GitHub Copilot Skill实战:让AI自动遵循你的编码规范

什么是Skill?给AI助手装一份「岗位操作说明」
Skill 是由 Anthropic 提出的一项开放标准,核心思路是:把重复执行的指令写入 .github/skills 目录下的 Markdown 文件,让 GitHub Copilot 能够自动识别并加载这些预定义的规范。
Anthropic 提出 Skill 标准的背景与当前 AI 编程助手面临的「上下文管理」难题密切相关。大语言模型(LLM)的每次调用都有上下文窗口限制(Context Window),即模型单次能处理的最大 Token 数量。即便 Claude 3.5 已支持 200K Token 的上下文窗口,但在实际工程中,频繁携带大段系统提示词仍会导致响应延迟增加和费用攀升。Skill 标准通过将指令模块化存储在文件系统中,让 AI 按需加载而非全量携带,本质上是一种「懒加载」(Lazy Loading)策略在提示工程领域的应用。
简单来说,Skill 就像给 AI 编程助手安装了一份岗位操作说明——它会学会你团队或个人的「专属绝活」。你只需编写一次 Skill 文件,AI 就能在需要时自动按你的规范执行任务。
这样做有两个核心目的:
- 可复用:提示词写一次,反复使用,不用每次重新描述需求
- 省 Token:避免每次对话都携带大段重复指令,显著降低 API 调用成本
关于 Token 消耗,视频作者分享了一个真实数据:仅两天时间就消耗了 65 元(打四折后),涉及 Claude、OpenAI、GitHub Custom 等多个模型。Token 是大语言模型处理文本的基本计量单位——对于中文文本,一个汉字通常被编码为 1-2 个 Token;英文中一个单词约为 1-4 个 Token。主流 API 的定价模型按输入和输出 Token 分别计费,例如 GPT-4o 的输入价格约为每百万 Token 2.5 美元,输出约为每百万 Token 10 美元。在高频开发场景下,如果每次对话都携带 2000-5000 Token 的规范说明,一天 50 次调用就会额外消耗 10-25 万 Token,折合人民币数十元。可见在日常高频使用场景下,Token 优化确实是刚需。
Skill与普通提示词的核心区别
很多开发者会问:把提示词保存下来不就行了?Skill 和普通提示词到底有什么不同?
普通提示词的问题在于「用完即丢」——虽然你可以手动保存提示词文本,但 AI 并不会自动识别和加载它们。每次新对话,你都需要重新粘贴或描述规范。
而 Skill 文件命名为 skill.md,Copilot 会根据文件中的名称和描述自动识别并加载。当你在对话中触发相关场景时,AI 会主动调用对应的 Skill,无需手动干预。
这本质上是为智能体提供了一套标准化、可复用的能力扩展包,让 AI 从「每次都要教」变成「教一次就会」。这种设计理念反映了 AI 工具链从「通用对话」向「专业智能体」(Agent)演进的行业趋势。类似的概念在其他平台也有体现:OpenAI 的 Custom GPTs 通过 Instructions 实现角色定制,Cursor 通过 .cursorrules 文件定义项目规范,Windsurf 则使用 .windsurfrules。Anthropic 将 Skill 定位为「开放标准」,意味着它希望这套文件格式能被多个 IDE 和 AI 工具采纳,形成类似 .editorconfig 或 .eslintrc 那样的跨工具通用配置规范。
环境准备与配置步骤
前置条件
在开始创建 Skill 之前,需要确认以下环境:
- VS Code 版本 ≥ 1.108
- GitHub Copilot 插件更新到最新版本
- 在设置中搜索并勾选相关 Skill 选项(
Ctrl + ,打开设置面板)
创建 Skill 文件的完整流程
操作流程并不复杂:
- 在项目根目录下打开终端
- 执行命令创建
.github/skills目录结构 - 将 Markdown 格式的 Skill 内容写入文件
- 保存后通过
Ctrl + Shift + P调出命令面板,加载 Skill
Skill 文件的核心结构包含两个关键部分:名称和描述(即文件头部的 YAML 元数据)。YAML(YAML Ain't Markup Language)是一种人类可读的数据序列化格式,广泛用于配置文件。在 Skill 文件中,YAML 前置元数据(Front Matter)被包裹在两行 --- 之间,通常包含 name(技能名称)和 description(触发描述)字段。Copilot 的 Skill 匹配机制类似于语义搜索:当用户输入的意图与某个 Skill 的描述在语义空间中足够接近时,系统会自动将该 Skill 的内容注入当前对话上下文。这种机制依赖于嵌入向量(Embedding)的相似度计算,因此描述的措辞直接影响触发的准确率。务必写得清晰准确。
实战演示:创建「注释规范」Skill
下面通过一个实际案例,演示如何创建一个专门用于代码注释的 Skill。
为什么要把注释规范单独做成 Skill?
假设你的项目中已经有了 Android 相关的 Skill,但每次需要添加注释时,AI 会把所有 Skill 内容都读取一遍,造成不必要的 Token 消耗。将注释规范单独抽取为一个 Skill 后,AI 只在需要添加注释时才加载对应规范,既精准又省钱。
创建过程
直接在 Copilot 对话中输入:「写一个 Skill,命名为注释规范,内容为……」,AI 就会自动创建对应的 Skill 文件,并在 .github/skills 目录下新增一个 skill.md。
整个过程中 AI 展现了不错的自主性——它会自己判断文件结构、自动创建目录、甚至在发现格式问题时主动修复。
效果验证
创建完成后,用一段 500 多行的 Python 代码进行测试。输入「检查注释」或「paths.py 加注释」,Copilot 就会按照 Skill 中定义的规范自动添加注释,包括:
- 模块功能描述
- 每个函数/类/方法的文档字符串
- 关键逻辑的行内注释
在 VS Code 的 Copilot 面板中,你可以通过斜杠命令 /run 来运行 Skill,也可以使用「重新加载技能」来刷新当前项目的 Skill 列表。
使用技巧与避坑指南
项目级 Skill vs 全局配置
建议优先使用项目级 Skill,而非全局配置。项目级 Skill 的好处是不同项目可以有不同的规范,比如前端项目和后端项目的注释风格、代码格式要求往往不同,项目级管理更加灵活。
将 Skill 文件放在 .github/skills 目录下的设计选择具有深意。首先,.github 目录是 GitHub 生态的标准配置目录(已有 workflows、ISSUE_TEMPLATE 等约定),将 Skill 放在此处符合开发者的心智模型。其次,由于 Skill 文件随项目代码一起纳入 Git 版本控制,团队成员可以通过 Pull Request 审查和迭代 Skill 内容,实现编码规范的协作治理。这比将规范写在 Wiki 或 Confluence 中更具执行力——规范不再是「建议」,而是 AI 会主动执行的「指令」。
多个 Skill 组合使用
除了注释规范,你还可以创建「格式化代码」等其他 Skill。在 Copilot 的对话窗口中可以同时触发多个 Skill,比如「格式化代码 + 加注释」,一次性完成多项规范化操作。
Skill 描述要足够清晰
实际使用中可能会遇到命令搜索不出来、触发条件缺失、注释添加不完整等问题。这提醒我们:Skill 的名称和描述需要足够清晰准确,否则 AI 可能无法正确识别触发时机,或者执行结果不符合预期。由于 Copilot 的匹配依赖语义相似度计算,建议在描述中明确列出该 Skill 适用的场景关键词,例如「当用户要求添加注释、补充文档字符串、检查注释完整性时触发」,这样能显著提高自动匹配的命中率。
跨工具兼容性
Skill 作为一个开放标准,在 Claude 的开发环境中同样可以使用,但具体操作方式有所不同。这也意味着你编写的 Skill 文件有机会在多个 AI 工具之间复用。随着更多 IDE 和 AI 编程工具采纳这一标准,Skill 文件有望成为团队编码规范的「单一事实来源」(Single Source of Truth),一次编写即可在 VS Code、JetBrains IDE、终端 CLI 工具等多个环境中生效。
总结
GitHub Copilot Skill 本质上是一种将个人或团队编码规范结构化、标准化的方法。它不是什么高深的技术,但在日常开发中能带来实实在在的效率提升:减少重复沟通成本、统一代码风格、节省 Token 开销。
对于经常使用 AI 辅助编程的开发者来说,花 10 分钟为自己的项目配置几个常用 Skill,绝对是一笔划算的投入。建议从最常用的注释规范、代码格式化这类场景入手,逐步积累属于自己团队的 Skill 库。
核心要点
相关推荐
Anthropic投入2500万美元Computer Use积分,AI Agent赋能美国小企业
Anthropic宣布提供2500万美元Computer Use计算积分,支持美国小企业利用AI Agent加速发展。本文解析这一举措背后的战略意图、Computer Use应用场景,以及对AI Agent生态竞争格局的深远影响。
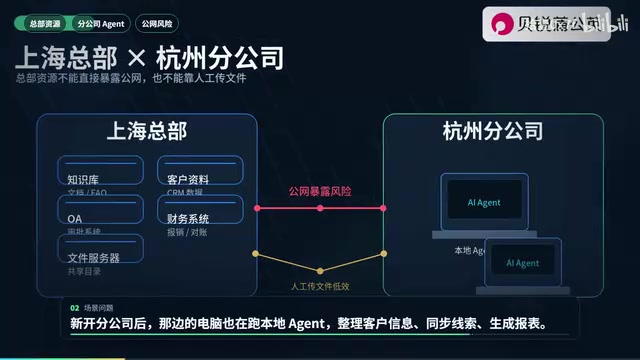
企业AI Agent异地互联:智能组网方案全解析
企业多地部署AI Agent面临网络互通难题。本文解析如何通过智能组网方案,低成本实现异地Agent统一接入总部知识库、OA系统等内部资源,保障Agent稳定高效运行。
AI大模型原理详解:Transformer架构与测试实战指南
深入解析AI大模型核心原理,从Transformer架构到概率推算本质,详解大语言模型在测试领域的应用场景、AI应用测试挑战及应对策略,帮助测试人员快速掌握AI工具与AI测试方法论。