态大模型领域持续投入的核心方向。
跨模态理解的核心挑战在于如何将不同类型的数据映射到同一个"语义空间"中进行统一表征。目前主流的技术路径是使用统一的Transformer架构,通过各自的编码器(Encoder)将文本Token、图像Patch和视频帧分别转化为向量表示,再在共享的注意力机制(Attention Mechanism)中进行交互和融合。图像通常被切分为固定大小的图像块(Patch),每个Patch被视为类似文本Token的基本单元;视频则在此基础上增加了时间维度,需要额外的时序编码(Temporal Encoding)来捕捉帧间的动态变化。Google在Gemini的技术报告中披露,其模型在预训练阶段就同时接触了多模态数据,而非先训练语言模型再进行多模态微调,这使得不同模态之间的语义对齐更加深入和自然。
内容一致性保持
将五张可能风格迥异的图片融合为一段"连贯"的视频,要求模型在生成过程中保持视觉风格、主题和叙事的一致性,这对 AI 视频生成质量提出了很高的要求。
当前AI视频生成领域主要存在两大技术路线:基于扩散模型(Diffusion Model)和基于自回归模型(Autoregressive Model)。以Sora、Runway Gen-3为代表的产品主要采用扩散模型路线,其核心思想是从随机噪声出发,通过迭代去噪的过程逐步生成高质量视频帧,并借助时空注意力机制保证帧间的连贯性。Sora还引入了"视频压缩网络"将视频压缩为低维的时空Patch,再在此空间中进行扩散生成,大幅提升了生成效率。内容一致性(Content Consistency)是视频生成中最难攻克的技术难题之一——当输入素材风格迥异时,模型需要在保留各素材核心视觉特征的同时,在色调、光影、运动节奏等维度上进行统一协调,这对模型的语义理解深度和生成控制精度都提出了极高要求。
Gemini Omni视频生成的应用场景
十秒视频虽然时长有限,但在短视频和社交媒体主导的内容生态中,这一功能有着广泛的实用价值:
- 社交媒体内容创作:快速将旅行照片、产品图片等转化为动态视频内容
- 创意表达与故事叙述:用几张关键画面加上文字描述,让 AI 补全中间的过渡和动态效果
- 商业营销素材制作:品牌可以快速将产品图片和宣传文案合成为短视频广告
- 教育与演示:将静态的教学图片转化为更直观的动态演示
竞争格局:AI视频生成赛道日趋白热化
这一功能的发布让 AI 视频生成领域的竞争更加激烈。OpenAI 的 Sora、Runway 的 Gen-3、Pika 等产品都在不断迭代。Google 选择在 Gemini 中直接集成视频生成能力,而非推出独立产品,体现了其"大一统"的多模态战略——让一个模型处理所有模态的输入和输出。
AI视频生成赛道的竞争不仅仅是技术层面的比拼,更折射出各大科技公司截然不同的产品战略。OpenAI将Sora作为独立产品推出,主打极致的生成质量和较长的视频时长(最长支持60秒),目标用户是专业创作者和影视从业者。Runway则深耕创意工具生态,Gen-3在视频编辑和风格控制方面有独特优势,已与多家好莱坞制片公司建立合作。Pika定位于消费级市场,强调易用性和快速生成。Google选择将视频生成能力直接集成进Gemini,背后是其构建"超级AI助手"的平台战略——通过将文本、图像、视频、代码等能力统一在单一入口,提升用户粘性和使用频次,同时也为Google Workspace等企业产品线的AI化升级奠定基础。这种"大一统"路线的风险在于,单一模型需要在多个维度同时保持竞争力,任何一个短板都可能影响整体用户体验。
相比竞品,Gemini Omni 的差异化优势在于多模态混合输入的灵活性。大多数竞品仍以文本提示词为主要输入方式,而 Gemini Omni 允许用户将文本、图片和视频自由组合,既降低了创作门槛,也提供了更丰富的创意控制空间。
总结
从单纯的文本对话到多模态内容生成,Gemini 的能力边界正在快速扩展。十秒视频或许只是一个起点,随着生成质量和时长的持续提升,AI 辅助视频创作有望成为每个人触手可及的工具。目前该功能已经开放使用,感兴趣的用户可以立即体验。
核心要点
- Gemini Omni支持文本、视频和最多五张图片的多模态混合输入,一键生成十秒连贯视频
- 该功能基于"原生多模态"架构,通过统一Transformer框架实现跨模态语义对齐
- 在技术上要求模型具备跨模态理解和内容一致性保持能力,是当前AI视频生成的核心难题
- 应用场景涵盖社交媒体创作、商业营销、教育演示等多个领域
- 相比Sora、Runway等独立产品路线,Gemini Omni的核心差异化在于平台集成战略与多模态混合输入的灵活性
- 该功能已正式开放,用户可立即体验
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。