Gemini Omni视频风格转换:自然语言一键改变视频视觉风格
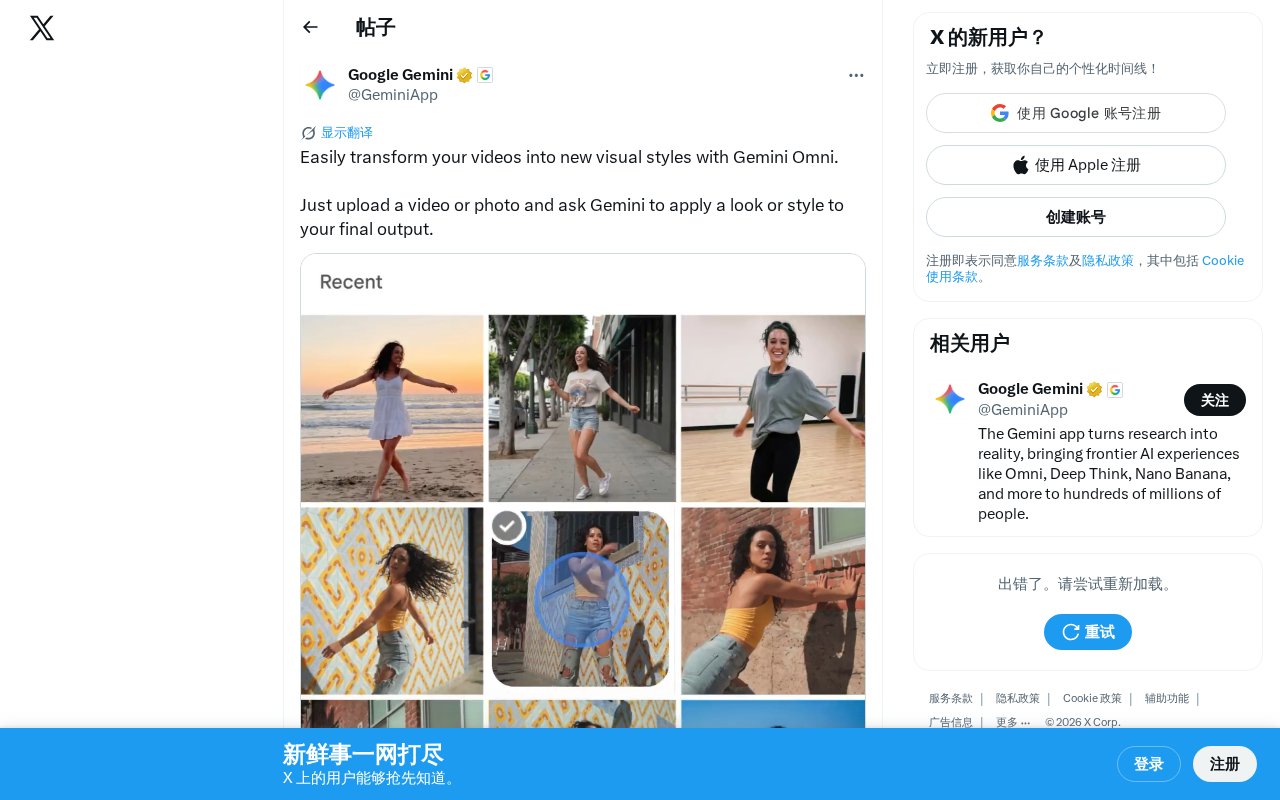
Gemini Omni实现自然语言驱动的视频风格转换,推动AI视频编辑大众化。
Google推出的Gemini Omni模型支持用户通过自然语言描述将视频或照片转换为任意视觉风格。该功能基于原生多模态架构,在统一框架内处理文本、图像和视频,解决了视频风格迁移中的时序一致性等核心难题。这项技术站在神经风格迁移十年积累之上,将视频创作门槛大幅降低,标志着AI视频编辑从工具辅助向意图驱动的范式转变。
Google最新推出的Gemini Omni模型带来了一项令人瞩目的能力——视频风格转换。用户只需上传视频或照片,通过自然语言描述想要的视觉风格,Gemini就能将内容转化为全新的艺术表现形式。这标志着AI视频编辑正在从专业工具走向大众化。
什么是Gemini Omni视频风格转换
Gemini Omni的视频风格转换功能,本质上是将多模态理解与生成能力深度结合的产物。与传统的视频滤镜不同,它不是简单地叠加色彩或纹理效果,而是在理解视频内容语义的基础上,对画面进行整体性的风格重构。
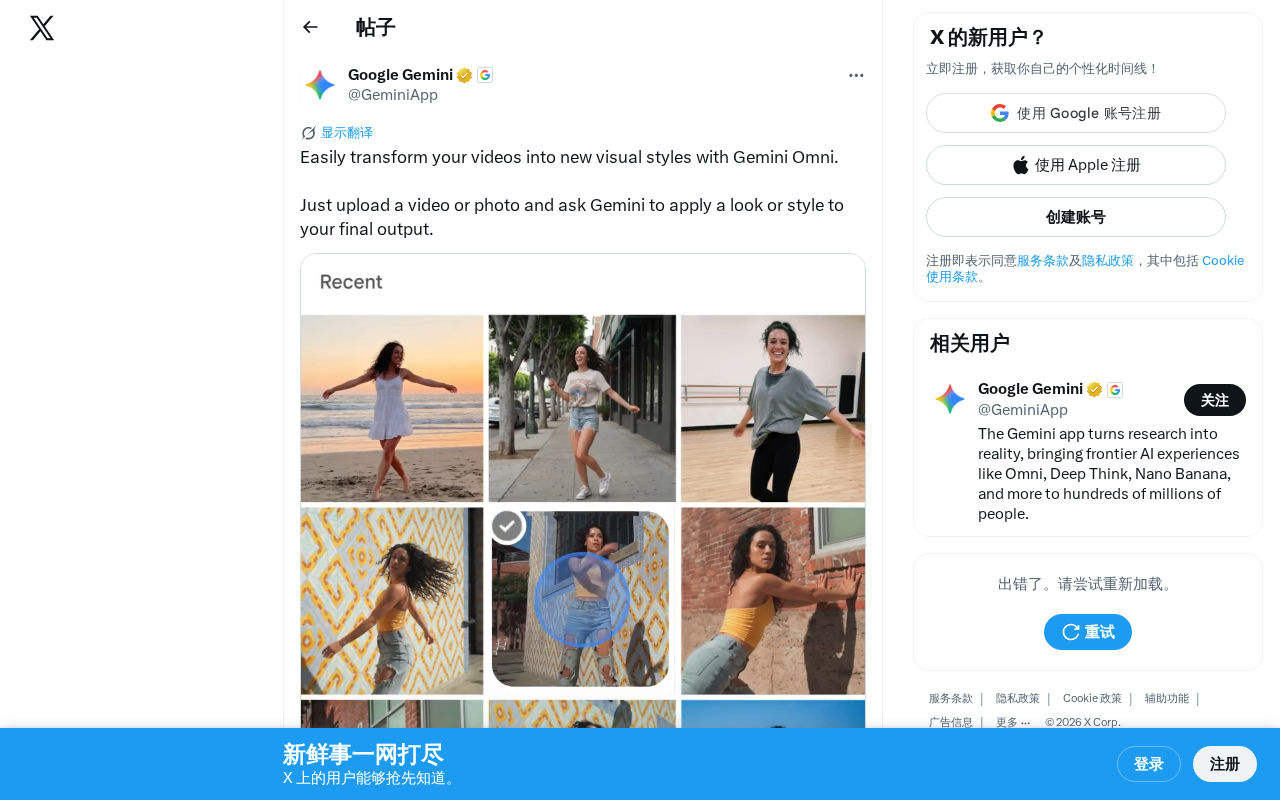
用户的操作流程极其简洁:上传一段视频或一张照片,然后用自然语言告诉Gemini你想要什么样的视觉风格——比如"水彩画风格""赛博朋克风格""吉卜力动画风格"等——Gemini就会将这种风格应用到最终输出中。
技术突破与行业意义
神经风格迁移的十年技术积累
AI风格迁移技术的起点可以追溯到2015年,德国图宾根大学的Leon Gatys等人发表的论文《A Neural Algorithm of Artistic Style》首次证明了卷积神经网络(CNN)能够分离并重组图像的"内容"与"风格"。该方法利用VGG网络不同层级的特征响应——浅层捕捉纹理和笔触,深层编码语义内容——通过梯度下降迭代优化生成图像。然而,这种方法每生成一张图片需要数分钟的迭代计算,无法实时应用。此后,基于前馈网络的方案将速度提升了三个数量级,再到基于GAN(生成对抗网络)的CycleGAN、StyleGAN,以及近年扩散模型(Diffusion Model)的崛起,风格迁移的质量和灵活性才真正达到商业可用的水准。Gemini Omni的视频风格转换正是站在这十年技术积累的肩膀上,将扩散模型的生成能力与大语言模型的语义理解能力深度融合,实现了从"指定参考风格图"到"自然语言描述风格"的交互范式跨越。
从图像风格迁移到视频风格转换的跨越
此前,AI风格迁移主要集中在静态图像领域。将风格迁移扩展到视频面临着巨大的技术挑战,其中最核心的是"时序一致性"(Temporal Consistency)问题。如果对视频的每一帧独立进行风格化处理,即使单帧效果完美,相邻帧之间细微的随机差异也会在播放时产生剧烈的闪烁和抖动,这种现象被称为"时序伪影"(Temporal Artifacts)。
早期的视频风格迁移研究通过光流估计(Optical Flow)来约束相邻帧的像素对应关系,但光流计算在遮挡区域和快速运动场景下容易失效。更现代的方案转向在扩散模型的去噪过程中注入时序注意力机制(Temporal Attention),让模型在生成每一帧时能够"看到"相邻帧的状态,从而在特征空间层面保持一致性。此外,视频风格转换还需要在保留原始运动轨迹的同时重构视觉外观,这要求模型对运动语义有深刻理解——比如人物走路时衣物的飘动、水面的波纹流动——而不仅仅是像素级别的纹理替换。Gemini Omni在这方面的突破,反映了Google在视频生成基础模型(如Lumiere、VideoPoet等前期研究)上多年的技术沉淀。
自然语言驱动的视频创作范式
传统视频风格化工具通常需要用户具备一定的专业知识——了解参数含义、掌握调色技巧、熟悉特效软件的操作逻辑。而Gemini Omni将这一切简化为一句自然语言指令。这种交互方式的变革,意味着视频创作的门槛被大幅降低,任何人都可以成为视觉风格的"导演"。
原生多模态架构:与传统拼接方案的本质差异
Gemini Omni之所以能实现视频风格转换,得益于其原生多模态架构(Native Multimodal Architecture)。理解这一架构的意义,需要先了解业界此前的主流做法:传统的多模态AI系统通常采用"模态对齐"的拼接思路,用独立的视觉编码器(如CLIP的图像编码器)将图像转化为向量表示,再将这些向量"喂给"语言模型处理,最终通过独立的图像解码器生成视觉输出。这种架构的问题在于,视觉信息在转化为语言模型可处理的向量时,不可避免地会损失细粒度的视觉细节,各模块之间的信息传递存在"语义鸿沟"。
原生多模态架构则从训练阶段就将文本、图像、音频、视频等不同模态的数据统一编码到同一个特征空间中。Google DeepMind在Gemini技术报告中明确指出,Gemini系列从设计之初就是多模态原生的,而非在语言模型基础上后期添加视觉能力。这种设计使得模型在理解"吉卜力动画风格"这一文本指令时,能够直接激活与该风格相关的视觉特征表示——柔和的色调、手绘线条的质感、特定的光影处理方式——而无需经过文本到图像的二次翻译,从而实现更精准的风格语义对齐。它不是将视觉理解和生成作为独立模块拼接在一起,而是在统一的模型框架内同时处理文本、图像和视频信息,这种端到端的设计使得模型能够更好地理解用户意图,并生成与之匹配的视觉输出。
Gemini Omni视频风格转换的应用场景
这项功能的潜在应用场景非常广泛:
- 内容创作者:短视频博主可以快速为作品赋予独特的视觉风格,提升内容辨识度
- 品牌营销:企业可以将产品视频转化为不同艺术风格,适配不同平台和受众
- 教育领域:将教学视频转化为动画风格,增强学习趣味性
- 个人用户:将日常拍摄的家庭视频变成艺术作品,增添生活仪式感
竞争格局与未来趋势
视频风格转换并非Google独占的赛道,当前AI视频生成和编辑领域的主要玩家在技术路线上存在明显分野。OpenAI的Sora采用基于Transformer的扩散模型(Diffusion Transformer,DiT),将视频数据表示为时空补丁(Spacetime Patches),核心优势在于从文本生成全新视频,而非对已有视频进行风格化编辑。Runway的Gen系列和Pika则更专注于视频编辑工作流,提供关键帧控制、运动笔刷等精细化操作工具,面向专业创作者群体。Stability AI的Stable Video Diffusion走开源路线,允许开发者在本地部署和定制化微调。
相比之下,Google的策略是将视频能力深度整合进Gemini这一统一的多模态平台,借助Google账户生态和YouTube的内容分发渠道直接触达普通消费者。这种"平台整合"而非"独立产品"的打法,使得Gemini的视频功能能够与搜索、Gmail、Google Docs等产品形成协同效应,构建竞争对手难以复制的生态护城河。从更长远的视角看,视频生成技术的竞争终将从单点能力比拼转向数据飞轮、推理成本和生态整合的综合较量。
从更宏观的视角来看,AI视频编辑正在经历从"工具辅助"到"意图驱动"的范式转变。未来的视频创作可能不再需要复杂的时间线编辑和参数调整,创作者只需要表达清楚"我想要什么",AI就能完成从理解到执行的全部工作。
这不仅是技术的进步,更是创作民主化的又一个里程碑。当技术门槛不再是障碍,真正决定作品质量的将回归到创意本身——而这恰恰是人类最擅长的事情。
核心要点
- Gemini Omni支持通过自然语言指令将视频或照片转换为全新视觉风格,操作门槛极低
- 该功能基于Gemini原生多模态架构,在统一框架内同时处理文本、图像和视频信息,避免了传统拼接方案的语义鸿沟
- 视频风格迁移需要解决帧间时序一致性等核心技术难题,Gemini Omni的突破标志着Google视频生成技术的成熟
- AI风格迁移技术经历了从CNN神经风格迁移、GAN到扩散模型的十年演进,Gemini Omni是这一积累的集中体现
- 应用场景覆盖内容创作、品牌营销、教育等多个领域
- AI视频编辑正从工具辅助向意图驱动的范式转变,推动创作民主化
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。