GLM5架构曝光745B参数,DeepSeek V4或先发量化版小模型

GLM5代码泄露揭示745B参数MoE架构,国产大模型加速竞争
GLM5代码泄露显示其采用745B参数MoE架构复现DeepSeek V3设计,疑似此前爆火的Pony Alpha模型。DeepSeek V4传闻将先发布200B量化版,旗舰版或超1T参数。开源生态方面,AI Group开源XCoder编码模型及合成数据集,字节跳动开源超越AlphaFold 3的Protonics生物分子预测模型。国产大模型正进入参数规模竞赛与多领域突破的加速期。
GLM5代码泄露:745B参数复刻DeepSeek架构
近日,网传GLM5已经出现在VLM(视觉语言模型)的最新PR代码中,代码中明确出现了"GLM5"字样,并且在部分技术架构上完全复现了DeepSeek V3的设计。
根据已知信息估算,GLM5的参数量约为745B,激活参数约为44B,参数激活比约为1:17,非常接近DeepSeek V3的1:18.5。这意味着GLM5同样采用了MoE(混合专家)架构——这是一种通过稀疏激活机制大幅提升模型参数规模而不成比例增加计算成本的技术路线。其核心思想是将模型的前馈网络层替换为多个"专家"子网络,每次推理时由一个轻量级的路由器(Router)动态选择少数几个专家参与计算。以DeepSeek V3为例,其总参数671B,但每个Token仅激活约37B参数。这种设计使得模型在训练和推理时的实际算力消耗远低于同等稠密模型,同时保留了大参数量带来的知识容量优势。MoE架构最早由Jacobs等人于1991年提出,近年来随着Google的Switch Transformer、Mixtral等模型的成功落地,已成为超大规模语言模型的主流技术选择。
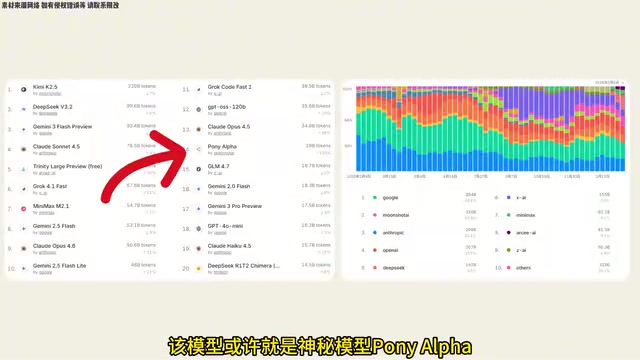
你可能没注意到,该模型很可能就是此前引发热议的神秘模型"Pony Alpha"。这个模型因为表现出较强的能力而突然爆火,甚至带动了一些国产AI厂商的市值上涨,其中智谱涨幅最大。进一步的线索显示,该模型的分词器与GLM4相同,自称"智谱新模型",前端风格也与GLM4极其相似。
春节期间的大模型竞争可谓越来越精彩,国产厂商正在加速追赶甚至对标国际顶尖水平。
DeepSeek V4路线图:量化版先行,旗舰版或超1T参数
另一则重磅消息来自普林斯顿大学人工智能实验室的研究员。据其透露,DeepSeek本月将不会直接发布V4的大版本,而是先发布一个约200B参数的小模型。
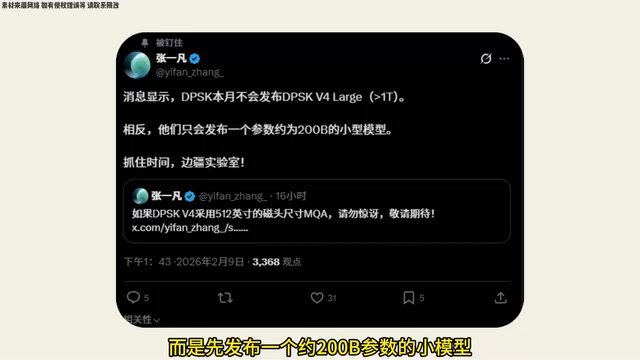
如果消息属实,这意味着DeepSeek V4将包含多个不同尺寸的模型:
- 率先发布的版本:约200B参数的量化版本,定位为轻量级旗舰
- 旗舰版本:参数量或将大于1T(万亿),将是真正的全尺寸模型
这一策略与业界趋势一致——先发布可快速部署的小模型满足市场需求,再推出完整版旗舰模型。不过需要强调的是,该消息未经DeepSeek官方证实,仍需等待正式公告。
从参数规模看国产大模型竞争格局
如果DeepSeek V4旗舰版确实超过1T参数,结合GLM5的745B参数,国产大模型正在进入一个全新的参数规模竞赛阶段。理解这场竞赛需要回到Scaling Law(规模定律)的基本框架——OpenAI于2020年提出的这一理论揭示了模型性能随参数量、训练数据量和计算量的幂律增长规律,奠定了"更大即更强"的行业共识。然而,2022年的Chinchilla定律进一步修正了这一认知:在固定算力预算下,适当缩小模型参数量、增加训练数据量往往能获得更优性能。这也解释了为何MoE架构如此受到青睐——745B参数的GLM5实际推理时仅激活44B参数,其真实计算成本更接近一个中等规模的稠密模型,但知识存储容量却接近全量参数级别。当然,参数量并非衡量模型能力的唯一指标,架构设计、训练数据质量和推理效率同样关键。
Gemini 2.0预览版全端可用
谷歌的Gemini 2.0预览版目前已经在全平台可用,用户可以免费试用。
前几天Gemini 2.0发布以来备受好评,而这款模型被视为谷歌自年底以来的第二款重磅产品。对于普通用户来说,这是一个零成本体验前沿AI能力的好机会。
开源生态持续繁荣
AI Group开源XCoder编码模型
AI Group基于千问(Qwen)38B进行微调,推出了XCoder编码模型,在编码性能上实现了显著提升。更重要的是,团队还同步开源了一个大规模全合成数据集,适用于从零开始训练代码模型。

该数据集的生成方式颇具参考价值:
- 由O3 Mini进行数据合成
- 使用DeepSeek R1和千问3生成解决方案
- XCoder模型本身就是使用该数据集训练而成
这种"用强模型合成数据训练新模型"的范式正在成为开源社区的主流方法论,其本质是一种知识蒸馏的延伸形式,学术界称之为"模型生成数据"(Model-Generated Data)训练。这一范式的兴起源于高质量人工标注数据的获取成本极高,而前沿大模型已具备生成接近人类专家水平答案的能力。其核心逻辑是:强模型作为"教师"生成大量带标注的训练样本,弱模型或专用模型作为"学生"在此数据上微调,从而以较低成本获得较强能力。XCoder的训练范式——由O3 Mini合成问题、DeepSeek R1和千问3生成解决方案——是这一方法论的典型实践,也印证了开源社区正在形成一套可复用的高质量数据生产流水线,大幅降低了高质量训练数据的获取门槛。
字节跳动开源Protonics生物分子结构预测模型
字节跳动开源了Protonics生物分子结构预测模型,该模型在核心能力上超越了AlphaFold 3,并且大幅领先相关领域内的其他模型。
要理解这一突破的意义,需要了解AlphaFold的历史地位。AlphaFold是DeepMind于2020年推出的蛋白质结构预测系统,在CASP14竞赛中以压倒性优势超越传统计算生物学方法,被誉为近50年来生物学领域最重要的突破之一。2022年发布的AlphaFold 2已预测超过2亿种蛋白质结构并全部开源,极大加速了药物研发进程。2024年推出的AlphaFold 3进一步扩展至DNA、RNA及小分子配体的联合结构预测,覆盖了更广泛的生物分子类型。字节跳动的Protonics声称在核心能力上超越AlphaFold 3,意味着其在全原子3D结构预测的精度或覆盖范围上取得了新的突破。
Protonics提供全原子3D结构预测能力,对于药物研发与合成生物学等领域具有重要的推动意义——精确的分子结构预测可将候选药物筛选周期从数年压缩至数周。这也表明,国内科技公司在AI for Science领域的投入正在产出世界级的成果。
总结与展望
从GLM5的架构曝光到DeepSeek V4的路线图传闻,再到开源生态的持续繁荣,国产大模型正在经历一个前所未有的加速期。几个值得关注的趋势:
- MoE架构成为主流:GLM5和DeepSeek都在采用大参数量+稀疏激活的策略,平衡能力与效率
- 多尺寸模型矩阵:厂商不再只发布单一模型,而是构建从轻量到旗舰的完整产品线
- 合成数据驱动训练:用强模型生成训练数据的方法论日趋成熟
- AI for Science突破:生物分子结构预测等垂直领域正在产出超越国际标杆的成果
春节后的大模型市场注定不会平静,让我们静待各家的正式发布。
核心要点
- GLM5代码泄露显示其参数量约745B、激活参数44B,架构复现DeepSeek V3,疑似此前爆火的神秘模型Pony Alpha
- 网传DeepSeek将先发布约200B参数的量化版小模型,旗舰版V4参数量或超1T,但未经官方证实
- AI Group开源XCoder编码模型及大规模全合成数据集,采用O3 Mini合成、DeepSeek R1和千问3生成方案的训练范式
- 字节跳动开源Protonics生物分子结构预测模型,核心能力超越AlphaFold 3
- Gemini 2.0预览版已全平台可用,可免费试用
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。