Gemma 4开源模型本地部署教程:Ollama安装与手机端运行指南
Google 正式发布了旗下最强开源模型 Gemma 4,这是一款专为高级推理和智能体(Agent)设计的开放模型,采用 Apache 2.0 许可证,意味着任何开发者都可以自由地将其用于商业用途。Apache 2.0 是目前开源社区中最宽松的许可证之一,由 Apache 软件基金会维护。与 GPL 等 copyleft 许可证不同,Apache 2.0 允许用户自由使用、修改和分发代码,且不要求衍生作品也必须开源。这意味着企业可以基于 Gemma 4 构建闭源商业产品而无需公开自身代码。此前 Meta 的 LLaMA 系列虽然也号称开源,但其社区许可证对月活超过 7 亿的企业有额外限制,而 Apache 2.0 则完全没有此类约束,这使得 Gemma 4 在商业友好度上具有显著优势。更令人惊喜的是,Gemma 4 最小的版本甚至可以在手机上流畅运行。本文将详细介绍如何使用 Ollama 在本地部署 Gemma 4,以及如何在手机端体验这款模型。
Gemma 4 模型概览:四种规格覆盖全场景
Gemma 4 此次共发布了四种不同规格的模型:1.2B、1.4B、26B 和 31B。其中 B 代表 Billion(十亿),即模型的参数数量。参数量是衡量大语言模型规模的核心指标——参数量越大,模型理论上能学习到的知识和模式越丰富,但同时也需要更多的计算资源和显存。然而近年来,通过改进训练数据质量、优化模型架构(如 Mixture of Experts 混合专家架构)和训练策略,小参数模型也能逼近甚至超越大参数模型的表现,这一趋势被称为"Scaling Law 的效率突破"。Gemma 4 正是这一趋势的典型代表。其中 1.2B 和 1.4B 属于轻量级版本,可以完整地在手机上运行;而旗舰版 31B 则展现出了令人惊叹的性能表现。
从公开的评测数据来看,Gemma 4 31B 的综合能力评分达到了 11,452 分,在同级别模型中处于领先地位。它不仅碾压了智谱 GLM、DeepSeek V3.2 等同参数量级的模型,甚至与参数量远超自身的 Gemini 5、Kimi 2.5 等大模型不相上下。
要知道,Gemini 5 和 Kimi 2.5 的参数量比 Gemma 4 31B 大了许多倍,而 Gemma 4 却能在普通家用显卡(约 50T 算力)上正常运行,这种"以小博大"的能力让它的可玩性极强。在整体能力排行榜上,Gemma 4 31B 排名前 27 位,领先于 Gemma 2.5 Pro、OPS 4.1 等众多知名模型。
免费体验 Gemma 4 的几种方式
在动手部署之前,如果你只是想快速体验 Gemma 4 的能力,可以直接访问 Google 的 AI Studio 平台。只需注册一个账号,选择 Gemma 4 模型即可免费在线提问。
不过在线体验毕竟受限于网络和调用次数,接下来重点介绍如何在本地环境和手机端运行 Gemma 4。
使用 Ollama 本地部署 Gemma 4 31B
环境准备与安装
Ollama 是一款专为本地运行大语言模型设计的开源工具,它极大地简化了模型部署流程。传统上,在本地运行 LLM 需要手动配置 Python 环境、安装 PyTorch、下载模型权重、编写推理脚本等繁琐步骤,而 Ollama 将这一切封装为类似 Docker 的体验——一条命令即可完成模型的下载、量化和运行。Ollama 底层基于 llama.cpp 构建,支持 GGUF 格式的量化模型,能够充分利用 GPU 加速(支持 NVIDIA CUDA、Apple Metal 和 AMD ROCm),同时也支持纯 CPU 推理,使得没有独立显卡的用户也能运行较小的模型。
本次演示使用的是腾讯 Cloud Studio 提供的免费云环境(每天赠送一定工时),配置为 GPU A10,显存约 20GB。当然,如果你自己的电脑显卡显存达到 20GB 左右,完全可以在本地完成同样的操作。
Ollama 安装步骤:
- 访问 Ollama 官网,根据你的操作系统(Windows/macOS/Linux)选择对应的安装命令
- 一键执行安装命令即可完成安装
- 安装完毕后,后续的模型管理命令在所有平台上都是一致的
下载与运行模型
安装好 Ollama 后,运行 Gemma 4 只需要一条命令:
ollama run gemma4:31b
执行后 Ollama 会自动下载并加载模型。在 Ollama 的模型库中,Gemma 4 提供了以下几个版本供选择:
| 参数规格 | 模型大小 | 适用场景 |
|---|---|---|
| 1.2B | 约 7.2GB | 手机端运行 |
| 1.4B | 约 9.6GB | 手机端运行 |
| 26B | 约 18GB | 桌面端运行 |
| 31B | 约 20GB | 桌面端运行 |
这里需要解释一下为什么 31B 参数的模型只需要约 20GB 的存储空间和显存。这得益于**量化(Quantization)**技术——一种模型压缩方法,通过降低权重的数值精度来减少内存占用和计算量。以 FP16(半精度浮点数)为例,每个参数占用 2 字节,31B 参数的模型理论上需要约 62GB 显存。而 Ollama 默认使用 Q4_K_M 等量化方案,将每个参数压缩到约 4-5 比特,从而将显存需求降低到约 20GB。虽然量化会带来微小的精度损失,但在实际使用中几乎不影响用户体验。常见的量化级别包括 Q8(8比特)、Q4(4比特)和 Q2(2比特),精度依次递减但压缩率依次提高。
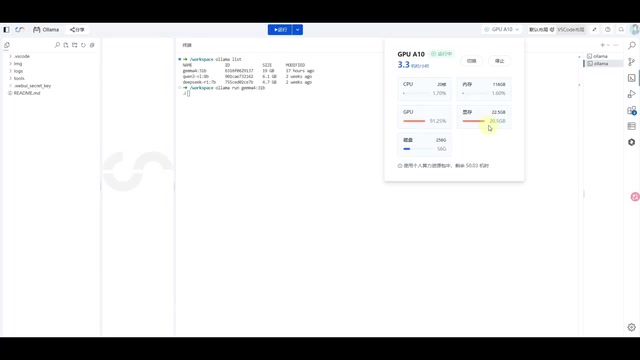
实测 31B 模型加载后,GPU 显存占用约 20.5GB,GPU 利用率约 91%。这意味着只要你的显卡显存在 20GB 以上(如 RTX 3090、RTX 4090 等),就可以无压力地在本地运行这个旗舰模型。
实际能力测试
Gemma 4 31B 默认开启了思考模式(Think),会展示内部推理过程。思考模式是近年来大语言模型领域的重要突破,其核心思想源自 OpenAI 的 o1 模型所推广的"链式思维推理"(Chain-of-Thought Reasoning)。在传统模式下,模型直接输出最终答案;而在思考模式下,模型会先生成一段内部推理过程,逐步分析问题、考虑不同可能性,然后再给出最终答案。这种方式显著提升了模型在数学、逻辑推理、编程等需要多步骤思考的任务上的表现。Gemma 4 默认开启思考模式,用户可以看到模型的推理链条,这不仅提高了答案质量,也增强了可解释性。
以下是两个经典测试:
测试一:洗车问题——"我想去洗车,应该怎么去?"这个看似简单的问题考验的是模型的常识推理能力。Gemma 4 准确回答"应该开车过去",因为你的目的是洗车,走过去的话车怎么洗呢?这与 DeepSeek V3.2 的回答基本一致。
测试二:竹竿过门问题——一根长竹竿能否通过一扇窄门?Gemma 4 给出了堪称满分的回答:从几何学角度来看不能直接通过,但从实际操作角度来看,将竹竿横着(顺着门的方向)就可以正常通过。模型同时从逻辑学和实际操作两个维度给出了分析,展现了出色的推理能力。
值得强调的是,DeepSeek V3.2 的参数量远超 Gemma 4 31B,但两者在这些推理任务上的表现几乎相当,这充分说明了 Gemma 4 的"性价比"之高。作为本地备用模型,它的能力完全够用。
手机端运行 Gemma 4:支持工具调用
Google 专门发布了一款名为 Google AI Edge Gallery 的 Android 应用,可以在 Google Play 上免费下载。Google AI Edge Gallery 基于 Google 的 AI Edge SDK 构建,专注于端侧推理(On-device Inference)——即直接在用户设备上运行 AI 模型,而非将数据发送到云端处理。这种方式有三大核心优势:一是隐私保护,用户数据完全不离开设备;二是低延迟,无需网络往返时间;三是离线可用,即使没有网络连接也能正常使用。现代智能手机的 SoC(如高通骁龙 8 Gen 3、联发科天玑 9400)通常集成了专用的 NPU(神经网络处理单元),可以高效执行量化后的小型模型推理任务。
安装与配置
下载安装 Google AI Edge Gallery 后,进入应用可以看到 Agent SQL 等功能入口,明确标注了 Gemma 4 的支持。应用中提供了 1.2B 和 1.4B 两个适合手机端运行的模型版本,经过量化处理后模型大小仅为 2.5GB 和 3.6GB。
实测在小米 15 Pro 上选择 GPU 模式运行,Gemma 4 1.2B 可以流畅运行,没有任何问题。
工具调用(Tool Use)演示
手机端的 Gemma 4 最大亮点在于支持工具调用(Tool Use),这在如此轻量级的模型上实属难得。工具调用(也称 Function Calling)是实现 AI 智能体(Agent)的关键能力之一。传统的大语言模型只能基于训练数据生成文本,无法获取实时信息或执行实际操作。而具备工具调用能力的模型可以识别用户意图,自动决定是否需要调用外部工具(如搜索引擎、数据库、API 等),生成符合工具接口规范的结构化调用请求,接收工具返回的结果后再整合为自然语言回答。这一能力的实现通常需要在训练阶段加入大量的工具调用示例数据,让模型学会何时调用、调用哪个工具以及如何解析返回结果。Gemma 4 在仅 1.2B 参数的轻量版本上就支持工具调用,这在业界是相当罕见的,说明 Google 在训练数据和模型架构上做了针对性优化。
内置的工具包括:
- 维基百科查询:可以实时搜索维基百科获取信息
- 邮件发送:支持调用邮件功能
- 文本转换:各类文本处理工具
- 自定义工具:支持通过右上角"+"按钮导入本地或第三方工具
实测让 Gemma 4 "从维基百科查找李小龙的信息",模型成功自动调用了维基百科工具,准确返回了李小龙 1940 年出生于美国旧金山、1973 年去世等关键信息。
此外,手机端的 Gemma 4 还支持图片和音频输入,是一个真正的全模态模型。结合工具调用能力,它完全可以作为个人 AI 智能体的后端引擎使用。如果在 Mac mini M4 等设备上运行,更是毫无压力。
总结与建议
Gemma 4 的发布标志着开源模型进入了一个新阶段——小参数量、高性能、全功能。31B 的旗舰版本用 20GB 显存就能运行,却能媲美参数量大数倍的闭源模型;1.2B 的轻量版本甚至能在手机上运行并支持工具调用。
对于开发者而言,Apache 2.0 的开源许可意味着零门槛的商业化可能。无论是作为本地备用模型、手机端 AI 助手,还是智能体应用的后端引擎,Gemma 4 都是当前最值得关注的开源选择之一。
核心要点
相关推荐
AI Agent智能体系统学习路径:从零基础到独立开发
系统梳理AI Agent智能体的完整学习路径,涵盖基础原理、Prompt工程、RAG知识库、多Agent协作等核心技术,附带实战项目指南,帮助零基础学习者高效掌握Agent开发能力。
Kimi K2.7接入Hermes Agent实测:一句话生成完整应用
实测Kimi K2.7接入Hermes Agent智能体系统,展示一句话生成3D游戏、网页操作系统等完整应用的全流程,对比Claude 3.5基准测试数据,解析智能体团队协作与自纠错机制。
用Lovable一句话生成个人网站:零代码免费上线指南
详解如何用Lovable AI建站工具,通过一句话Prompt生成专业个人网站并免费发布上线。涵盖完整实操流程:编写Prompt、AI自动生成、对话式迭代微调到一键部署,零代码基础也能轻松搭建作品集展示页。